LinkedIn Connections Analyzer
1.0.0
セレンと美しいスープライブラリを使用してPythonでWebスクレイピングスクリプトを設計して、ユーザーのすべてのLinkedIn接続の情報を抽出し、収集されたデータを変換し、合成データで基本データ分析を実行しました。次に、Dash Frameworkを使用してWebアプリケーションダッシュボードを開発し、分析の結果を提示しました。上記で観察できるように、プロジェクトは3つの部分に分かれています。
セレンと美しいスープライブラリを使用して、Webスクレイピングを実行して、LinkedInユーザーのプロファイルから情報を抽出しました。使用する3つの方法:Login、Connections_Scraper、およびprofile_scraper。これらは、Connections_Data、教育、経験の3つのデータフレームに分けられました。
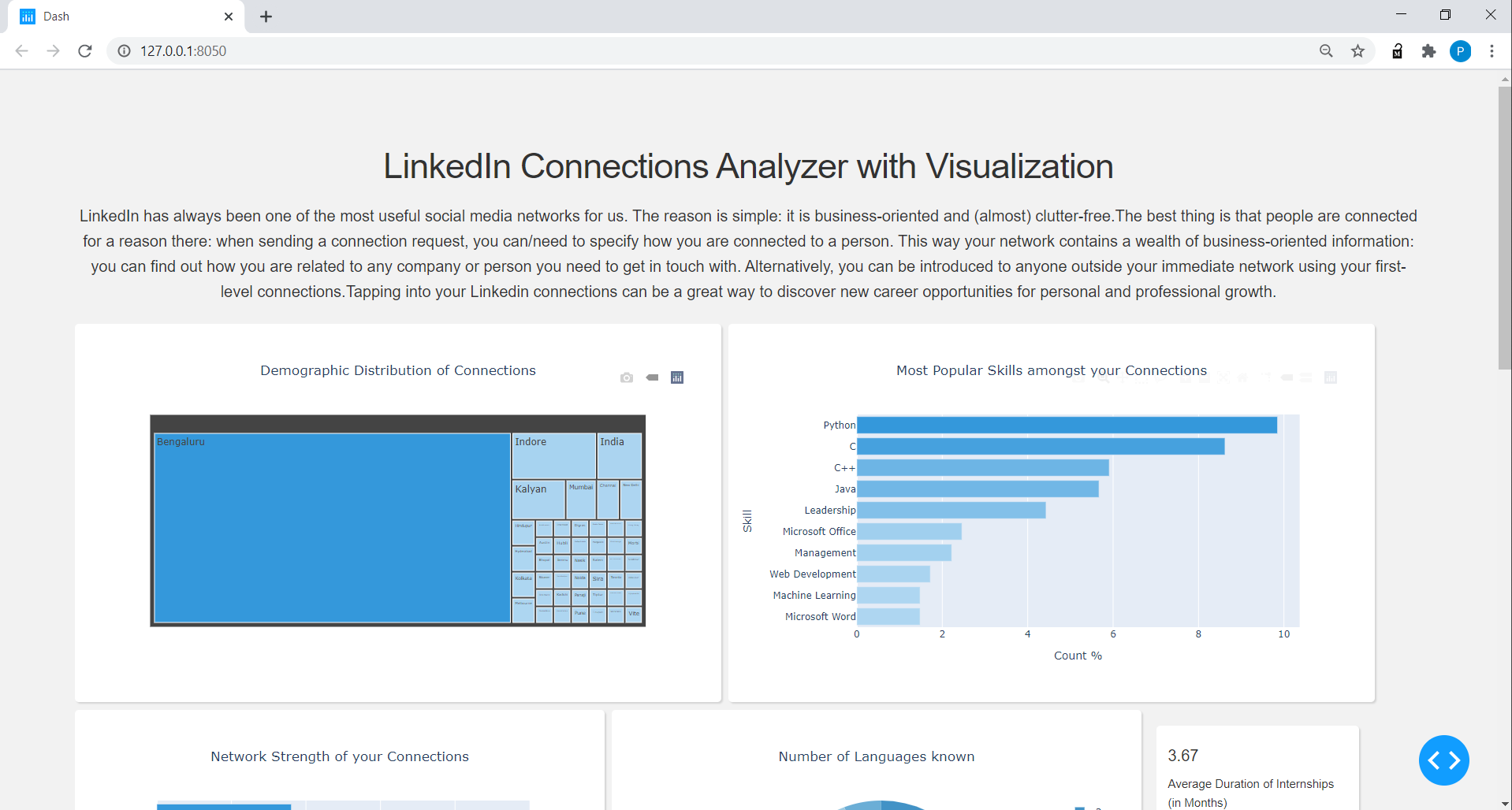
connections_data:抽出された名前、タイトル、場所、プロファイル、接続数、プロジェクト数、既知の言語数、Connections_dataのトップスキル。
