generative ai sagemaker cdk demo
1.0.0
Les graines d'un changement de paradigme d'apprentissage automatique (ML) existent depuis des décennies, mais avec la disponibilité prête à la capacité de calcul pratiquement infinie, une prolifération massive de données et l'avancement rapide des technologies ML, les clients dans tous les secteurs adoptent rapidement et utilisent des technologies ML pour transformer leurs entreprises.
Tout récemment, des applications génératrices d'IA ont attiré l'attention et l'imagination de chacun. Nous sommes vraiment à un point d'inflexion passionnant dans l'adoption généralisée de la ML, et nous pensons que chaque expérience et application client seront réinventées avec une IA générative.
L'IA générative est un type d'IA qui peut créer de nouveaux contenus et idées, y compris des conversations, des histoires, des images, des vidéos et de la musique. Comme toutes les IA, l'IA générative est alimentée par les modèles ML - de grands modèles qui sont pré-formés sur de vastes corpus de données et communément appelés modèles de fondation (FMS).
La taille et la nature à usage général des FMs les rendent différents des modèles ML traditionnels, qui effectuent généralement des tâches spécifiques, comme l'analyse du texte pour le sentiment, la classification des images et la prévision des tendances.
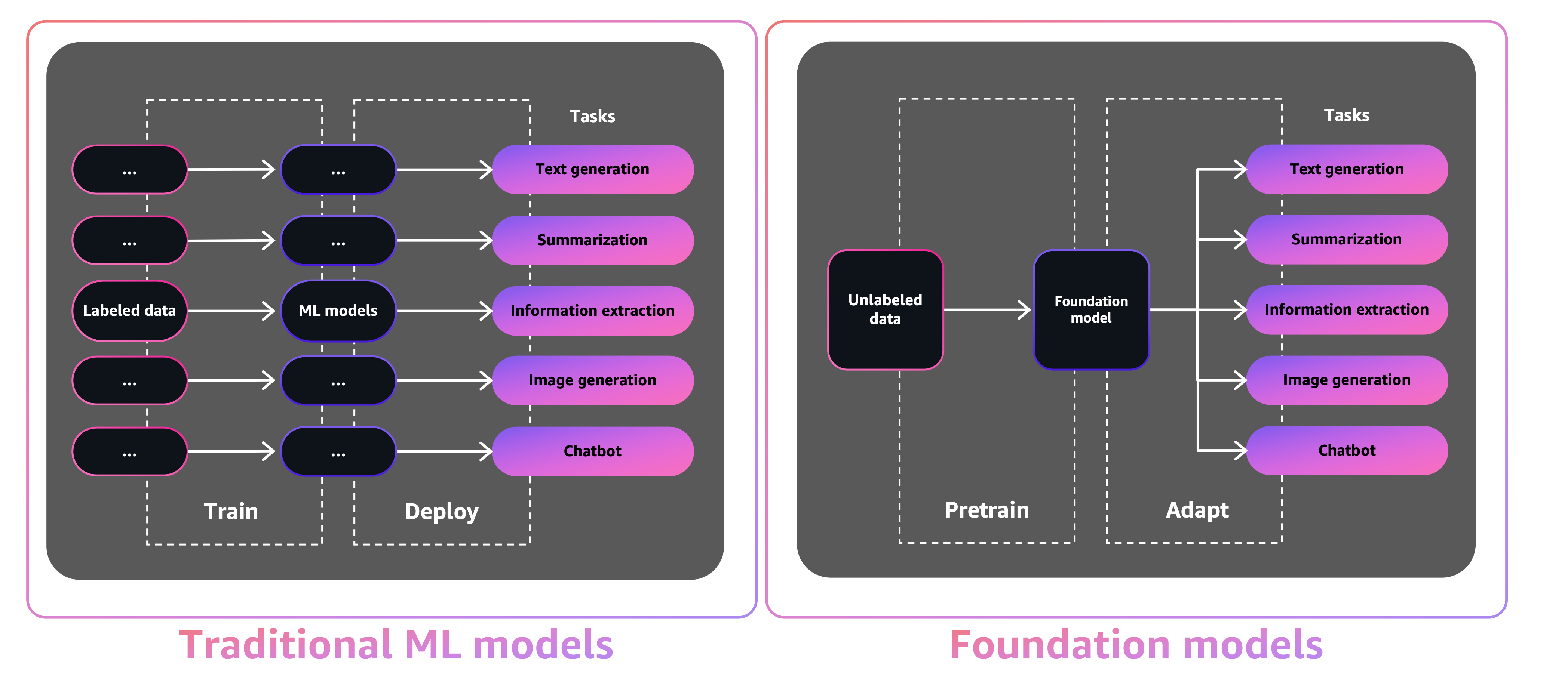
Avec les modèles de tradition ML, afin d'atteindre chaque tâche spécifique, vous devez recueillir des données étiquetées, former un modèle et déployer ce modèle. Avec des modèles de fondation, au lieu de collecter des données étiquetées pour chaque modèle et de formation de plusieurs modèles, vous pouvez utiliser le même FM pré-formé pour adapter diverses tâches. Vous pouvez également personnaliser FMS pour effectuer des fonctions spécifiques au domaine qui se différencient pour vos entreprises, en utilisant seulement une petite fraction des données et un calcul requis pour former un modèle à partir de zéro.
L'IA générative a le potentiel de perturber de nombreuses industries en révolutionnant la façon dont le contenu est créé et consommé. La production d'origine de contenu, la génération de code, l'amélioration du service client et le résumé des documents sont des cas d'utilisation typiques d'IA génératif.
Amazon Sagemaker Jumpstart fournit des modèles open-source pré-formés pour une large gamme de types de problèmes pour vous aider à démarrer avec ML. Vous pouvez progresser et régler progressivement ces modèles avant le déploiement. JumpStart fournit également des modèles de solutions qui configurent l'infrastructure pour les cas d'utilisation courants et des exemples de carnets exécutables pour ML avec Amazon SageMaker.
Avec plus de 600 modèles pré-formés disponibles et en croissance chaque jour, Jumpstart permet aux développeurs d'incorporer rapidement et facilement des techniques de ML de pointe dans leurs flux de travail de production. Vous pouvez accéder aux modèles prélevés, aux modèles de solution et aux exemples via la page de destination Jumpstart dans Amazon Sagemaker Studio. Vous pouvez également accéder aux modèles Jumpstart à l'aide du SDK Sagemaker Python. Pour plus d'informations sur la façon d'utiliser des modèles Jumpstart par programmation, voir Utiliser des algorithmes SageMaker Jumpstart avec des modèles pré-entraînés.
En avril 2023, AWS a dévoilé Amazon Bedrock, qui fournit un moyen de créer des applications génératives alimentées par AI via des modèles pré-formés à partir de startups, y compris des laboratoires AI21, des anthropiques et de la stabilité AI. Amazon Bedrock offre également un accès aux modèles de la Fondation Titan, une famille de modèles formés en interne par AWS. Avec l'expérience sans serveur du substratum rocheux d'Amazon, vous pouvez facilement trouver le bon modèle pour vos besoins, démarrer rapidement, personnaliser en privé les FM avec vos propres données et les intégrer et les déployer facilement dans vos applications en utilisant les outils AWS et les capacités que vous connaissez (y compris les intégrations avec des fonctionnalités Sagemaker ML telles que les expériences Amazon Sagemaker pour tester différents modèles et les pipelines Sagemaker Amazon pour gérer votre FMS à l'échelle) sans avoir de l'infrastructure.
Dans cet article, nous montrons comment déployer des modèles d'IA d'image et de texte génératifs à partir de Jumpstart à l'aide du kit de développement AWS Cloud (AWS CDK). Le CDK AWS est un cadre de développement de logiciels open source pour définir vos ressources d'application cloud à l'aide de langages de programmation familiers comme Python.
Nous utilisons le modèle de diffusion stable pour la génération d'images et le modèle Flan-T5-XL pour la compréhension du langage naturel (NLU) et la génération de texte à partir du visage étreint dans Jumpstart.
L'application Web est construite sur Streamlit, une bibliothèque Python open source qui facilite la création et le partage de belles applications Web personnalisées pour ML et Science des données. Nous hébergeons l'application Web à l'aide d'Amazon Elastic Container Service (Amazon ECS) avec AWS Fargate et il est accessible via un équilibreur de chargement d'application. Fargate est une technologie que vous pouvez utiliser avec Amazon ECS pour exécuter des conteneurs sans avoir à gérer des serveurs ou des grappes ou des machines virtuelles. Les points de terminaison génératifs du modèle AI sont lancés à partir d'images Jumpstart dans le registre des conteneurs élastiques Amazon (Amazon ECR). Les données du modèle sont stockées sur Amazon Simple Storage Service (Amazon S3) dans le compte Jumpstart. L'application Web interagit avec les modèles via Amazon API Gateway et AWS Lambda fonctionne comme indiqué dans le diagramme suivant.
