generative ai sagemaker cdk demo
1.0.0
Las semillas de un cambio de paradigma de aprendizaje automático (ML) han existido durante décadas, pero con la disponibilidad de capacidad de cálculo prácticamente infinita, una proliferación masiva de datos y el rápido avance de las tecnologías de ML, los clientes en todas las industrias están adoptando y utilizando rápidamente las tecnologías ML para transformar sus negocios.
Recientemente, las aplicaciones generativas de IA han capturado la atención y la imaginación de todos. Estamos realmente en un punto de inflexión emocionante en la adopción generalizada de ML, y creemos que cada experiencia y aplicación del cliente se reinventará con IA generativa.
La IA generativa es un tipo de IA que puede crear nuevos contenidos e ideas, incluidas conversaciones, historias, imágenes, videos y música. Como toda la IA, la IA generativa funciona con modelos ML, modelos muy grandes que se entrenan previamente en vastas corpus de datos y comúnmente conocidos como modelos de base (FMS).
El tamaño y la naturaleza de uso general de los FMS los hacen diferentes de los modelos ML tradicionales, que generalmente realizan tareas específicas, como analizar el texto para el sentimiento, la clasificación de imágenes y las tendencias de pronóstico.
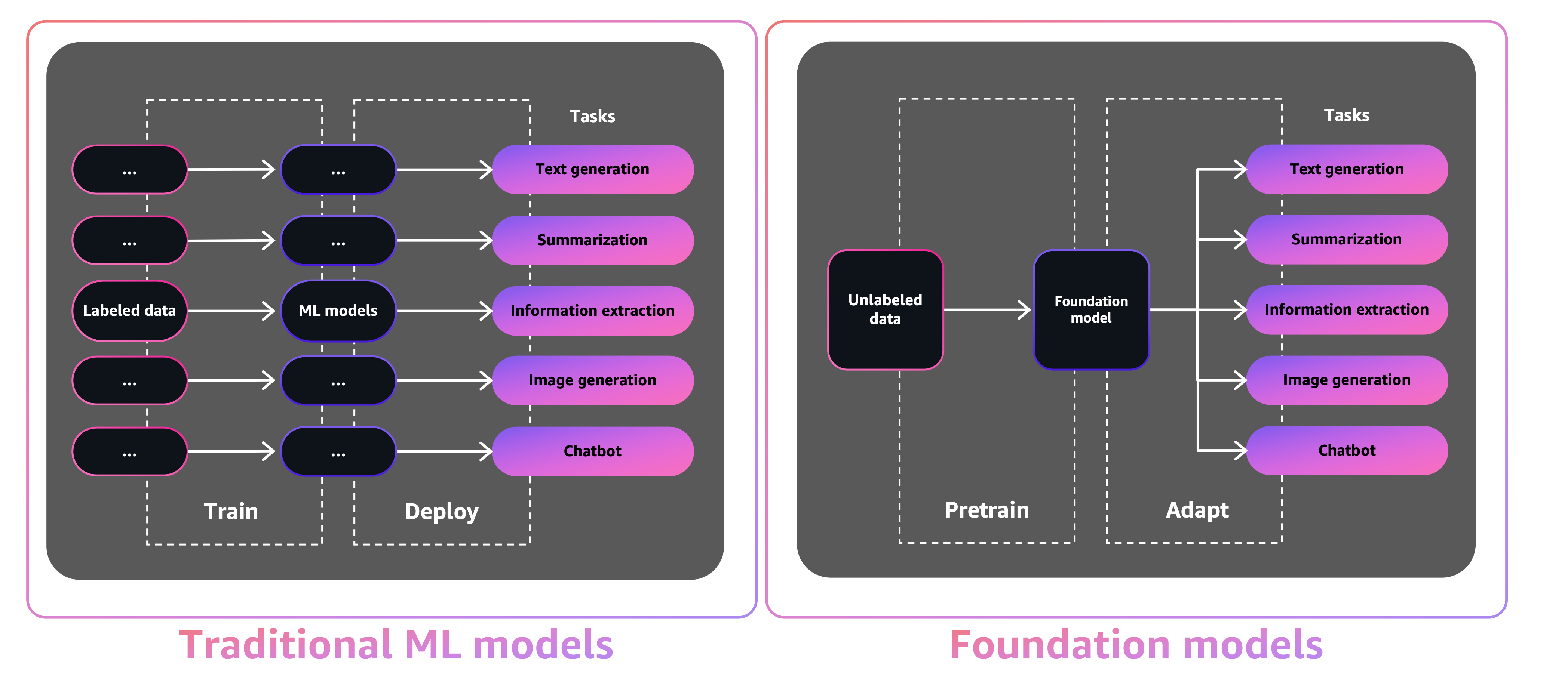
Con los modelos ML de tradición, para lograr cada tarea específica, debe recopilar datos etiquetados, capacitar a un modelo e implementar ese modelo. Con los modelos de base, en lugar de recopilar datos etiquetados para cada modelo y capacitar a múltiples modelos, puede usar el mismo FM previamente capacitado para adaptar varias tareas. También puede personalizar FMS para realizar funciones específicas de dominio que se diferencian a sus negocios, utilizando solo una pequeña fracción de los datos y calcular requerida para entrenar un modelo desde cero.
La IA generativa tiene el potencial de interrumpir muchas industrias al revolucionar la forma en que se crea y consume el contenido. La producción de contenido original, la generación de códigos, la mejora del servicio al cliente y la resumen de documentos son casos de uso típicos de IA generativa.
Amazon Sagemaker JumpStart proporciona modelos de código abierto previamente capacitados para una amplia gama de tipos de problemas para ayudarlo a comenzar con ML. Puede entrenar y ajustar incrementalmente estos modelos antes de la implementación. JumpStart también proporciona plantillas de solución que configuran infraestructura para casos de uso comunes y cuadernos de ejemplo ejecutables para ML con Amazon Sagemaker.
Con más de 600 modelos previamente capacitados disponibles y creciendo cada día, JumpStart permite a los desarrolladores incorporar de manera rápida y fácil las técnicas de ML de vanguardia en sus flujos de trabajo de producción. Puede acceder a los modelos previamente capacitados, plantillas de solución y ejemplos a través de la página de destino de JumpStart en Amazon Sagemaker Studio. También puede acceder a los modelos JumpStart utilizando el Sagemaker Python SDK. Para obtener información sobre cómo usar los modelos JumpStart mediante programación, consulte Use algoritmos de SageMaker JumpStart con modelos previos a la aparición.