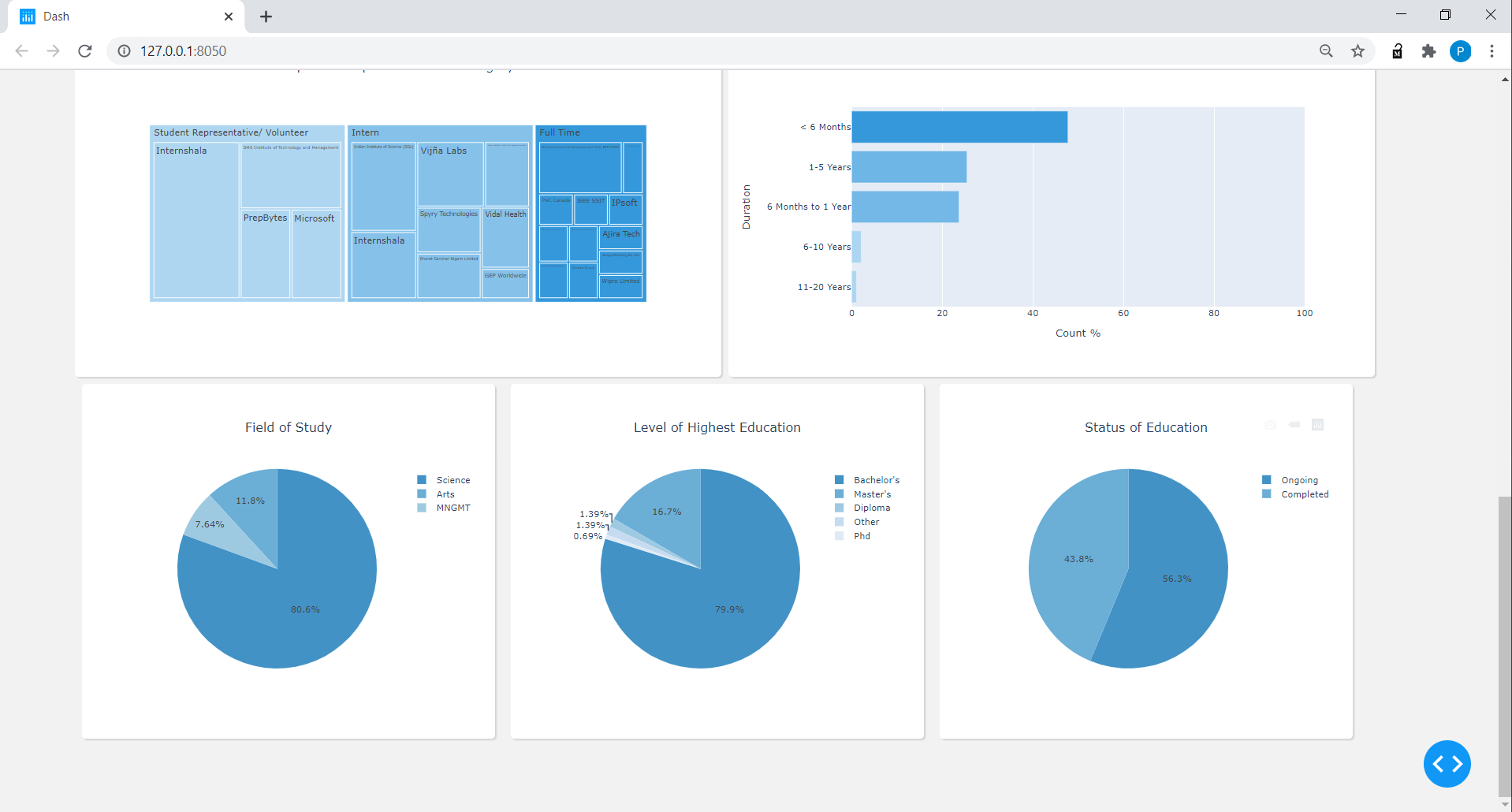
教育:抽出された研究所、教育のための学位と年の範囲。
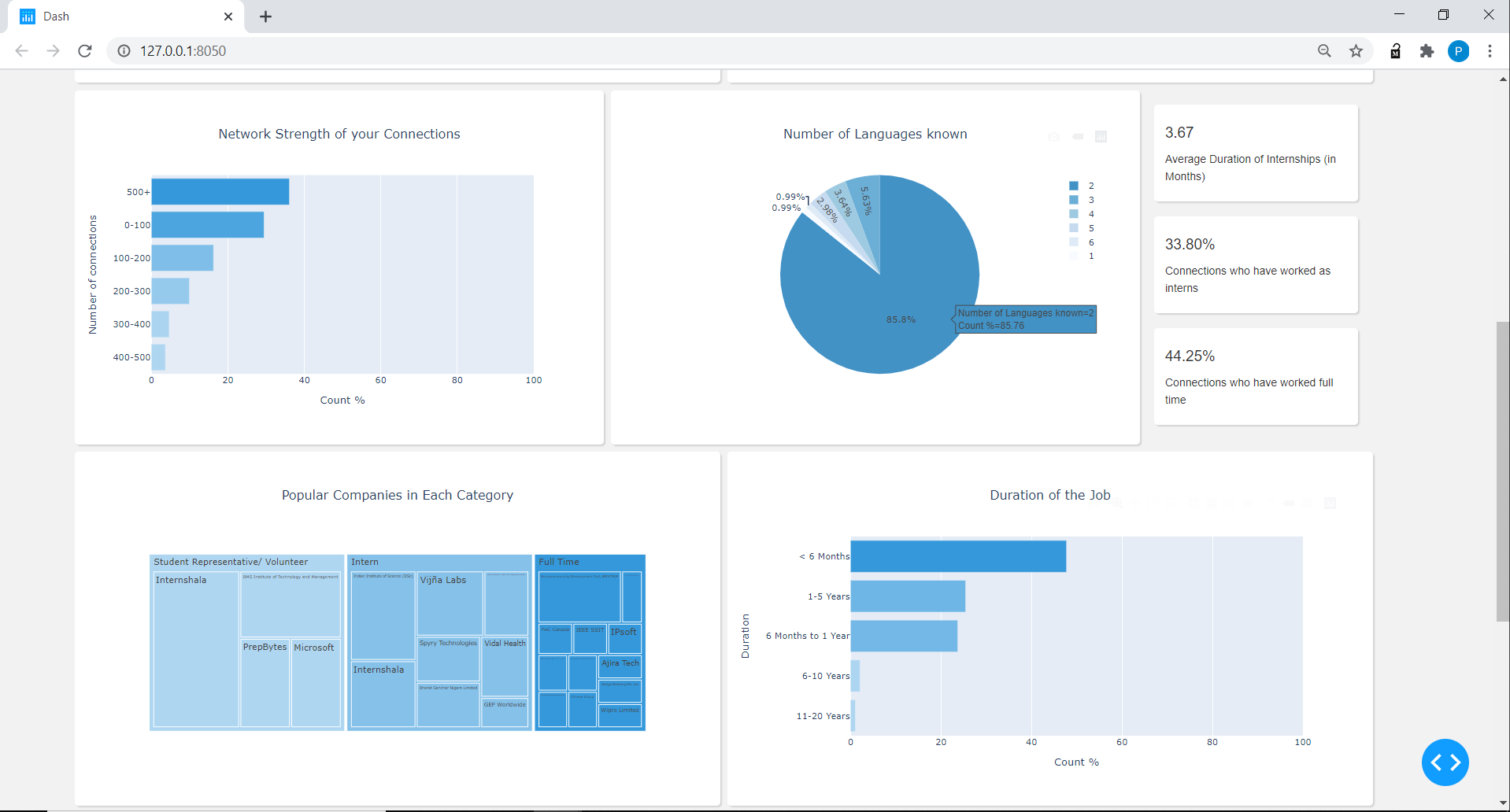
経験:抽出されたプロファイル、ポジション、会社、エクスペリエンスデータフレームの期間。
収集されたデータは生の形式であり、分析して洞察を得るためにクリーニングして変換する必要がありました。つまり、Connections_Data、経験、教育の3つのデータフレームがあります。
Connections_Data DataFrameの場合、「エリア」などの単語なしで都市名を表示するためにロケーション列をクリーニングし、接続の数を0-100、100-200、... 500+、言語数、プロジェクトの数に分割し、それぞれの接続数の上位3フィーチャースキルの辞書を作成しました。