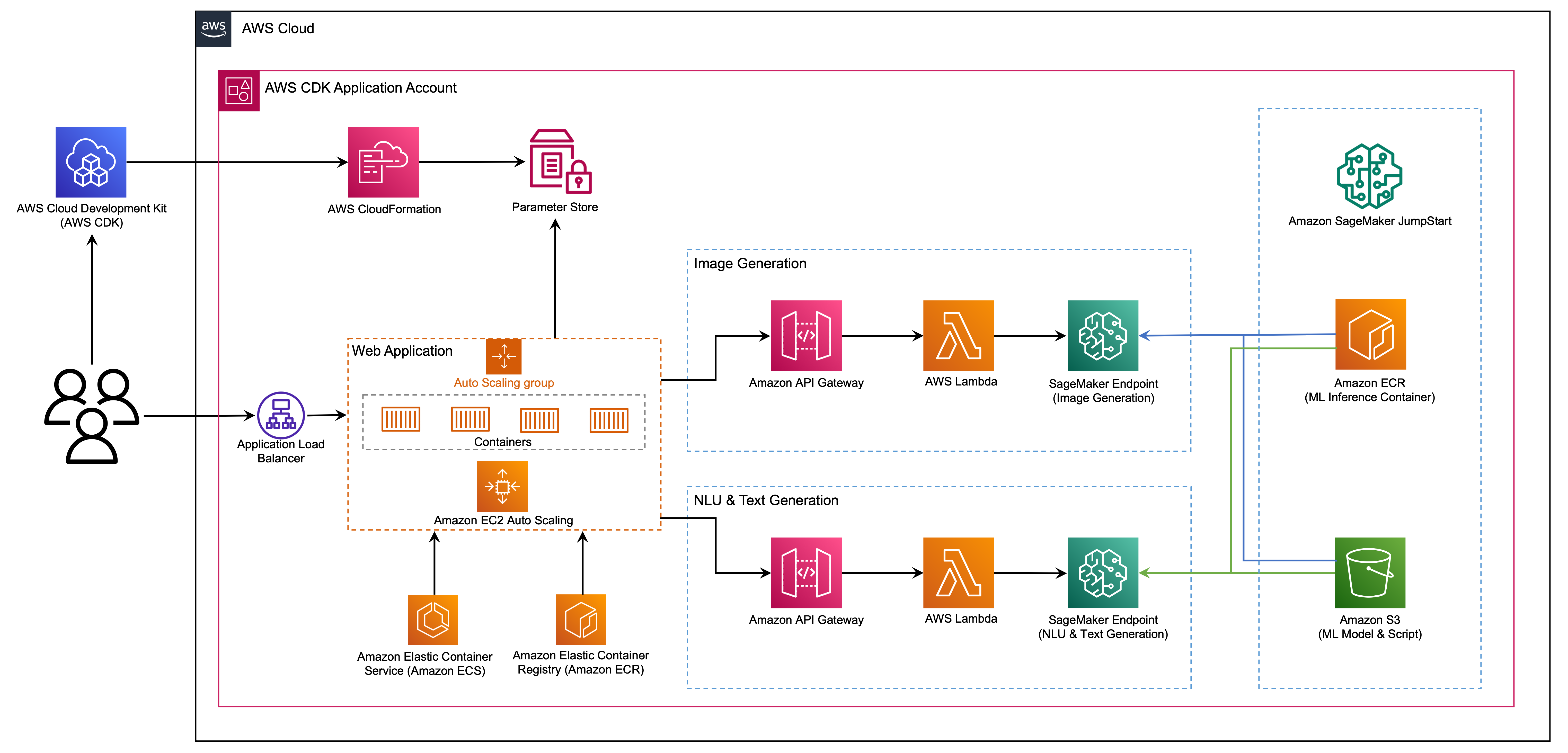
API Gateway fournit à l'application Web et à d'autres clients une interface standard, tout en protégeant les fonctions lambda qui s'interfacent avec le modèle. Cela simplifie le code d'application client qui consomme les modèles. Les points de terminaison API Gateway sont accessibles au public dans cet exemple, permettant la possibilité d'étendre cette architecture pour implémenter différents contrôles d'accès API et s'intégrer à d'autres applications.
Dans cet article, nous vous guidons à travers les étapes suivantes:
Nous donnons un aperçu du code dans ce projet en annexe à la fin de ce post.
Vous devez avoir les conditions préalables suivantes:
Vous pouvez déployer l'infrastructure dans ce tutoriel à partir de votre ordinateur local ou vous pouvez utiliser AWS Cloud9 comme poste de travail de déploiement. AWS Cloud9 est livré préchargé avec AWS CLI, AWS CDK et Docker. Si vous optez pour AWS Cloud9, créez l'environnement à partir de la console AWS.
Le coût estimé pour terminer ce message est de 50 $, en supposant que vous laissez les ressources en cours de 8 heures. Assurez-vous de supprimer les ressources que vous créez dans cet article pour éviter les frais de cours.
Si vous n'avez pas déjà le CLI AWS sur votre machine locale, reportez-vous à l'installation ou à la mise à jour de la dernière version de l'AWS CLI et à la configuration de l'AWS CLI.
Installez la boîte à outils AWS CDK globalement à l'aide de la commande Node Package Manager suivante:
npm install -g aws-cdk-lib@latest
Exécutez la commande suivante pour vérifier l'installation correcte et imprimer le numéro de version du CDK AWS:
cdk --version
Assurez-vous que Docker a installé sur votre machine locale. Émettez la commande suivante pour vérifier la version:
docker --version
Sur votre machine locale, clonez l'application AWS CDK avec la commande suivante:
git clone https://github.com/aws-samples/generative-ai-sagemaker-cdk-demo.git
Accédez au dossier du projet:
cd generative-ai-sagemaker-cdk-demo
Avant de déployer la demande, passons en revue la structure du répertoire:
.
├── LICENSE
├── README.md
├── app.py
├── cdk.json
├── code
│ ├── lambda_txt2img
│ │ └── txt2img.py
│ └── lambda_txt2nlu
│ └── txt2nlu.py
├── construct
│ └── sagemaker_endpoint_construct.py
├── images
│ ├── architecture.png
│ ├── ...
├── requirements-dev.txt
├── requirements.txt
├── source.bat
├── stack
│ ├── __init__.py
│ ├── generative_ai_demo_web_stack.py
│ ├── generative_ai_txt2img_sagemaker_stack.py
│ ├── generative_ai_txt2nlu_sagemaker_stack.py
│ └── generative_ai_vpc_network_stack.py
├── tests
│ ├── __init__.py
│ └── ...
└── web-app
├── Dockerfile
├── Home.py
├── configs.py
├── img
│ └── sagemaker.png
├── pages
│ ├── 2_Image_Generation.py
│ └── 3_Text_Generation.py
└── requirements.txt Le dossier stack contient le code pour chaque pile dans l'application CDK AWS. Le dossier code contient le code des fonctions Amazon Lambda. Le référentiel contient également l'application Web située dans le dossier web-app de dossier.
Le fichier cdk.json indique à la boîte à outils CDK AWS comment exécuter votre application.
Cette application a été testée dans la région us-east-1 mais elle devrait fonctionner dans n'importe quelle région qui a les services requis et le type d'instance d'inférence ml.g4dn.4xlarge spécifié dans App.py.
Ce projet est configuré comme un projet Python standard. Créez un environnement virtuel Python en utilisant le code suivant:
python3 -m venv .venv
Utilisez la commande suivante pour activer l'environnement virtuel:
source .venv/bin/activate
Si vous êtes sur une plate-forme Windows, activez l'environnement virtuel comme suit:
.venvScriptsactivate.bat
Une fois l'environnement virtuel activé, améliorez PIP vers la dernière version:
python3 -m pip install --upgrade pip
Installez les dépendances requises:
pip install -r requirements.txt
Avant de déployer n'importe quelle application AWS CDK, vous devez bootstrap un espace dans votre compte et la région dans laquelle vous déployez. Pour bootstrap dans votre région par défaut, émettez la commande suivante:
cdk bootstrap
Si vous souhaitez déployer dans un compte et une région spécifiques, émettez la commande suivante:
cdk bootstrap aws://ACCOUNT-NUMBER/REGION
Pour plus d'informations sur cette configuration, visitez le début du CDK AWS.
L'application AWS CDK contient plusieurs piles comme indiqué dans le diagramme suivant.