En abril de 2023, AWS dio a conocer la roca madre de Amazon, que proporciona una forma de construir aplicaciones generativas con IA a través de modelos previamente capacitados a partir de startups, incluidos laboratorios AI21, antrópico e IA de estabilidad. Amazon Bedrock también ofrece acceso a Titan Foundation Models, una familia de modelos entrenados internamente por AWS. Con la experiencia sin servidor de Amazon Bedrock, puede encontrar fácilmente el modelo adecuado para sus necesidades, comenzar de manera rápida, personalice de forma privada FMS con sus propios datos e integrarlos e implementarlos fácilmente en sus aplicaciones utilizando las herramientas y capacidades de AWS con las que está familiarizado (incluidas las integraciones con las características de Sagemaker ML como los experimentos de Amazon Sagumaker para probar diferentes modelos y Amazon Pipelines para administrar sus FMS en la escala) sin tener que tener que tener que tener que tener que tener que tener que tener que tener que tener que tener que tener que tener que tener que administrar los experimentos de Amazon.
En esta publicación, mostramos cómo implementar modelos de IA generativos de imagen y texto de JumpStart utilizando el Kit de desarrollo de AWS Cloud (AWS CDK). El AWS CDK es un marco de desarrollo de software de código abierto para definir los recursos de su aplicación en la nube utilizando lenguajes de programación familiares como Python.
Utilizamos el modelo de difusión estable para la generación de imágenes y el modelo FLAN-T5-XL para la comprensión del lenguaje natural (NLU) y la generación de texto de la cara de abrazo en Jumpstart.
La aplicación web está construida en Streamlit, una biblioteca de Python de código abierto que facilita la creación y compartir aplicaciones web hermosas y personalizadas para ML y ciencia de datos. Organizamos la aplicación web utilizando el servicio de contenedores elásticos de Amazon (Amazon ECS) con AWS Fargate y se accede a través de un equilibrador de carga de la aplicación. Fargate es una tecnología que puede usar con Amazon ECS para ejecutar contenedores sin tener que administrar servidores, grupos o máquinas virtuales. Los puntos finales del modelo AI generativo se lanzan desde imágenes de JumpStart en Amazon Elastic Container Registry (Amazon ECR). Los datos del modelo se almacenan en Amazon Simple Storage Service (Amazon S3) en la cuenta JumpStart. La aplicación web interactúa con los modelos a través de Amazon API Gateway y las funciones de AWS Lambda como se muestra en el siguiente diagrama.
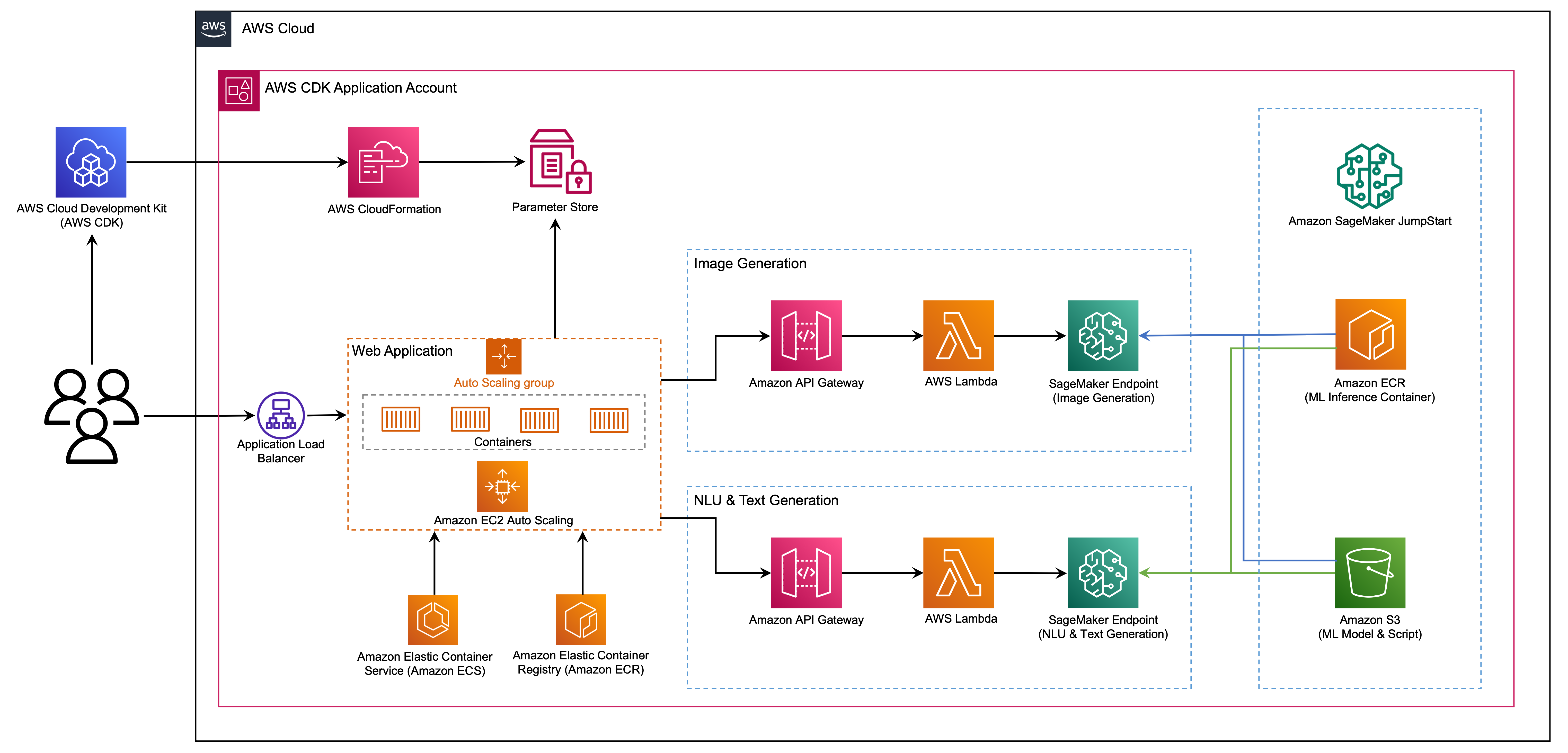
API Gateway proporciona a la aplicación web y a otros clientes una interfaz RESTful estándar, al tiempo que protege las funciones Lambda que interactúan con el modelo. Esto simplifica el código de aplicación del cliente que consume los modelos. Los puntos finales de la puerta de enlace API son accesibles públicamente en este ejemplo, lo que permite la posibilidad de extender esta arquitectura para implementar diferentes controles de acceso a API e integrarse con otras aplicaciones.
En esta publicación, lo guiamos a través de los siguientes pasos:
Proporcionamos una descripción general del código en este proyecto en el apéndice al final de esta publicación.
Debes tener los siguientes requisitos previos:
Puede implementar la infraestructura en este tutorial desde su computadora local o puede usar AWS Cloud9 como estación de trabajo de implementación. AWS Cloud9 viene precargado con AWS CLI, AWS CDK y Docker. Si opta por AWS Cloud9, cree el entorno desde la consola AWS.
