LangGraphRAG
1.0.0
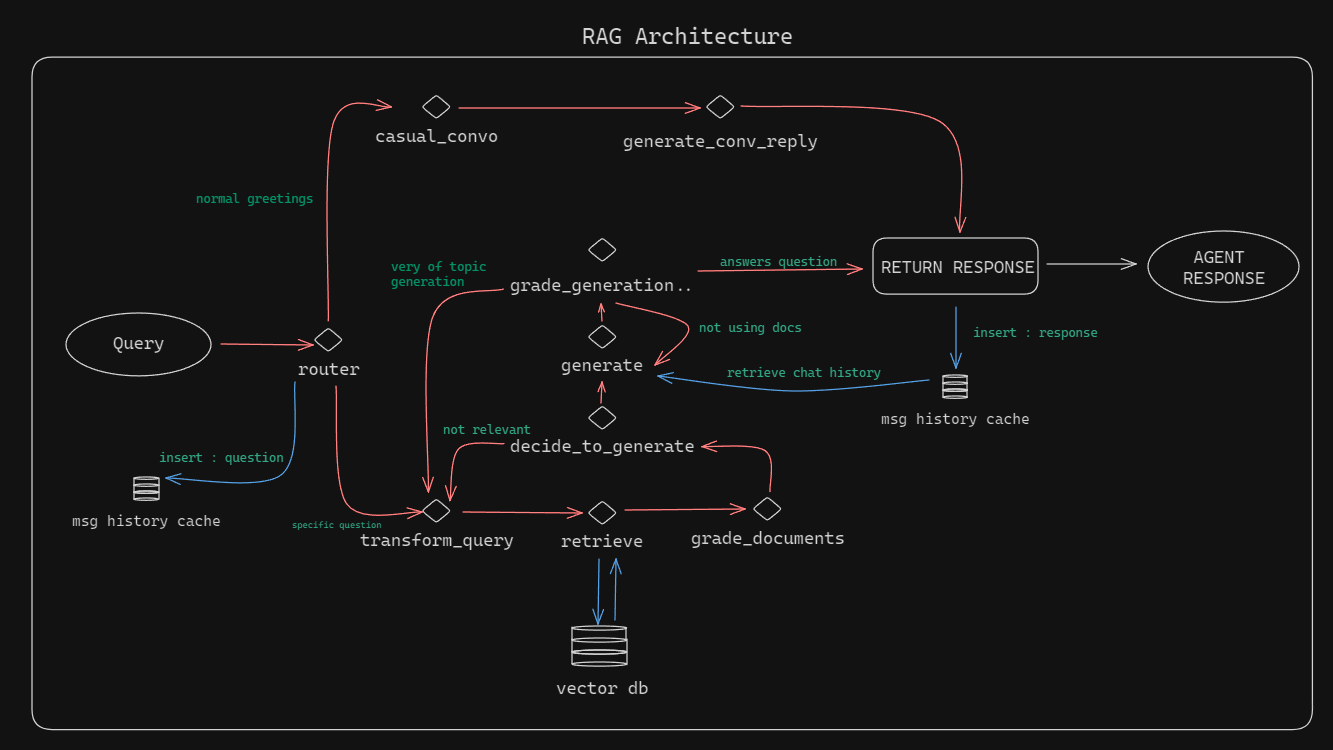
Langgraphrag est un système de génération (RAG) de récupération basé sur un terminal implémenté à l'aide de Langgraph. L'architecture est conçue pour gérer les requêtes en les acheminant à travers une série de processus impliquant la mise en cache de l'historique des messages, la transformation des requêtes et la récupération de documents à partir d'une base de données vectorielle.
Le projet est divisé en plusieurs modules, chacun responsable de fonctionnalités spécifiques:
Suivez ces étapes pour configurer et exécuter le projet:
Clone le référentiel :
git clone https://github.com/ranguy9304/LangGraphRAG.git
cd LangGraphRAGCréer un environnement virtuel :
python3.12 -m venv venv
source venv/bin/activate # On Windows use `venvScriptsactivate`Installez les exigences :
pip install -r requirements.txt
choco install wkhtmltopdfConfigurer les variables d'environnement :
cp .env.example .env.env pour ajouter votre clé GPT: OPENAI_API_KEY = your_gpt_key_here URLS = url1,url2GET_WEB_PAGES_TO_PDF sur true si le téléchargement des pages Web d'autre est false: GET_WEB_PAGES_TO_PDF = False
CONVERT_PDF_TO_MD sur true si déjà pdf else false: CONVERT_PDF_TO_MD = True
INTERMEDIATE_PDF_DIRDATA_DIRDocuments de configuration : à partir de l'exécution du répertoire racine
python modules/processDocs.pyCela met en place les pages Web et les documents. N'oubliez pas de modifier les paramètres de traitement des documents dans .env selon vos besoins.
Exécutez le programme principal :
python main.py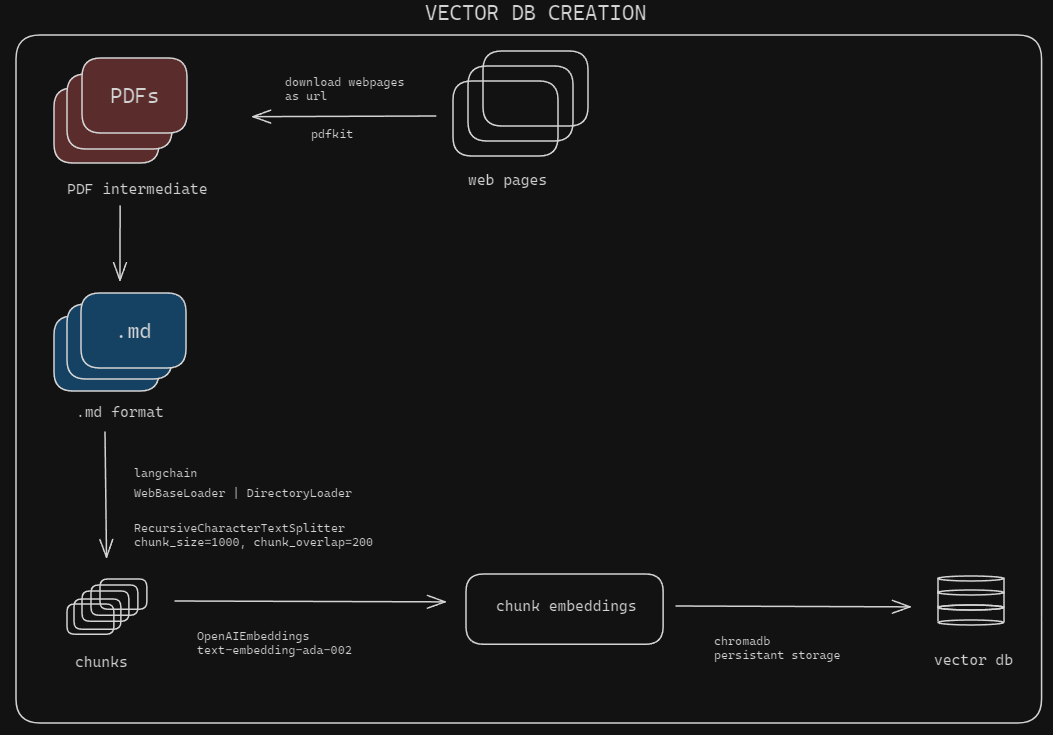
N'hésitez pas à alimenter le référentiel et à soumettre des demandes de traction. Pour les modifications majeures, veuillez ouvrir un problème pour discuter de ce que vous aimeriez changer.
Mit