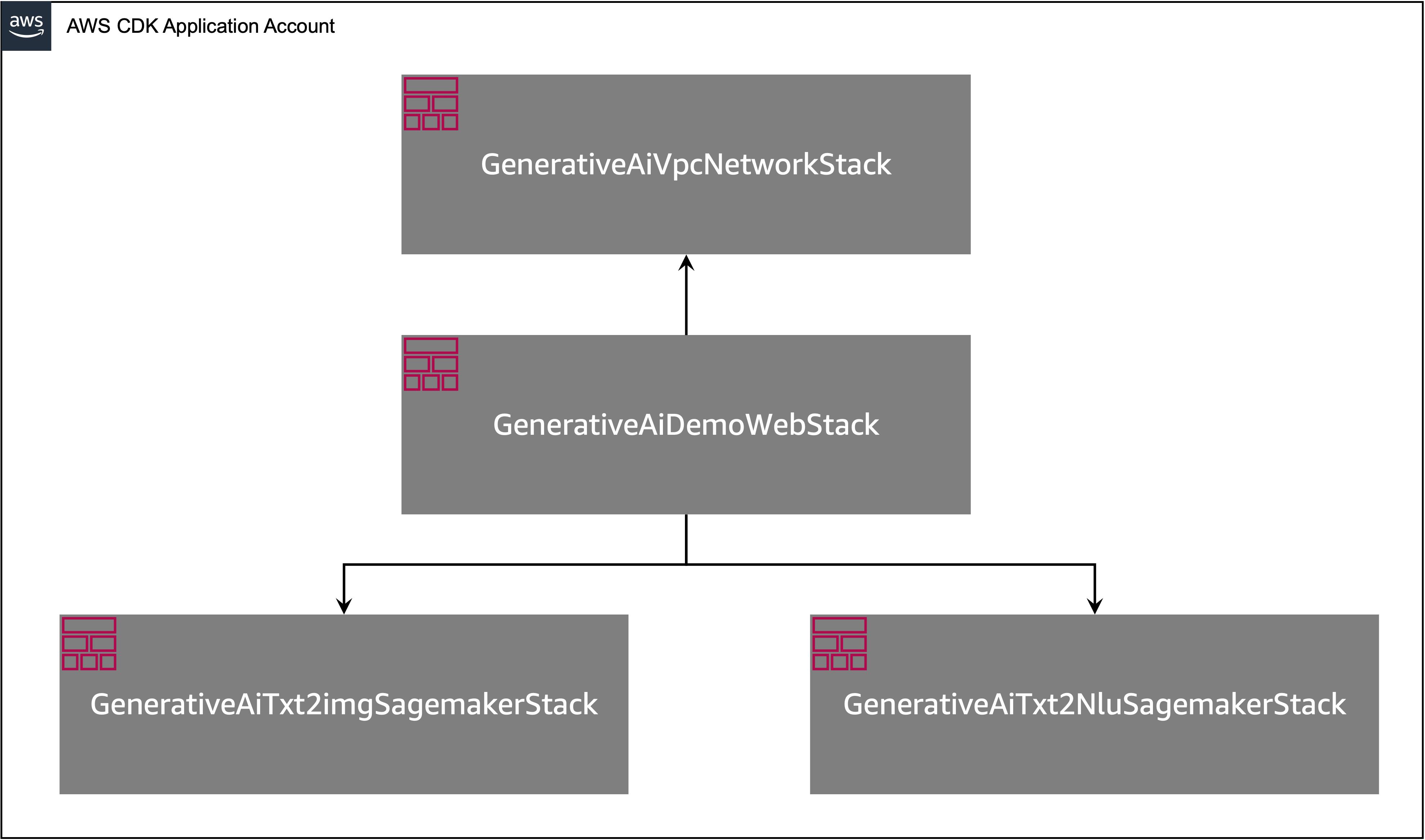
Vous pouvez répertorier des piles dans votre application CDK avec la commande suivante:
cdk listVous devriez obtenir la sortie suivante:
GenerativeAiTxt2imgSagemakerStack
GenerativeAiTxt2nluSagemakerStack
GenerativeAiVpcNetworkStack
GenerativeAiDemoWebStack
Autres commandes CDK AWS utiles:
cdk ls - répertorie toutes les piles de l'applicationcdk synth - émet le modèle de forme de nuage AWS synthétisécdk deploy - déploie cette pile sur votre compte et région par défaut AWScdk diff - Compare la pile déployée avec l'état actuelcdk docs - Ouvre la documentation AWS CDKLa section suivante vous montre comment déployer l'application AWS CDK.
L'application AWS CDK sera déployée dans la région par défaut en fonction de votre configuration de poste de travail. Si vous souhaitez forcer le déploiement dans une région spécifique, définissez votre variable d'environnement AWS_DEFAULT_REGION en conséquence.
À ce stade, vous pouvez déployer l'application AWS CDK. Vous lancez d'abord la pile de réseau VPC:
cdk deploy GenerativeAiVpcNetworkStack
Si vous êtes invité, entrez y pour procéder au déploiement. Vous devriez voir une liste de ressources AWS qui sont provisibles dans la pile. Cette étape prend environ 3 minutes pour terminer.
Ensuite, vous lancez la pile d'application Web:
cdk deploy GenerativeAiDemoWebStack
Après avoir analysé la pile, le CDK AWS affichera la liste des ressources dans la pile. Entrez y pour poursuivre le déploiement. Cette étape prend environ 5 minutes.
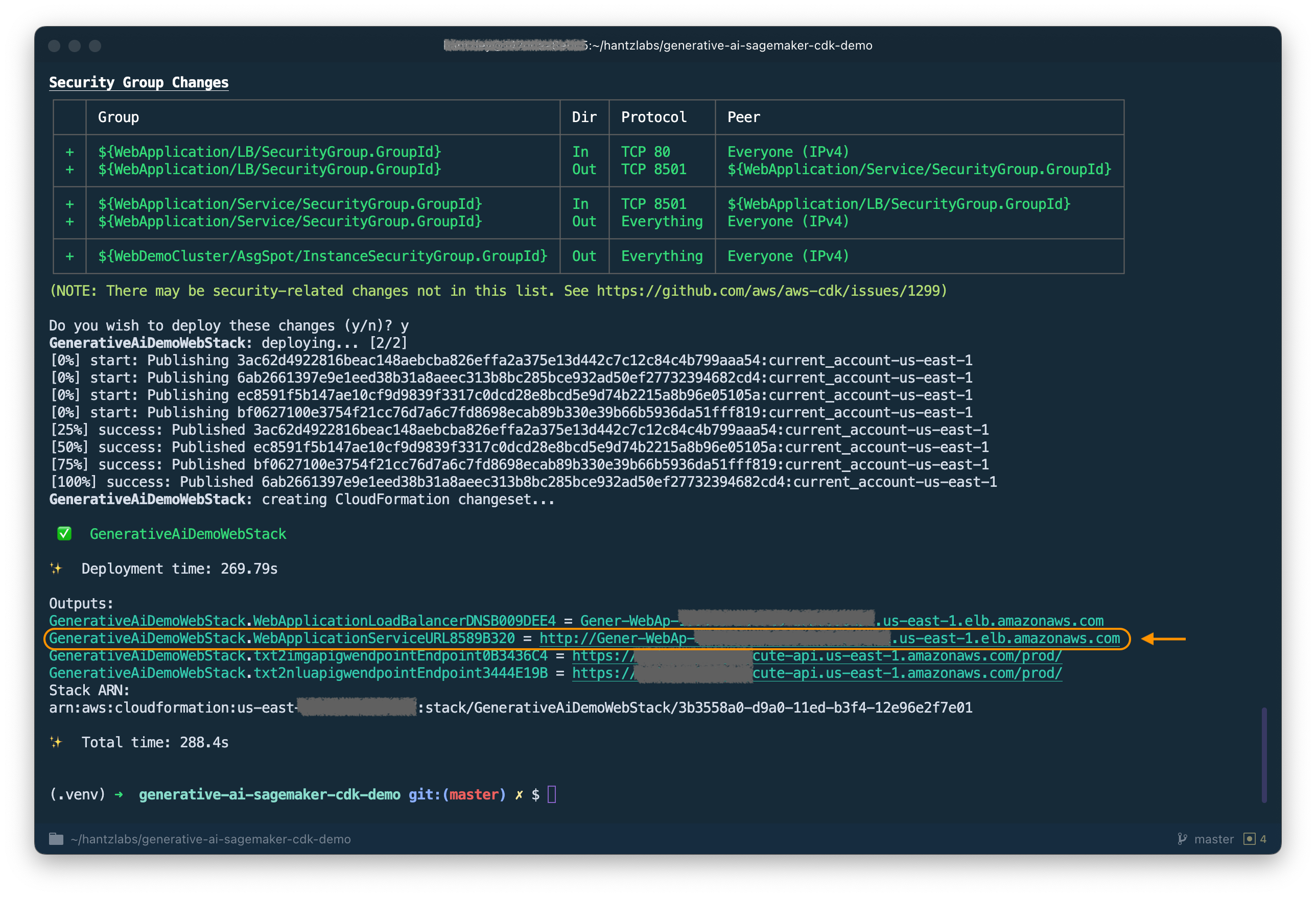
Notez le WebApplicationServiceURL à partir de la sortie comme vous l'utiliserez plus tard. Vous pouvez également le récupérer plus tard dans la console Cloudformation, sous les sorties de pile GenerativeAiDemoWebStack .
