LangGraphRAG
1.0.0
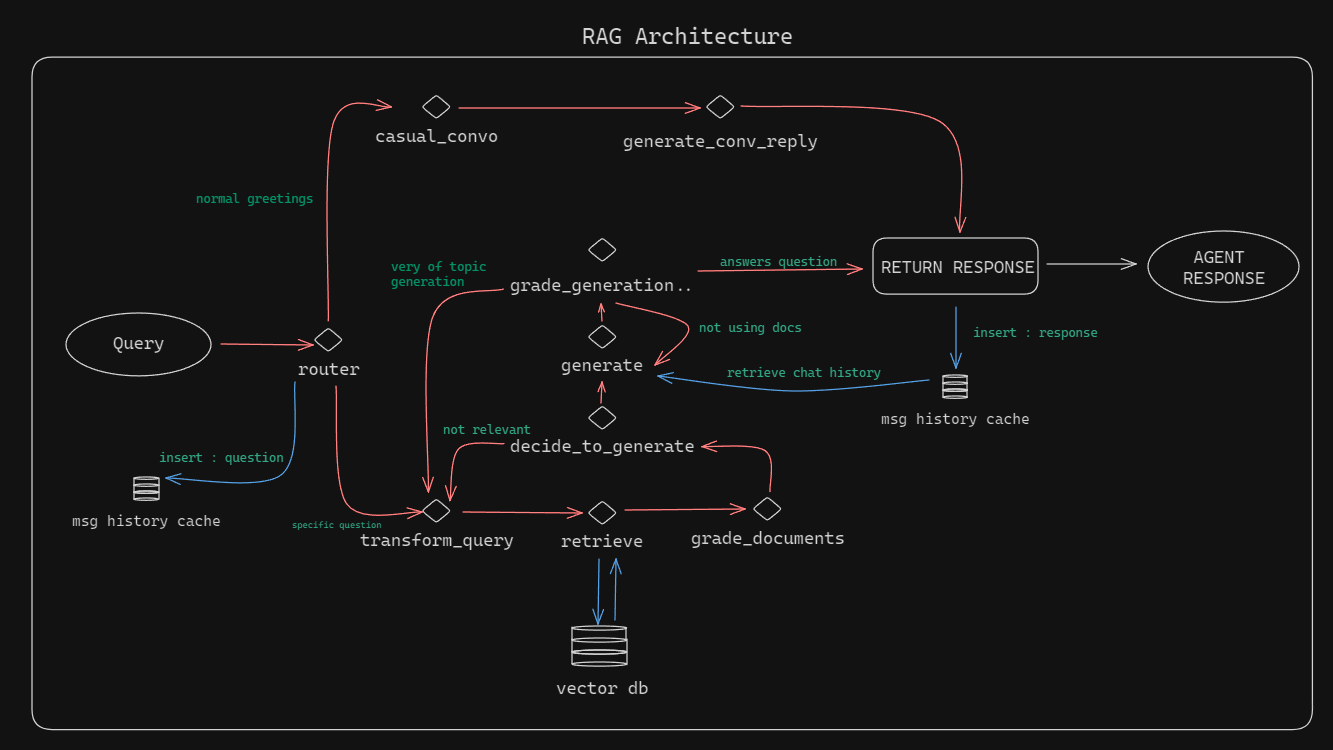
Langgragg es un sistema de generación de recuperación (RAG) basado en la terminal implementado con Langgraph. La arquitectura está diseñada para manejar consultas enrutándolas a través de una serie de procesos que involucran almacenamiento en caché del historial de mensajes, transformación de consultas y recuperación de documentos de una base de datos vectorial.
El proyecto se divide en varios módulos, cada uno responsable de funcionalidades específicas:
Siga estos pasos para configurar y ejecutar el proyecto:
Clon el repositorio :
git clone https://github.com/ranguy9304/LangGraphRAG.git
cd LangGraphRAGCrear un entorno virtual :
python3.12 -m venv venv
source venv/bin/activate # On Windows use `venvScriptsactivate`Instale los requisitos :
pip install -r requirements.txt
choco install wkhtmltopdfConfigurar las variables de entorno :
cp .env.example .env.env para agregar su clave GPT: OPENAI_API_KEY = your_gpt_key_here URLS = url1,url2GET_WEB_PAGES_TO_PDF en true si descarga las páginas web más falso: GET_WEB_PAGES_TO_PDF = False
CONVERT_PDF_TO_MD en true si ya tiene pdf más falso: CONVERT_PDF_TO_MD = True
INTERMEDIATE_PDF_DIRDATA_DIRDocumentos de configuración : desde la ejecución del directorio raíz
python modules/processDocs.pyEsto establece las páginas web y los documentos. No olvide modificar los parámetros de procesamiento de documentos en .env según sus necesidades.
Ejecute el programa principal :
python main.py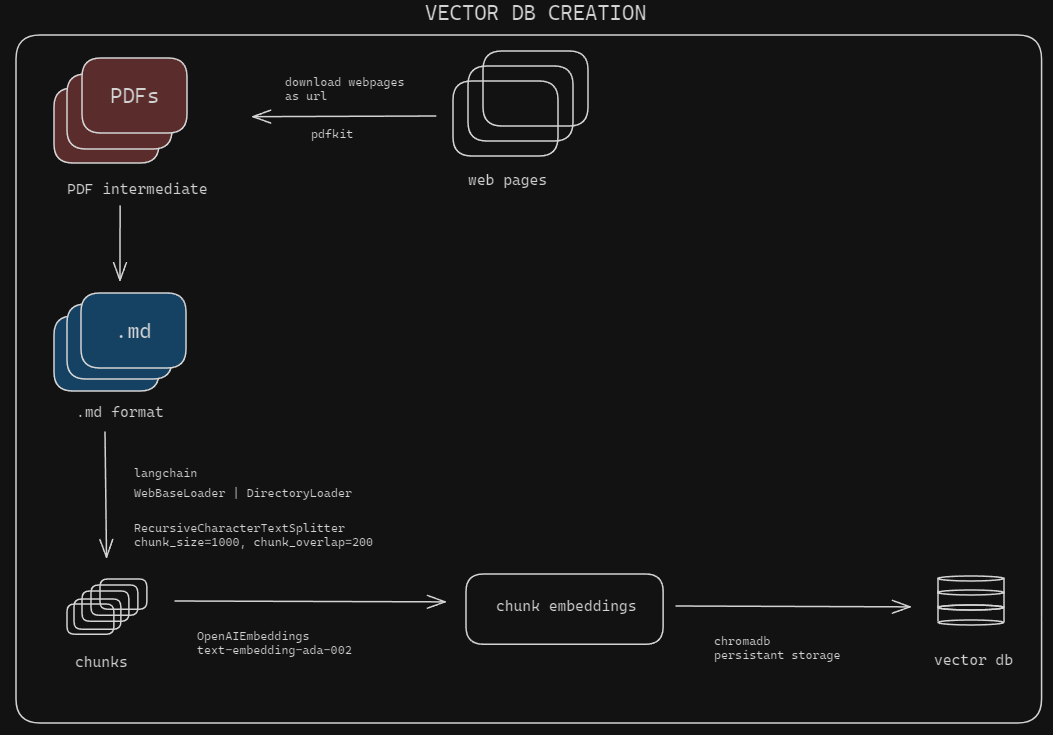
No dude en bifurcar el repositorio y enviar solicitudes de extracción. Para cambios importantes, abra un tema para discutir lo que le gustaría cambiar.
MIT