El costo estimado para completar esta publicación es de $ 50, suponiendo que deje los recursos que se ejecutan durante 8 horas. Asegúrese de eliminar los recursos que crea en esta publicación para evitar cargos continuos.
Si aún no tiene la AWS CLI en su máquina local, consulte la instalación o actualización de la última versión de la CLI AWS y configurando la AWS CLI.
Instale el kit de herramientas AWS CDK a nivel mundial utilizando el siguiente comando de Administrador de paquetes de nodo:
npm install -g aws-cdk-lib@latest
Ejecute el siguiente comando para verificar la instalación correcta e imprimir el número de versión del AWS CDK:
cdk --version
Asegúrese de tener Docker instalado en su máquina local. Emita el siguiente comando para verificar la versión:
docker --version
En su máquina local, clone la aplicación AWS CDK con el siguiente comando:
git clone https://github.com/aws-samples/generative-ai-sagemaker-cdk-demo.git
Navegue a la carpeta del proyecto:
cd generative-ai-sagemaker-cdk-demo
Antes de implementar la aplicación, revisemos la estructura del directorio:
.
├── LICENSE
├── README.md
├── app.py
├── cdk.json
├── code
│ ├── lambda_txt2img
│ │ └── txt2img.py
│ └── lambda_txt2nlu
│ └── txt2nlu.py
├── construct
│ └── sagemaker_endpoint_construct.py
├── images
│ ├── architecture.png
│ ├── ...
├── requirements-dev.txt
├── requirements.txt
├── source.bat
├── stack
│ ├── __init__.py
│ ├── generative_ai_demo_web_stack.py
│ ├── generative_ai_txt2img_sagemaker_stack.py
│ ├── generative_ai_txt2nlu_sagemaker_stack.py
│ └── generative_ai_vpc_network_stack.py
├── tests
│ ├── __init__.py
│ └── ...
└── web-app
├── Dockerfile
├── Home.py
├── configs.py
├── img
│ └── sagemaker.png
├── pages
│ ├── 2_Image_Generation.py
│ └── 3_Text_Generation.py
└── requirements.txt La carpeta de stack contiene el código para cada pila en la aplicación AWS CDK. La carpeta code contiene el código para las funciones de Amazon Lambda. El repositorio también contiene la aplicación web ubicada en la carpeta web-app .
El archivo cdk.json le dice al Kit de herramientas AWS CDK cómo ejecutar su aplicación.
Esta aplicación se probó en la región us-east-1 , pero debería funcionar en cualquier región que tenga los servicios e instancia de inferencia requeridos tipo ml.g4dn.4xlarge especificado en App.py.
Este proyecto está configurado como un proyecto Python estándar. Cree un entorno virtual de Python utilizando el siguiente código:
python3 -m venv .venv
Use el siguiente comando para activar el entorno virtual:
source .venv/bin/activate
Si está en una plataforma de Windows, active el entorno virtual de la siguiente manera:
.venvScriptsactivate.bat
Después de activar el entorno virtual, actualice PIP a la última versión:
python3 -m pip install --upgrade pip
Instale las dependencias requeridas:
pip install -r requirements.txt
Antes de implementar cualquier aplicación AWS CDK, debe arrancar un espacio en su cuenta y en la región en la que está implementando. Para arrancar en su región predeterminada, emita el siguiente comando:
cdk bootstrap
Si desea implementar en una cuenta y región específicas, emita el siguiente comando:
cdk bootstrap aws://ACCOUNT-NUMBER/REGION
Para obtener más información sobre esta configuración, visite comenzar con el AWS CDK.
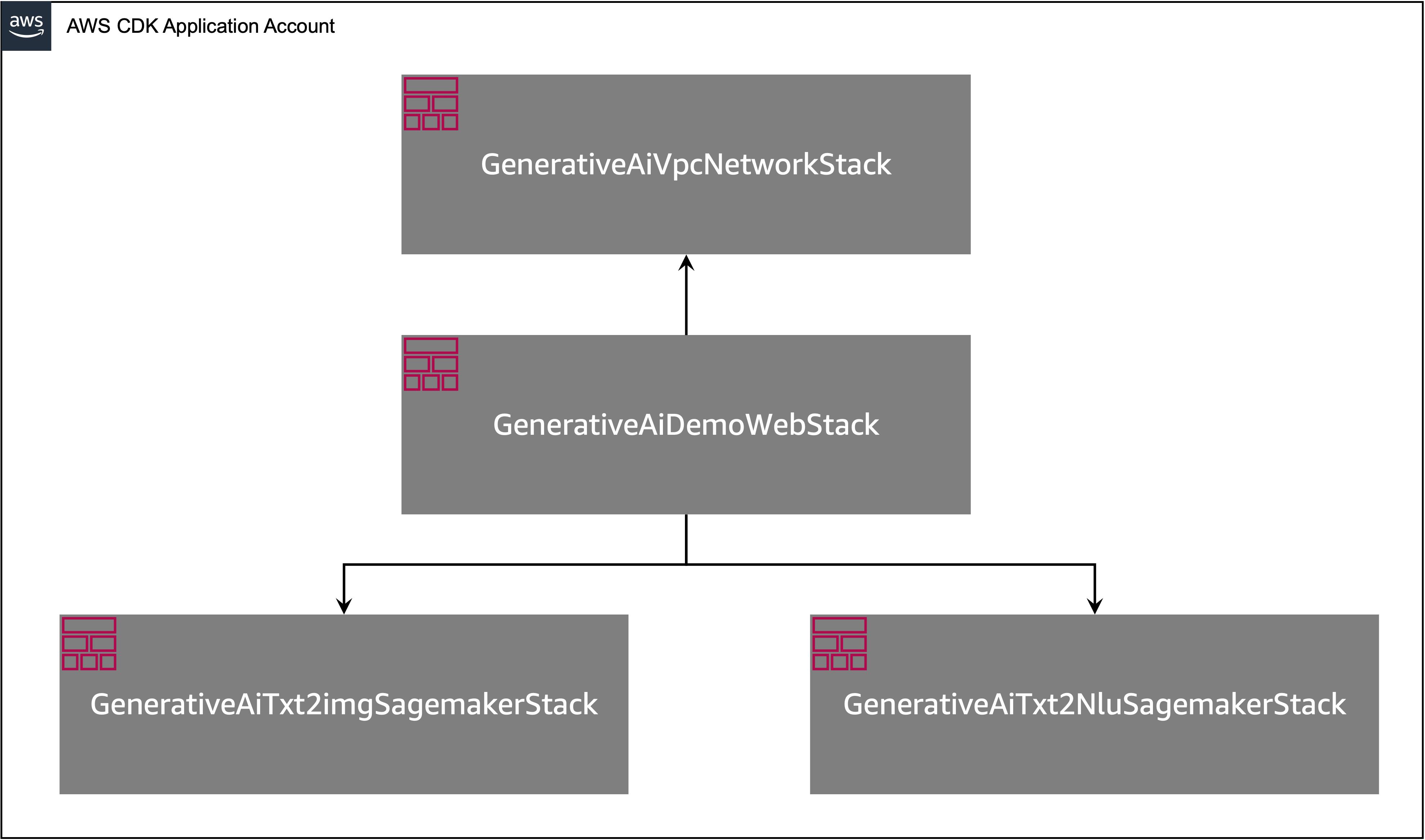
La aplicación AWS CDK contiene múltiples pilas como se muestra en el siguiente diagrama.