Maintenant, lancez la pile de points de terminaison du modèle AI de génération d'images:
cdk deploy GenerativeAiTxt2imgSagemakerStack
Cette étape prend environ 8 minutes. Le point de terminaison du modèle de génération d'images est déployé, nous pouvons maintenant l'utiliser.
Le premier exemple montre comment utiliser une diffusion stable, une puissante technique de modélisation générative qui permet la création d'images de haute qualité à partir d'invites de texte.
WebApplicationServiceURL à partir de la sortie du GenerativeAiDemoWebStack dans votre navigateur. 
Dans le volet de navigation, choisissez la génération d'images .
Le nom de point de terminaison SageMaker et les champs d'URL de l'API GW seront pré-peuplés, mais vous pouvez modifier l'invite pour la description de l'image si vous le souhaitez.
Choisissez Générer l'image .
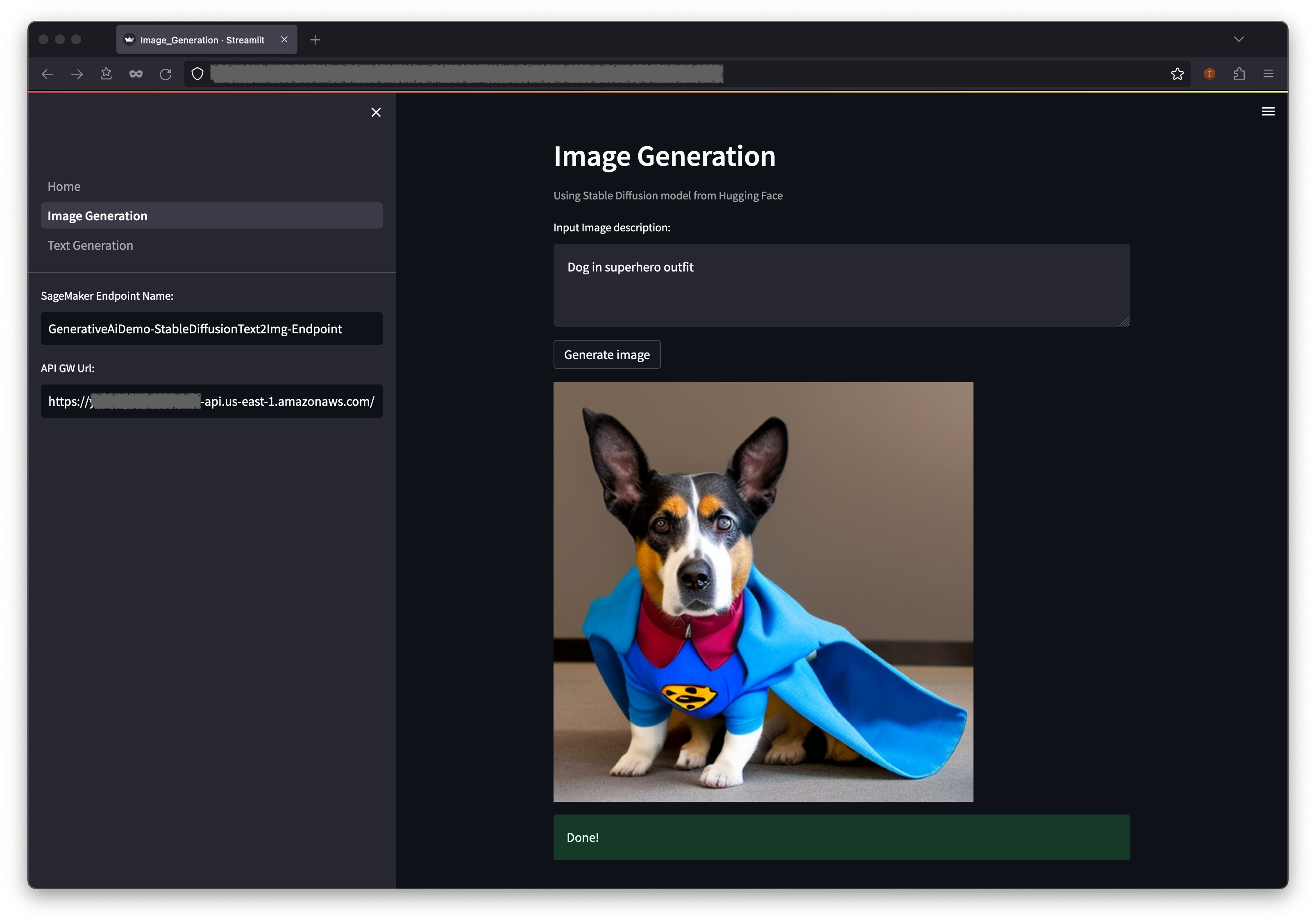
L'application passera un appel au point de terminaison SageMaker. Cela prend quelques secondes. Une image avec les charastéristics dans votre description d'image sera affichée.
Le deuxième exemple se concentre sur l'utilisation du modèle Flan-T5-XL, qui est un modèle de base ou de grande langue (LLM), pour atteindre l'apprentissage dans le contexte pour la génération de texte tout en abordant un large éventail de tâches de compréhension du langage naturel (NLU) et de génération de langage naturel (NLG).
Certains environnements peuvent limiter le nombre de points de terminaison que vous pouvez lancer à la fois. Si tel est le cas, vous pouvez lancer un point de terminaison Sagemaker à la fois. Pour arrêter un point de terminaison SageMaker dans l'application AWS CDK, vous devez détruire la pile de points de terminaison déployée et avant de lancer l'autre pile de points de terminaison. Pour refuser le point de terminaison du modèle AI de génération d'image, émettez la commande suivante:
cdk destroy GenerativeAiTxt2imgSagemakerStack
Ensuite, lancez la pile de points de terminaison du modèle AI de génération de texte:
cdk deploy GenerativeAiTxt2nluSagemakerStack
Entrez y aux invites.
Une fois la pile de points de terminaison du modèle de génération de texte, effectuez les étapes suivantes:
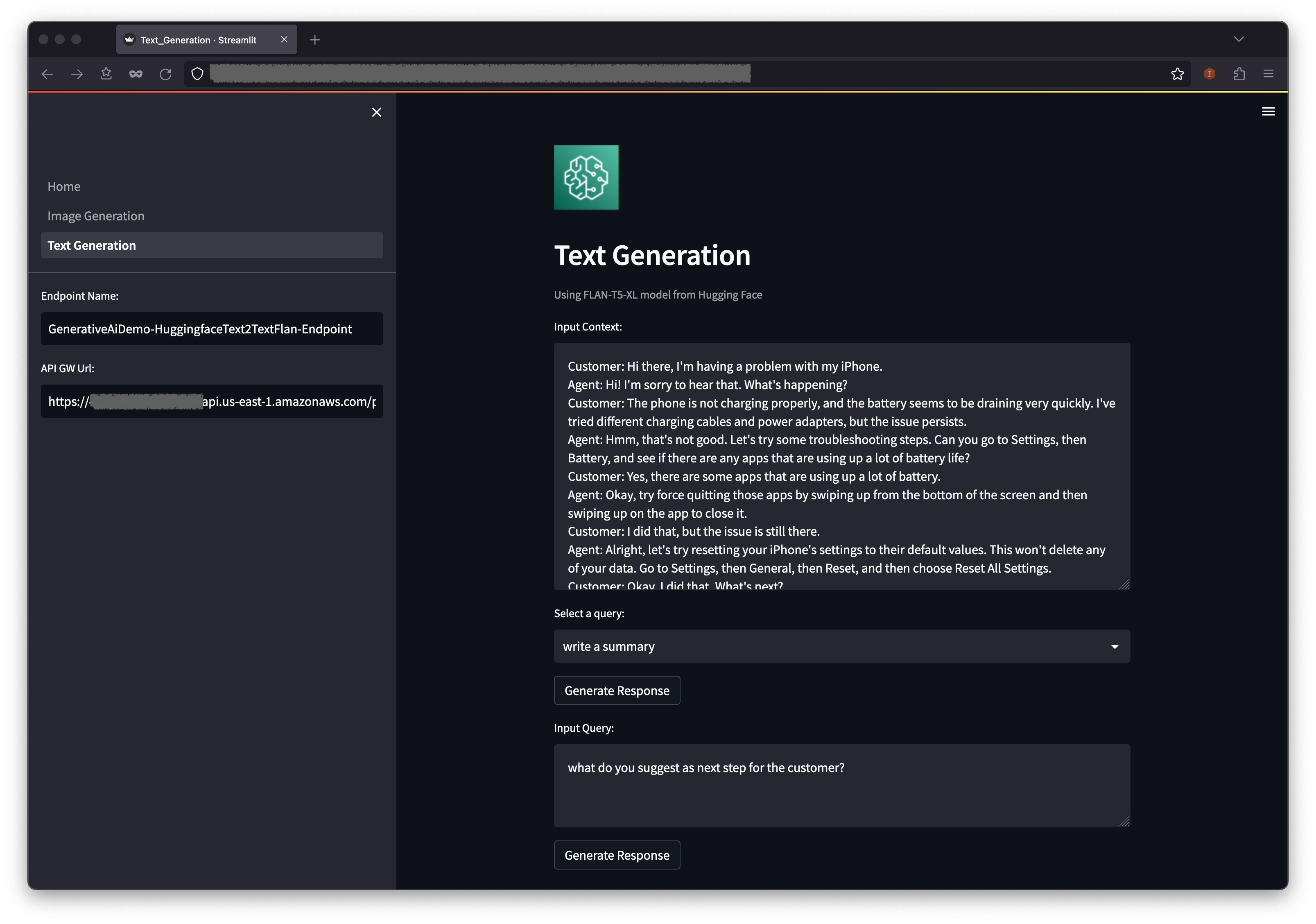
Ci-dessous du contexte, vous trouverez des requêtes préalables dans les options de menu déroulant.