教育データフレームの場合、研究所と学位名に基づいて、研究分野を3つのカテゴリに分類しました(当面のために、簡単にするため):科学、管理、芸術は、特定の教育レベルのプロファイルで提供される年間範囲に基づいて教育の状態を見つけました。また、プロフィール上の教育分野で「独身者」、「マスター」などの言葉に基づいて、つながりの最高レベルの教育が見つかりました。
Experience DataFrameの場合、ポジションコラムを3つのカテゴリに分割しました:フルタイム、インターン、学生の代表者、またはボランティアは、6か月未満から20年以上で始まる期間列の下で6つのカテゴリを作成しました。
Dashは、MLおよびData Science Webアプリを構築するための最もダウンロードされた信頼できるフレームワークです。通常、フロントエンド、バックエンド、およびDev Opsチームを必要とするフルスタックアプリは、DASHを使用してデータサイエンティストが数時間で構築および展開できるようになりました。 Dash Open Sourceを使用すると、Dashアプリは地元のラップトップやワークステーションで実行されますが、組織内の他の人が簡単にアクセスすることはできません。詳細を読んでDashを理解するには、https://plotly.com/dash/にアクセスしてください
PlotlyのPythonグラフライブラリは、インタラクティブな出版品質のグラフを作成します。 plotly.Expressモジュール(通常はPXとしてインポート)には、一度に全体の図を作成できる関数が含まれており、Plotly ExpressまたはPXと呼ばれます。 Plotly Expressは、Plotly Libraryの組み込みの一部であり、最も一般的な数字を作成するための推奨開始点です。 Plotlyの詳細については、https://plotly.com/python/をご覧ください
Dashを使用したのはこれが初めてであるため、ダッシュボードはかなりシンプルに見えます(タイルとツリーマップを備えたインタラクティブなバーチャートとパイチャートで構成されています)が、非常に有益です。後で研究/仕事のレベルまたは分野の複雑さに関して、より多くの変更を組み込む予定です。
注:邪悪な目的で必要なため、アプリケーションを実装するのと同じフォルダーにアセットフォルダーを配置することが重要です。