Puede enumerar las pilas en su aplicación CDK con el siguiente comando:
cdk listDebe obtener la siguiente salida:
GenerativeAiTxt2imgSagemakerStack
GenerativeAiTxt2nluSagemakerStack
GenerativeAiVpcNetworkStack
GenerativeAiDemoWebStack
Otros comandos útiles de AWS CDK:
cdk ls : enumera todas las pilas en la aplicacióncdk synth : emite la plantilla sintetizada de AWS CloudFormationcdk deploy : implementa esta pila en su cuenta AWS predeterminada y regióncdk diff : compara la pila implementada con el estado actualcdk docs : abre la documentación de AWS CDKLa siguiente sección le muestra cómo implementar la aplicación AWS CDK.
La aplicación AWS CDK se implementará en la región predeterminada en función de la configuración de su estación de trabajo. Si desea forzar la implementación en una región específica, establezca su variable de entorno AWS_DEFAULT_REGION en consecuencia.
En este punto, puede implementar la aplicación AWS CDK. Primero inicia la pila de red VPC:
cdk deploy GenerativeAiVpcNetworkStack
Si se le solicita, ingrese y para continuar con la implementación. Debería ver una lista de recursos de AWS que se están aprovisionando en la pila. Este paso tarda alrededor de 3 minutos en completarse.
Luego inicia la pila de aplicaciones web:
cdk deploy GenerativeAiDemoWebStack
Después de analizar la pila, el AWS CDK mostrará la lista de recursos en la pila. Ingrese y para continuar con el despliegue. Este paso toma alrededor de 5 minutos.
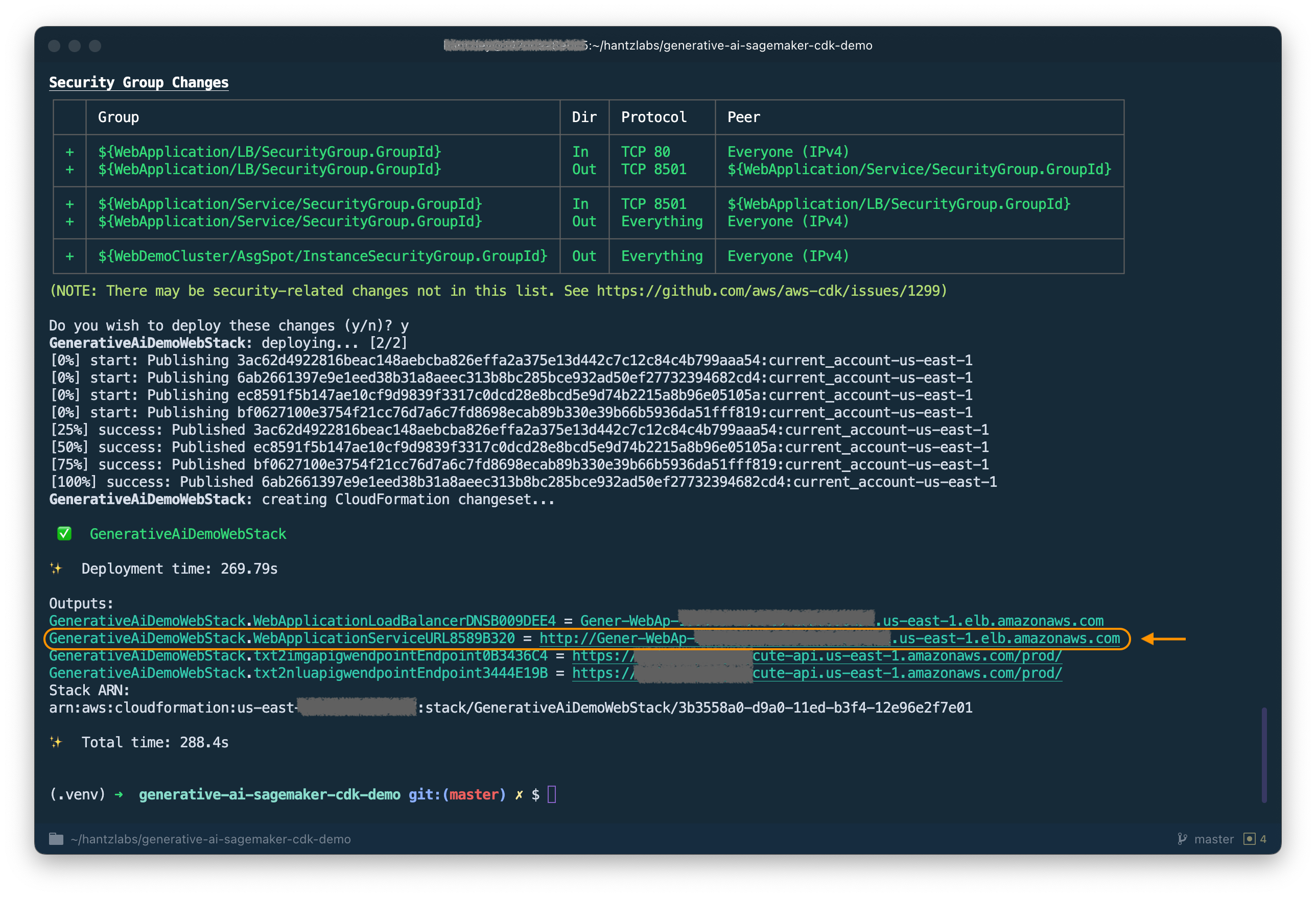
Observe el WebApplicationServiceURL desde la salida, ya que la usará más adelante. También puede recuperarlo más adelante en la consola CloudFormation, bajo las salidas GenerativeAiDemoWebStack Stack.
Ahora, inicie la pila de punto final del modelo AI de generación de imágenes:
cdk deploy GenerativeAiTxt2imgSagemakerStack
Este paso toma alrededor de 8 minutos. Se implementa el punto final del modelo de generación de imágenes, ahora podemos usarlo.