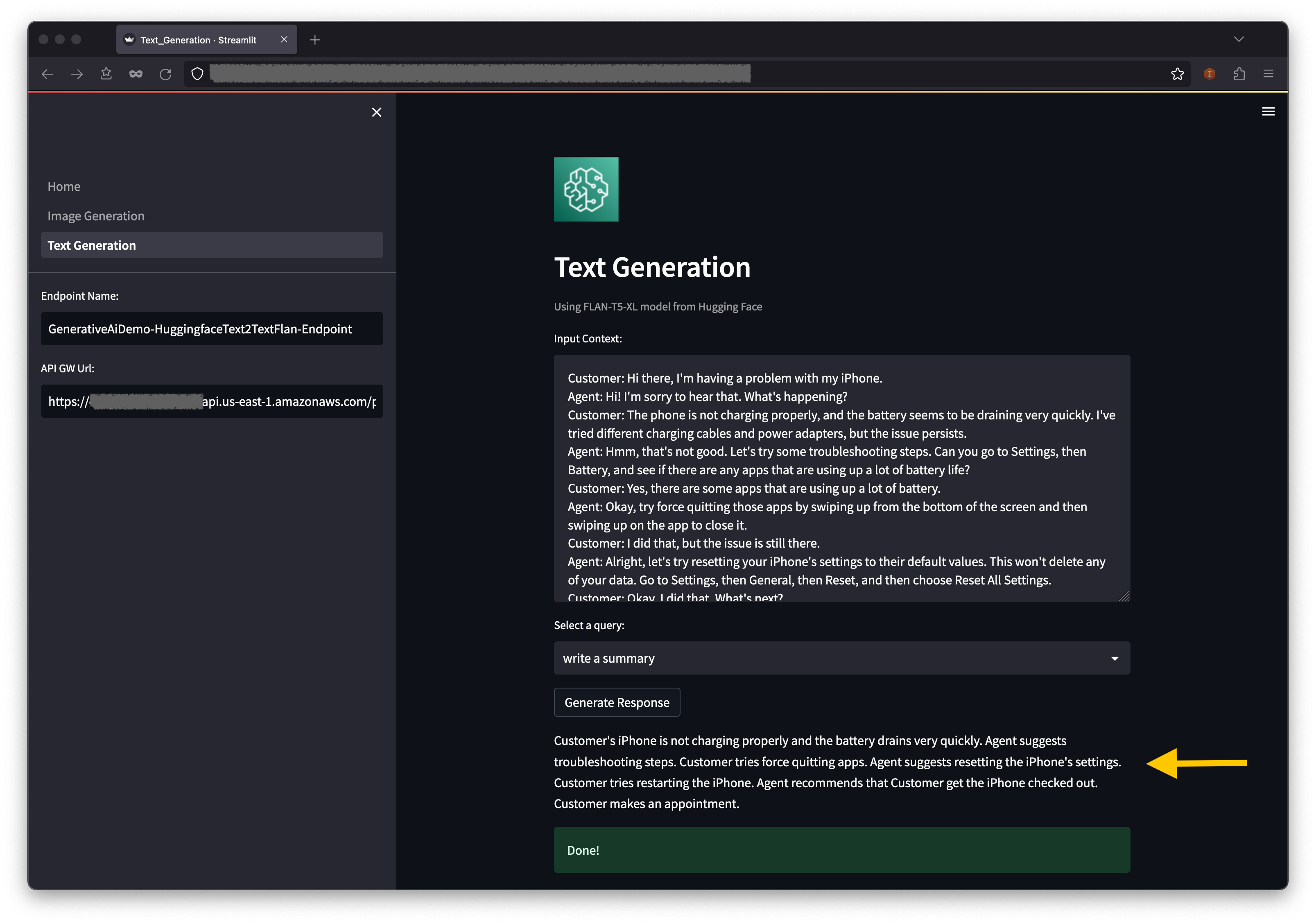
Vous pouvez également saisir votre propre requête dans le champ de requête d'entrée et choisir Générer une réponse .
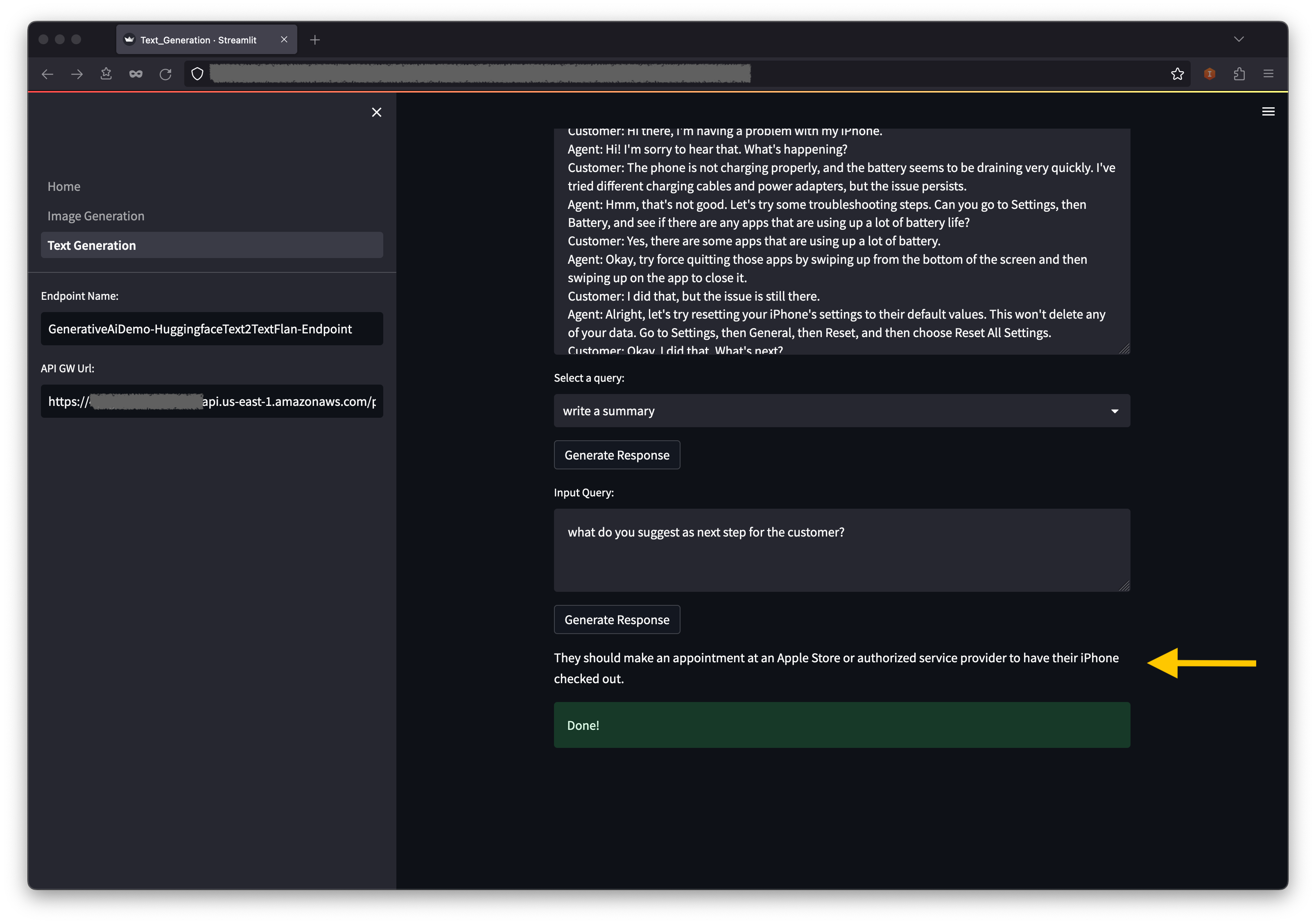
Sur la console AWS Cloudformation, choisissez des piles dans le volet de navigation pour afficher les piles déployées.