El primer ejemplo demuestra cómo utilizar la difusión estable, una poderosa técnica de modelado generativo que permite la creación de imágenes de alta calidad a partir de indicaciones de texto.
WebApplicationServiceURL desde la salida del GenerativeAiDemoWebStack en su navegador. 
En el panel de navegación, elija Generación de imágenes .
El nombre de punto final de Sagemaker y los campos de URL API GW estarán previamente poblados, pero puede cambiar la solicitud de la descripción de la imagen si lo desea.
Elija Generar imagen .
La aplicación hará una llamada al punto final de Sagemaker. Toma unos segundos. Se mostrará una imagen con la descripción de Charasteristics en su imagen.
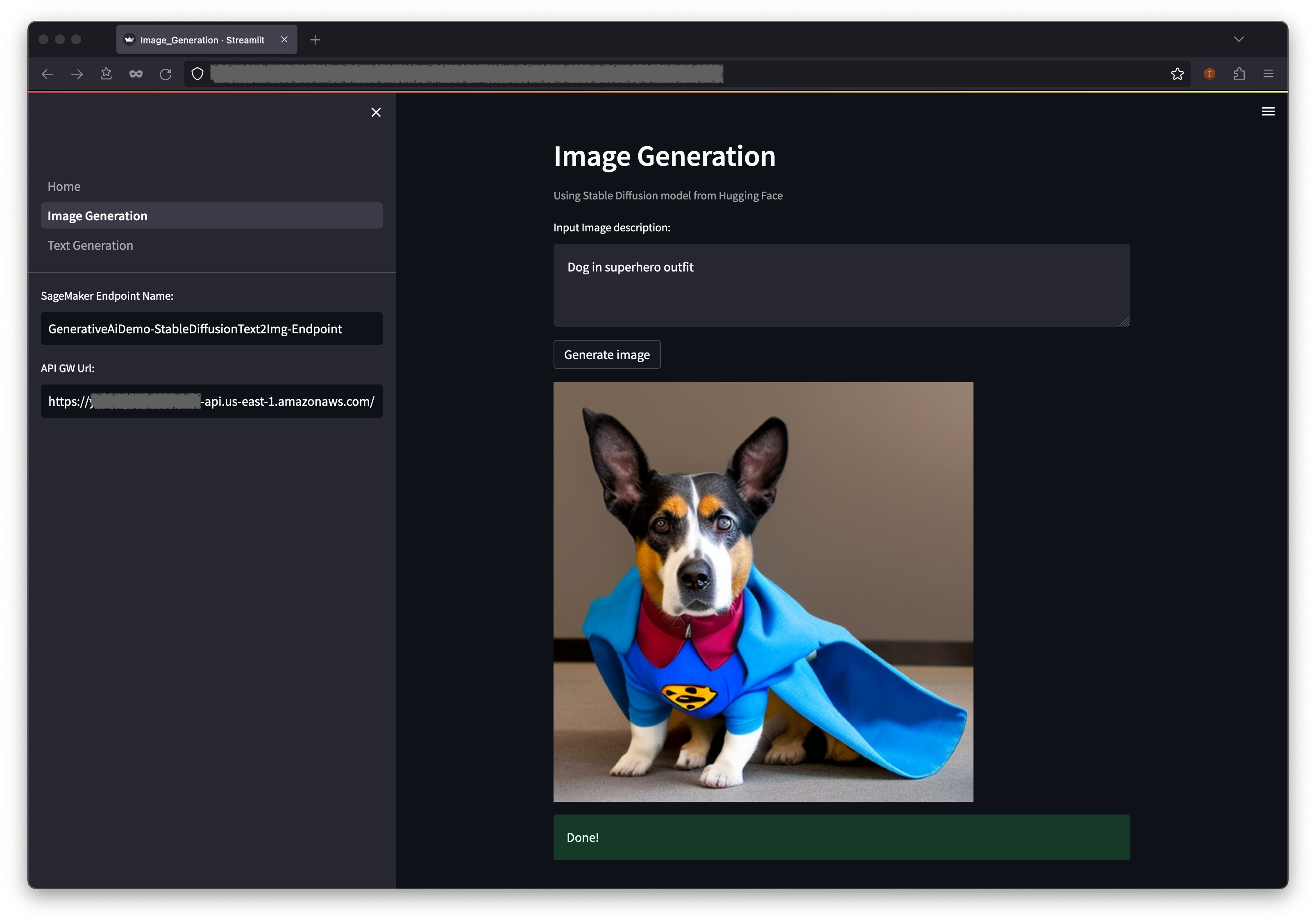
El segundo ejemplo se centra en el uso del modelo Flan-T5-XL, que es un modelo de base o lenguaje grande (LLM), para lograr un aprendizaje en contexto para la generación de texto al tiempo que aborda una amplia gama de tareas de comprensión del lenguaje natural (NLU) y generación de lenguaje natural (NLG).
Algunos entornos pueden limitar la cantidad de puntos finales que puede lanzar a la vez. Si este es el caso, puede iniciar un punto final de Sagemaker a la vez. Para detener un punto final de Sagemaker en la aplicación AWS CDK, debe destruir la pila de punto final implementado y antes de iniciar la otra pila de punto final. Para rechazar el punto final del modelo AI de generación de imágenes, emita el siguiente comando:
cdk destroy GenerativeAiTxt2imgSagemakerStack
Luego inicie la pila de punto final del modelo AI de generación de texto:
cdk deploy GenerativeAiTxt2nluSagemakerStack
Ingrese y en las indicaciones.
Después de iniciar la pila de punto final del modelo de generación de texto, complete los siguientes pasos:
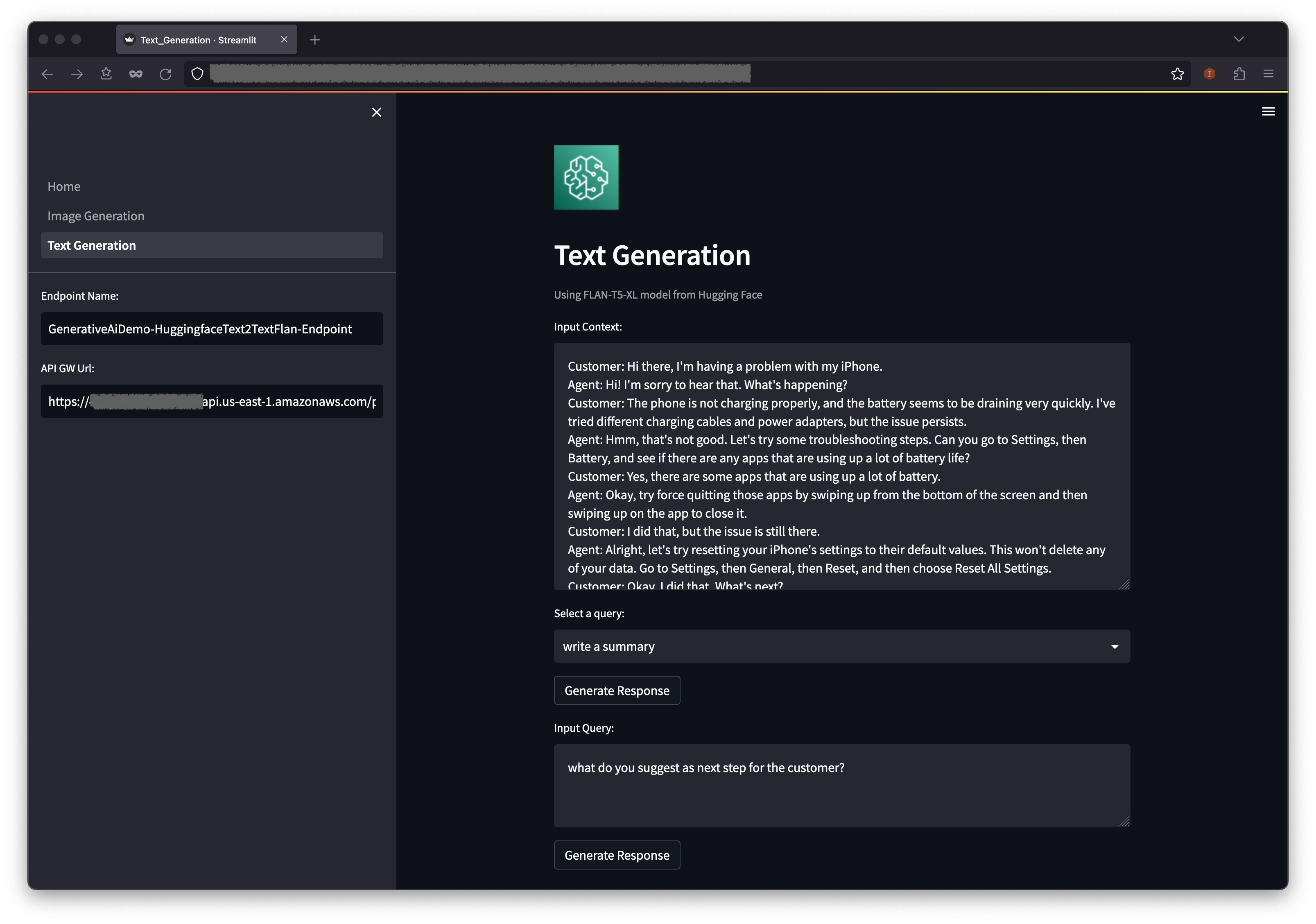
Debajo del contexto, encontrará algunas consultas prepobladas en las opciones de menú desplegable.
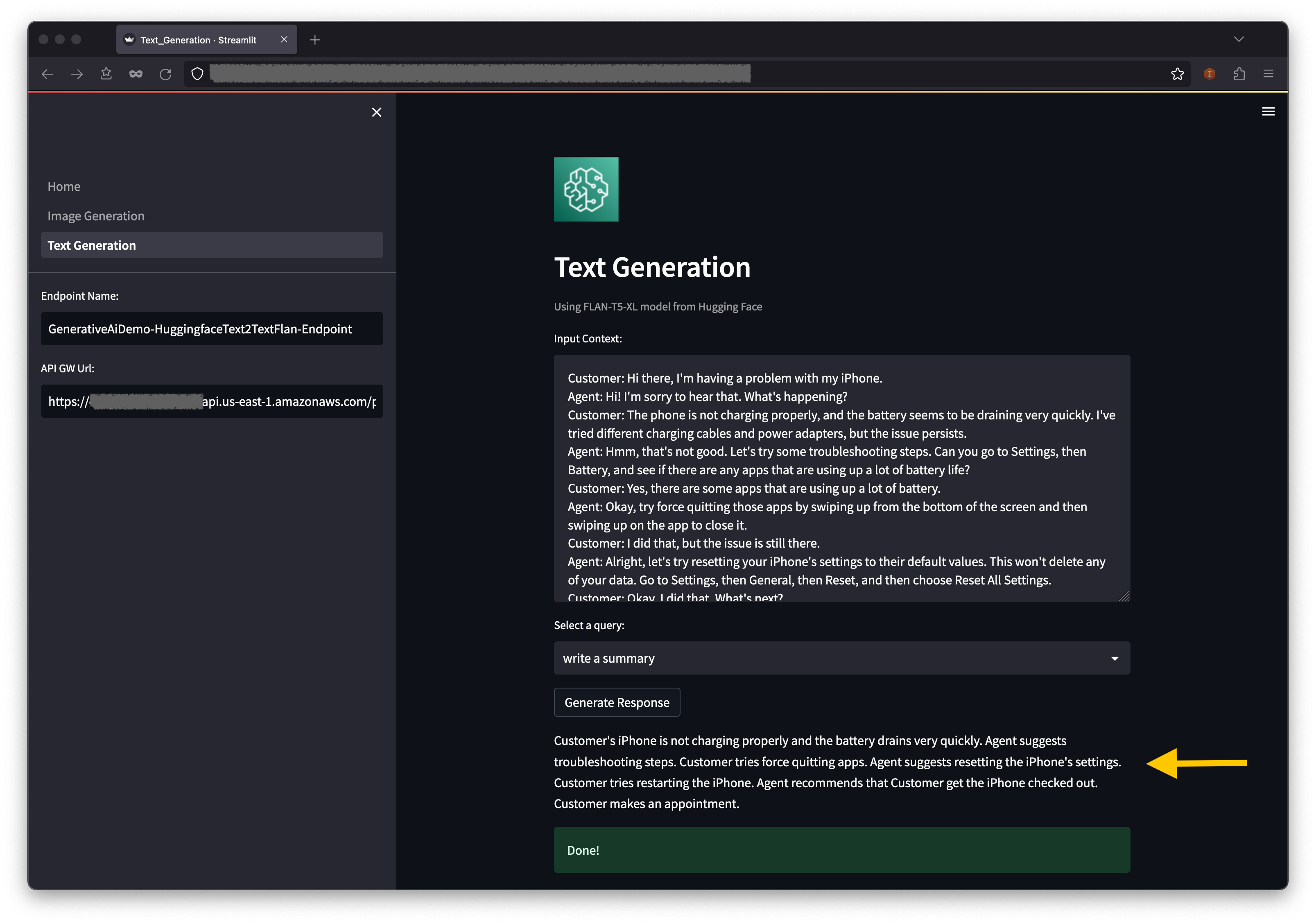