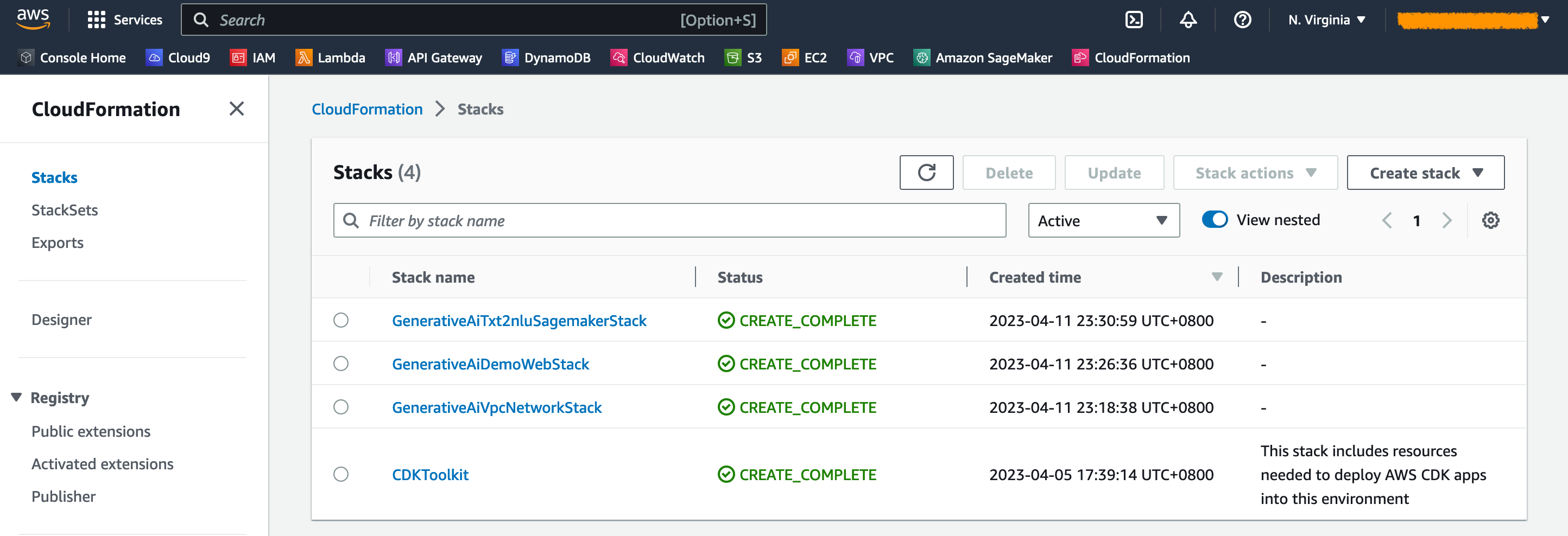
Sur la console Amazon ECS, vous pouvez voir les clusters sur la page Clusters .
Sur la console AWS Lambda, vous pouvez voir les fonctions sur la page Fonctions .
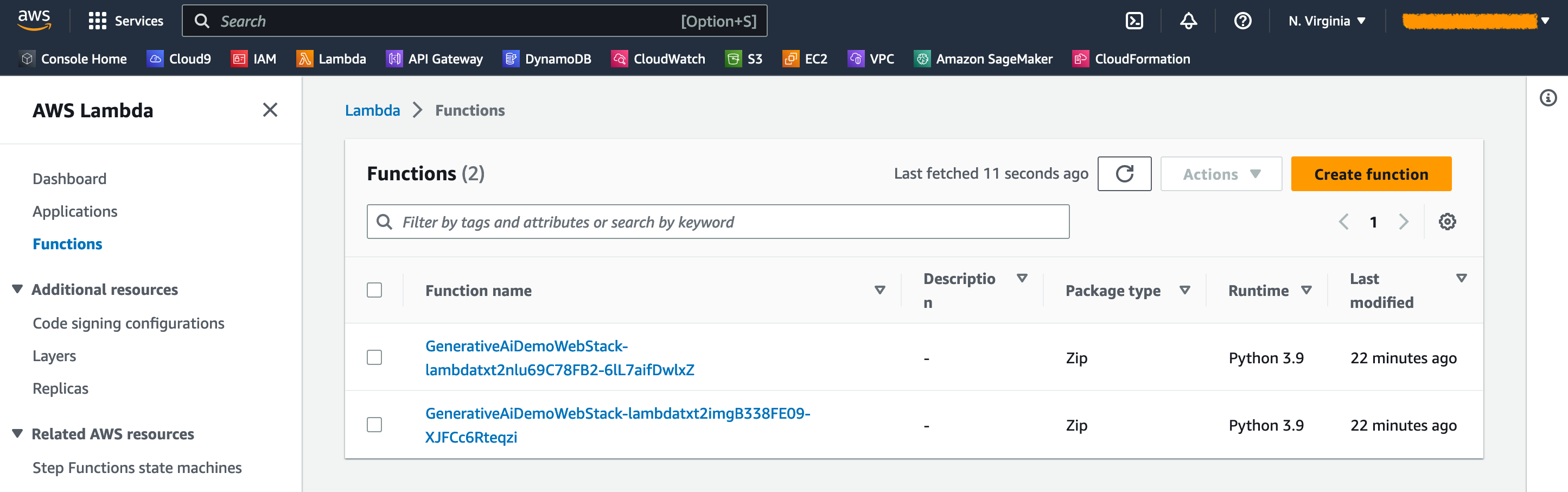
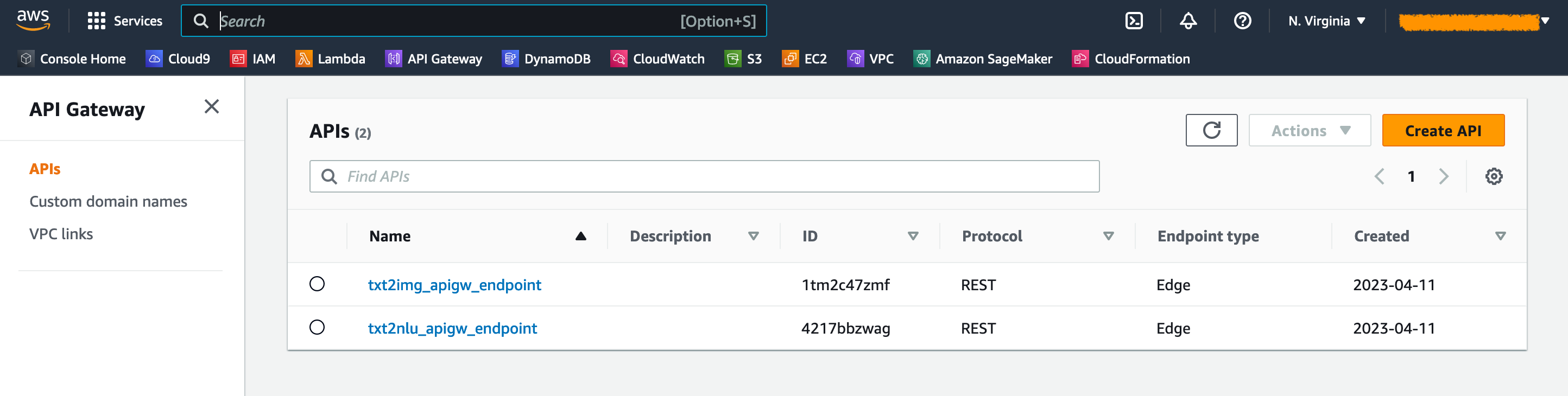
Sur la console de la passerelle API, vous pouvez voir les points de terminaison de la passerelle API sur la page API .