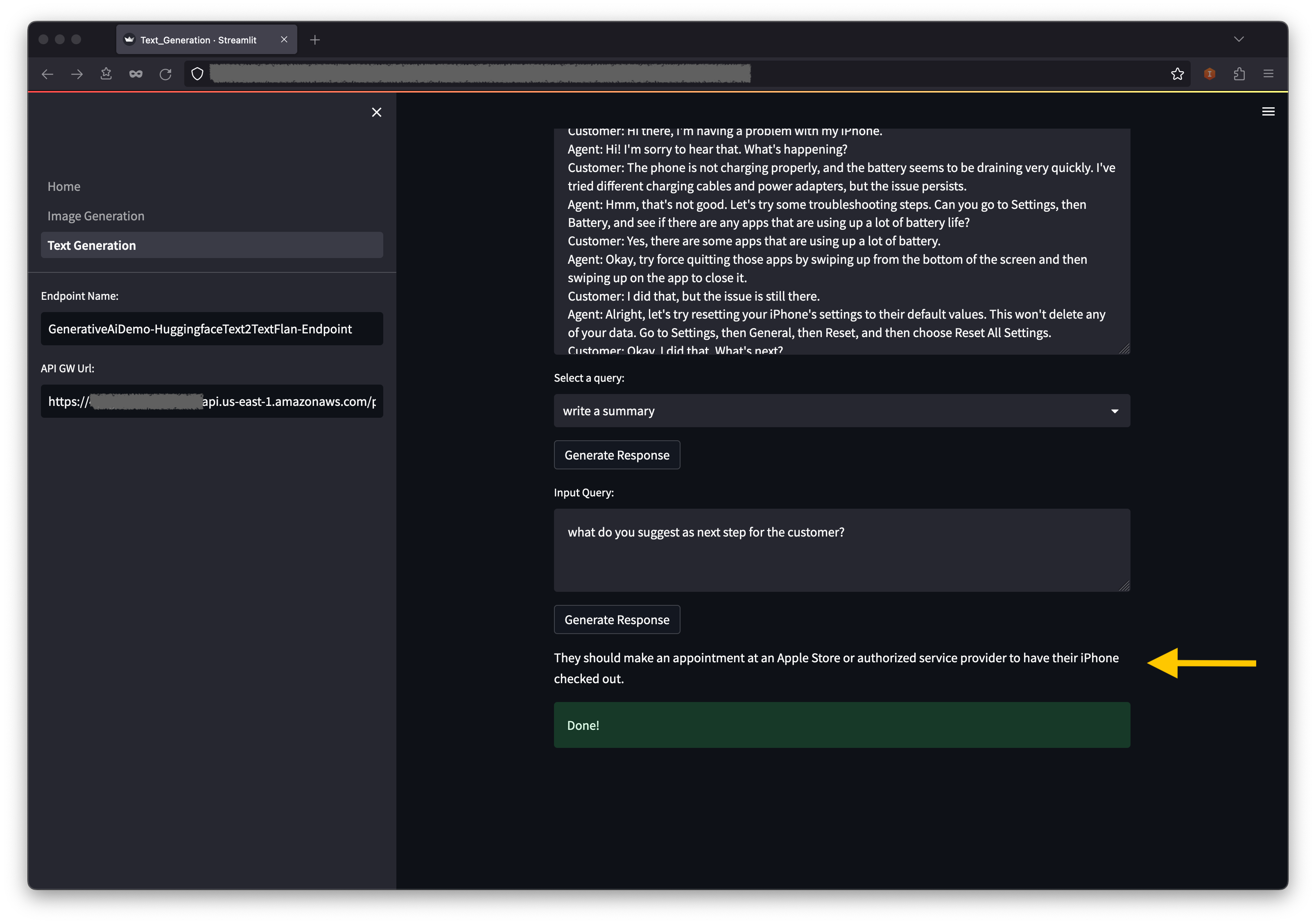
También puede ingresar su propia consulta en el campo de consulta de entrada y elegir generar respuesta .
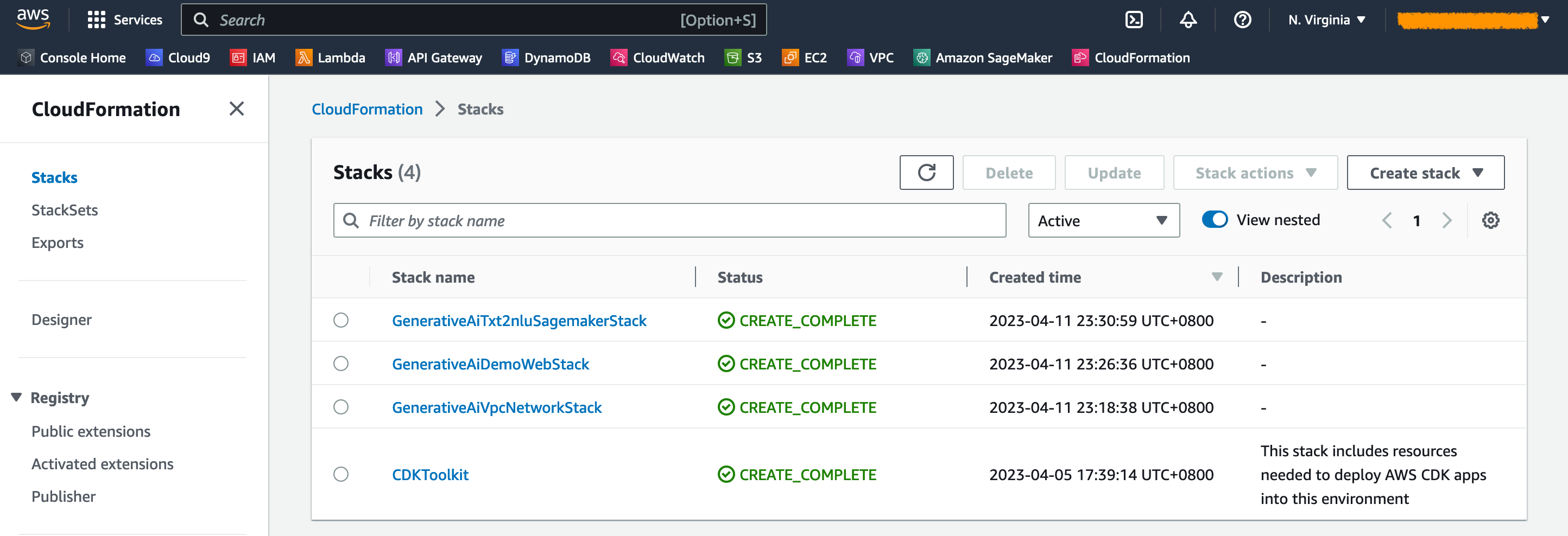
En la consola de AWS CloudFormation, elija Pilas en el panel de navegación para ver las pilas implementadas.