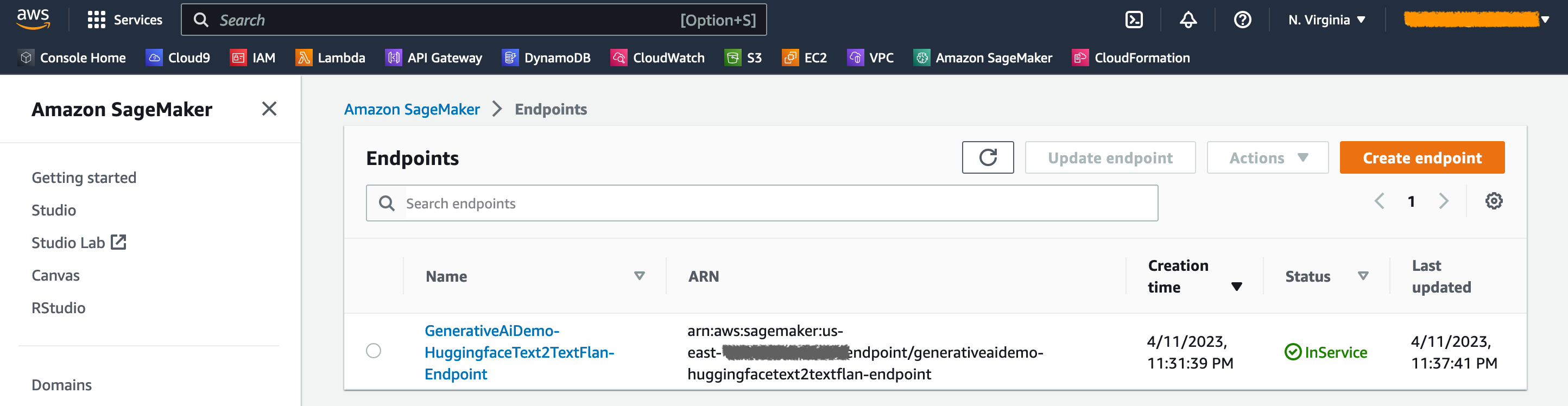
Sur la console SageMaker, vous pouvez voir les points de terminaison du modèle déployé sur la page des points de terminaison .
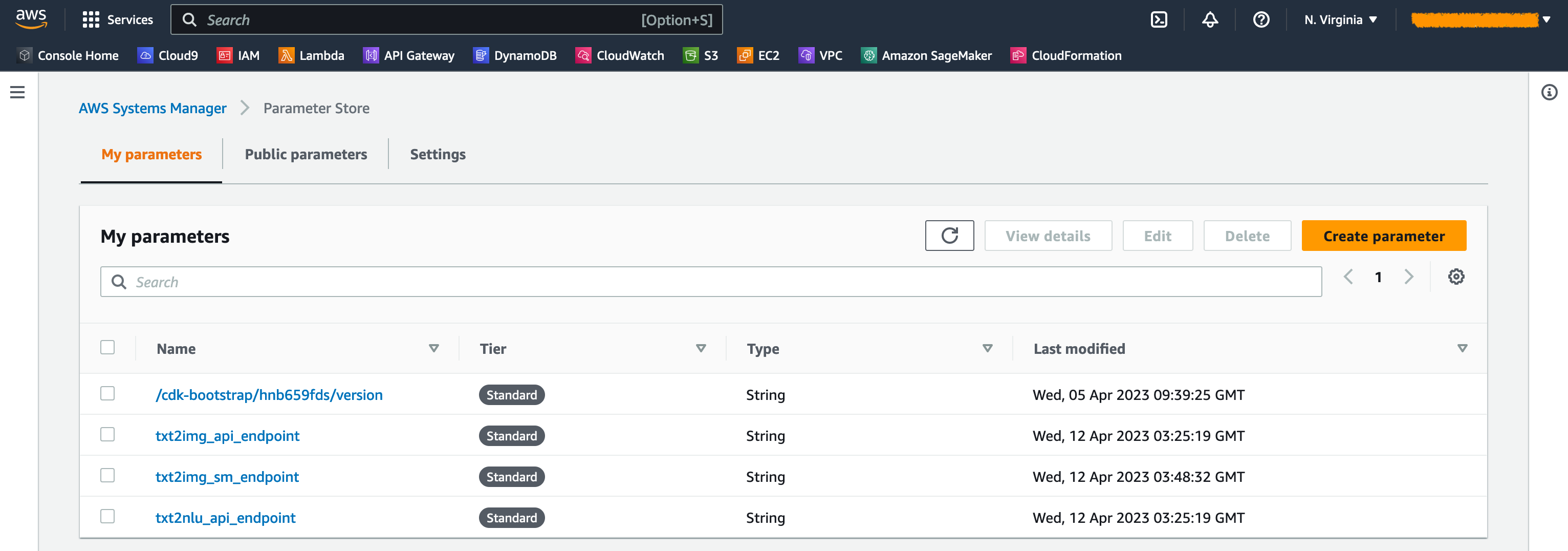
Lorsque les piles sont lancées, certains paramètres sont générés. Ceux-ci sont stockés dans le magasin de paramètres AWS Systems Manager. Pour les afficher, choisissez le magasin de paramètres dans le volet de navigation sur la console AWS Systems Manager.
Pour éviter les coûts inutiles, nettoyez toutes les infrastructures créées avec la commande suivante sur votre poste de travail:
cdk destroy --all
Entrez y à l'invite. Cette étape dure environ 10 minutes. Vérifiez si toutes les ressources sont supprimées sur la console. Supprimez également les seaux Assets S3 créés par le CDK AWS sur la console Amazon S3 ainsi que les référentiels Assets sur Amazon ECR.
Comme démontré dans cet article, vous pouvez utiliser le CDK AWS pour déployer des modèles d'IA génératifs dans Jumpstart. Nous avons montré un exemple de génération d'images et un exemple de génération de texte à l'aide d'une interface utilisateur alimentée par Streamlit, Lambda et API Gateway.
Vous pouvez désormais créer vos projets d'IA génératifs à l'aide de modèles d'IA pré-formés dans Jumpstart. Vous pouvez également étendre ce projet pour affiner les modèles de fondation pour votre cas d'utilisation et contrôler l'accès aux points de terminaison de la passerelle API.
Nous vous invitons à tester la solution et à contribuer au projet sur GitHub.
Cet exemple de code est mis à disposition sous une licence MIT modifiée. Voir le fichier de licence pour plus d'informations. Examinez également les licences respectives pour les modèles stables de diffusion et Flan-T5-XL sur la face des étreintes.
Hantzley Tauckoor est un leader de l'architecture des solutions de partenaire APJ basé à Singapour. Il a 20 ans d'expérience dans l'industrie des TIC couvrant plusieurs domaines fonctionnels, notamment l'architecture des solutions, le développement commercial, la stratégie de vente, le conseil et le leadership. Il dirige une équipe d'architectes de solutions seniors qui permettent aux partenaires de développer des solutions conjointes, de créer des capacités techniques et de les orienter à travers la phase de mise en œuvre à mesure que les clients migrent et modernisent leurs applications vers AWS. En dehors du travail, il aime passer du temps avec sa famille, regarder des films et faire de la randonnée.
Kwonyul Choi est un CTO chez Babitalk, une startup de plateforme de soins de beauté coréenne, basée à Séoul. Avant ce rôle, Kownyul a travaillé en tant qu'ingénieur de développement de logiciels chez AWS en mettant l'accent sur AWS CDK et Amazon Sagemaker.
Arunprasath Shankar est un architecte de solutions spécialisés AI / ML senior avec AWS, aidant les clients mondiaux à développer leurs solutions d'IA efficacement et efficacement dans le cloud. Dans ses temps libres, Arun aime regarder des films de science-fiction et écouter de la musique classique.
Satish Upreti est un PSA de la migration et des PME de sécurité dans l'organisation partenaire de l'APJ. Satish a 20 ans d'expérience couvrant des technologies de cloud privé et de cloud public sur site. Depuis qu'il a rejoint AWS en août 2020 en tant que spécialiste des migrations, il fournit des conseils techniques et un soutien approfondis aux partenaires AWS pour planifier et mettre en œuvre des migrations complexes.
Dans cette section, nous fournissons un aperçu du code dans ce projet.
Application CDK AWS
L'application CDK AWS principale est contenue dans le fichier app.py dans le répertoire racine. Le projet se compose de plusieurs piles, nous devons donc importer les piles:
#!/usr/bin/env python3
import aws_cdk as cdk
from stack . generative_ai_vpc_network_stack import GenerativeAiVpcNetworkStack
from stack . generative_ai_demo_web_stack import GenerativeAiDemoWebStack
from stack . generative_ai_txt2nlu_sagemaker_stack import GenerativeAiTxt2nluSagemakerStack
from stack . generative_ai_txt2img_sagemaker_stack import GenerativeAiTxt2imgSagemakerStackNous définissons nos modèles d'IA génératifs et obtenons les uris connexes de SageMaker:
from script . sagemaker_uri import *
import boto3
region_name = boto3 . Session (). region_name
env = { "region" : region_name }
#Text to Image model parameters
TXT2IMG_MODEL_ID = "model-txt2img-stabilityai-stable-diffusion-v2-1-base"
TXT2IMG_INFERENCE_INSTANCE_TYPE = "ml.g4dn.4xlarge"
TXT2IMG_MODEL_TASK_TYPE = "txt2img"
TXT2IMG_MODEL_INFO = get_sagemaker_uris ( model_id = TXT2IMG_MODEL_ID ,
model_task_type = TXT2IMG_MODEL_TASK_TYPE ,
instance_type = TXT2IMG_INFERENCE_INSTANCE_TYPE ,
region_name = region_name )
#Text to NLU image model parameters
TXT2NLU_MODEL_ID = "huggingface-text2text-flan-t5-xl"
TXT2NLU_INFERENCE_INSTANCE_TYPE = "ml.g4dn.4xlarge"
TXT2NLU_MODEL_TASK_TYPE = "text2text"
TXT2NLU_MODEL_INFO = get_sagemaker_uris ( model_id = TXT2NLU_MODEL_ID ,
model_task_type = TXT2NLU_MODEL_TASK_TYPE ,
instance_type = TXT2NLU_INFERENCE_INSTANCE_TYPE ,
region_name = region_name ) La fonction get_sagemaker_uris récupère toutes les informations du modèle d'Amazon Jumpstart. Voir script / sagemaker_uri.py.
Ensuite, nous instancions les piles:
app = cdk . App ()
network_stack = GenerativeAiVpcNetworkStack ( app , "GenerativeAiVpcNetworkStack" , env = env )
GenerativeAiDemoWebStack ( app , "GenerativeAiDemoWebStack" , vpc = network_stack . vpc , env = env )
GenerativeAiTxt2nluSagemakerStack ( app , "GenerativeAiTxt2nluSagemakerStack" , env = env , model_info = TXT2NLU_MODEL_INFO )
GenerativeAiTxt2imgSagemakerStack ( app , "GenerativeAiTxt2imgSagemakerStack" , env = env , model_info = TXT2IMG_MODEL_INFO )
app . synth () La première pile à lancer est la pile VPC, GenerativeAiVpcNetworkStack . La pile d'application Web, GenerativeAiDemoWebStack , dépend de la pile VPC. La dépendance est effectuée via le paramètre passant vpc=network_stack.vpc .
Voir app.py pour le code complet.
Pile de réseau VPC
Dans la pile GenerativeAiVpcNetworkStack , nous créons un VPC avec un sous-réseau public et un sous-réseau privé s'étendant sur deux zones de disponibilité (AZS):
self . output_vpc = ec2 . Vpc ( self , "VPC" ,
nat_gateways = 1 ,
ip_addresses = ec2 . IpAddresses . cidr ( "10.0.0.0/16" ),
max_azs = 2 ,
subnet_configuration = [
ec2 . SubnetConfiguration ( name = "public" , subnet_type = ec2 . SubnetType . PUBLIC , cidr_mask = 24 ),
ec2 . SubnetConfiguration ( name = "private" , subnet_type = ec2 . SubnetType . PRIVATE_WITH_EGRESS , cidr_mask = 24 )
]
)Voir /stack/Generative_ai_vpc_network_stack.py pour le code complet.
Pile d'applications Web de démonstration
Dans la pile GenerativeAiDemoWebStack , nous lançons les fonctions Lambda et les points de terminaison respectifs de la passerelle API Amazon à travers lesquels l'application Web interagit avec les points de terminaison du modèle SageMaker. Voir l'extrait de code suivant:
# Defines an AWS Lambda function for Image Generation service
lambda_txt2img = _lambda . Function (
self , "lambda_txt2img" ,
runtime = _lambda . Runtime . PYTHON_3_9 ,
code = _lambda . Code . from_asset ( "code/lambda_txt2img" ),
handler = "txt2img.lambda_handler" ,
role = role ,
timeout = Duration . seconds ( 180 ),
memory_size = 512 ,
vpc_subnets = ec2 . SubnetSelection (
subnet_type = ec2 . SubnetType . PRIVATE_WITH_EGRESS
),
vpc = vpc
)
# Defines an Amazon API Gateway endpoint for Image Generation service
txt2img_apigw_endpoint = apigw . LambdaRestApi (
self , "txt2img_apigw_endpoint" ,
handler = lambda_txt2img
)L'application Web est conteneurisée et hébergée sur Amazon ECS avec Fargate. Voir l'extrait de code suivant:
# Create Fargate service
fargate_service = ecs_patterns . ApplicationLoadBalancedFargateService (
self , "WebApplication" ,
cluster = cluster , # Required
cpu = 2048 , # Default is 256 (512 is 0.5 vCPU, 2048 is 2 vCPU)
desired_count = 1 , # Default is 1
task_image_options = ecs_patterns . ApplicationLoadBalancedTaskImageOptions (
image = image ,
container_port = 8501 ,
),
#load_balancer_name="gen-ai-demo",
memory_limit_mib = 4096 , # Default is 512
public_load_balancer = True ) # Default is TrueVoir /stack/Generative_ai_demo_web_stack.py pour le code complet.
Pile de points de terminaison du modèle de génération d'images
La pile GenerativeAiTxt2imgSagemakerStack crée le point de terminaison du modèle de génération d'images à partir de SageMaker Jumpstart et stocke le nom de point de terminaison dans le magasin de paramètres AWS Systems Manager. Ce paramètre sera utilisé par l'application Web. Voir le code suivant:
endpoint = SageMakerEndpointConstruct ( self , "TXT2IMG" ,
project_prefix = "GenerativeAiDemo" ,
role_arn = role . role_arn ,
model_name = "StableDiffusionText2Img" ,
model_bucket_name = model_info [ "model_bucket_name" ],
model_bucket_key = model_info [ "model_bucket_key" ],
model_docker_image = model_info [ "model_docker_image" ],
variant_name = "AllTraffic" ,
variant_weight = 1 ,
instance_count = 1 ,
instance_type = model_info [ "instance_type" ],
environment = {
"MMS_MAX_RESPONSE_SIZE" : "20000000" ,
"SAGEMAKER_CONTAINER_LOG_LEVEL" : "20" ,
"SAGEMAKER_PROGRAM" : "inference.py" ,
"SAGEMAKER_REGION" : model_info [ "region_name" ],
"SAGEMAKER_SUBMIT_DIRECTORY" : "/opt/ml/model/code" ,
},
deploy_enable = True
)
ssm . StringParameter ( self , "txt2img_sm_endpoint" , parameter_name = "txt2img_sm_endpoint" , string_value = endpoint . endpoint_name )Voir /stack/generative_ai_txt2img_sagemaker_stack.py pour le code complet.
NLU et Génération de texte Sagemaker Modèle Point de point de terminaison
La pile GenerativeAiTxt2nluSagemakerStack crée le point de terminaison du modèle NLU et de génération de texte à partir de Jumpstart et stocke le nom de point de terminaison dans le magasin de paramètres Systems Manager. Ce paramètre sera également utilisé par l'application Web. Voir le code suivant:
endpoint = SageMakerEndpointConstruct ( self , "TXT2NLU" ,
project_prefix = "GenerativeAiDemo" ,
role_arn = role . role_arn ,
model_name = "HuggingfaceText2TextFlan" ,
model_bucket_name = model_info [ "model_bucket_name" ],
model_bucket_key = model_info [ "model_bucket_key" ],
model_docker_image = model_info [ "model_docker_image" ],
variant_name = "AllTraffic" ,
variant_weight = 1 ,
instance_count = 1 ,
instance_type = model_info [ "instance_type" ],
environment = {
"MODEL_CACHE_ROOT" : "/opt/ml/model" ,
"SAGEMAKER_ENV" : "1" ,
"SAGEMAKER_MODEL_SERVER_TIMEOUT" : "3600" ,
"SAGEMAKER_MODEL_SERVER_WORKERS" : "1" ,
"SAGEMAKER_PROGRAM" : "inference.py" ,
"SAGEMAKER_SUBMIT_DIRECTORY" : "/opt/ml/model/code/" ,
"TS_DEFAULT_WORKERS_PER_MODEL" : "1"
},
deploy_enable = True
)
ssm . StringParameter ( self , "txt2nlu_sm_endpoint" , parameter_name = "txt2nlu_sm_endpoint" , string_value = endpoint . endpoint_name )Voir /stack/generative_ai_txt2nlu_sagemaker_stack.py pour le code complet.
L'application Web
L'application Web est située dans le répertoire / Web-App. Il s'agit d'une application rationalisée qui est conteneurisée selon le dockerfile:
FROM --platform=linux/x86_64 python:3.9
EXPOSE 8501
WORKDIR /app
COPY requirements.txt ./requirements.txt
RUN pip3 install -r requirements.txt
COPY . .
CMD streamlit run Home.py
--server.headless true
--browser.serverAddress= "0.0.0.0"
--server.enableCORS false
--browser.gatherUsageStats falsePour en savoir plus sur Streamlit, voir la documentation Streamlit.