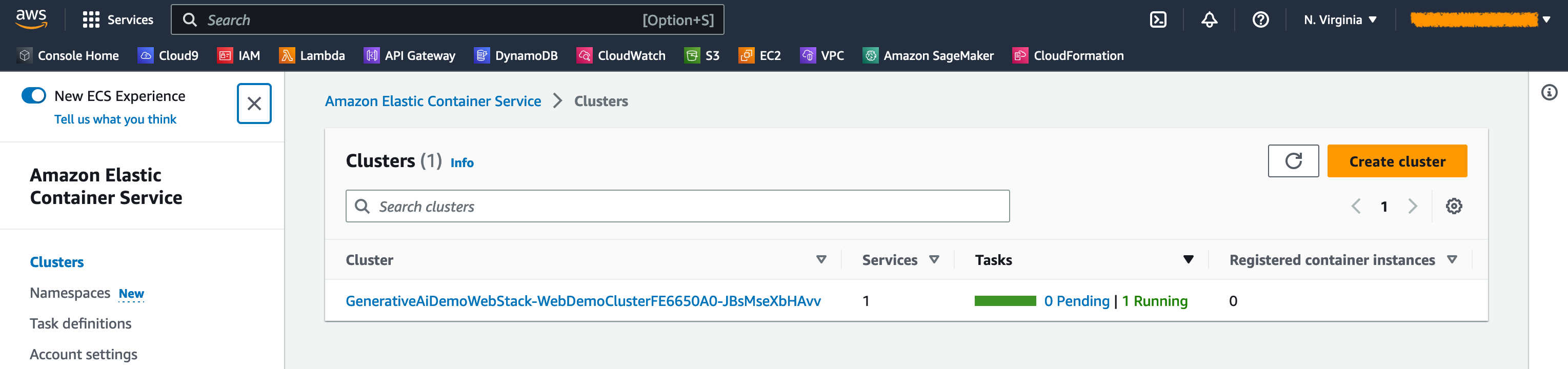
En la consola ECS de Amazon, puede ver los clústeres en la página de clústeres .
En la consola Lambda de AWS, puede ver las funciones en la página de funciones .
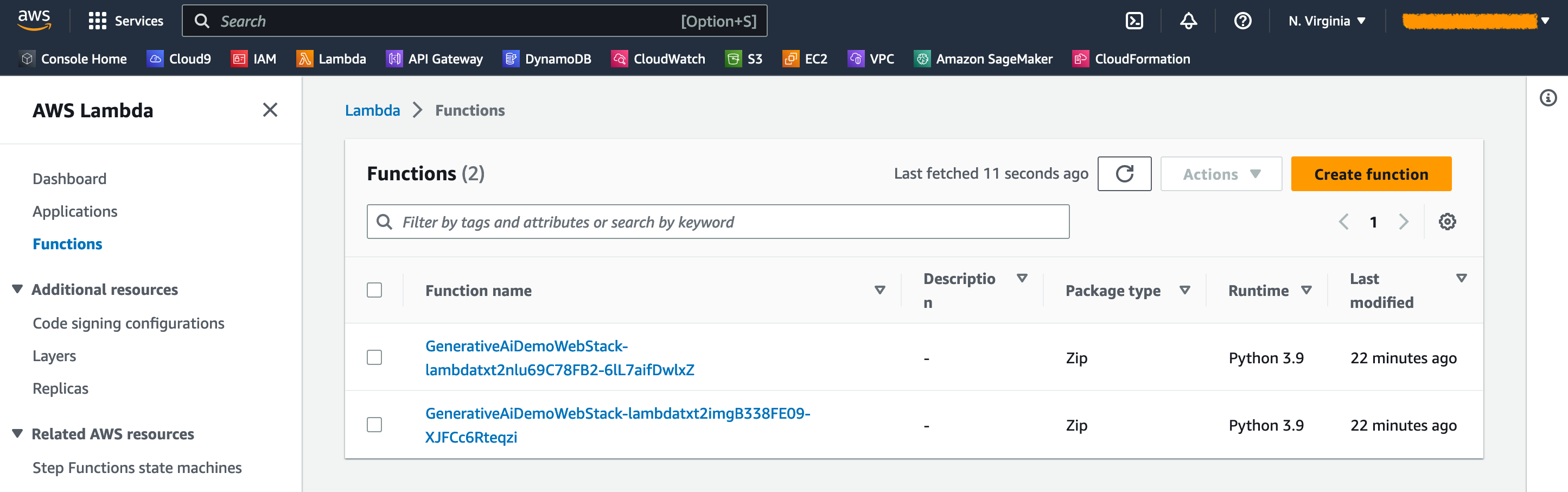
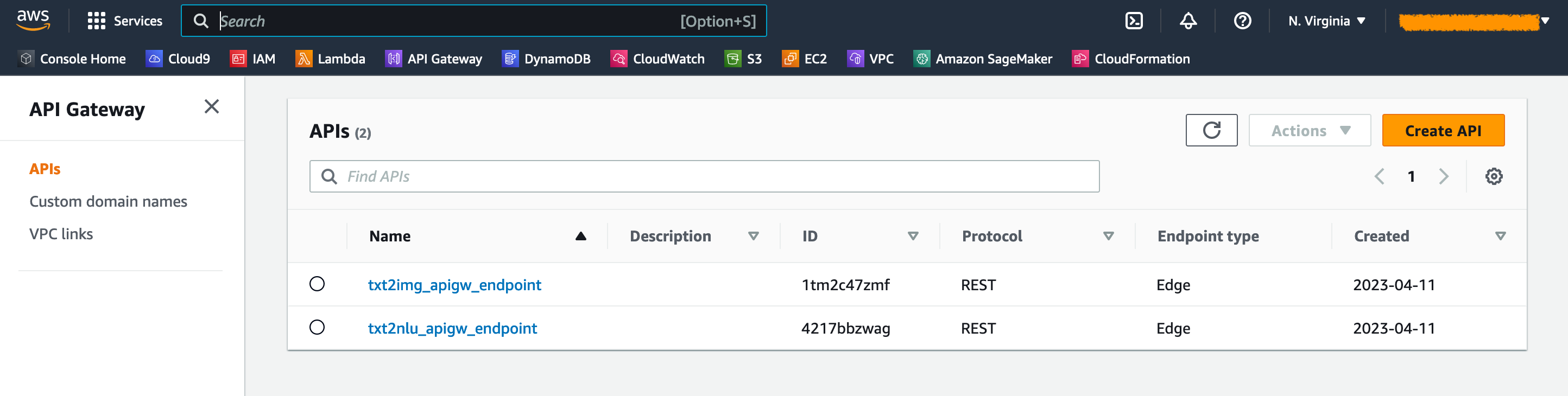
En la consola API Gateway, puede ver los puntos finales de API Gateway en la página API .
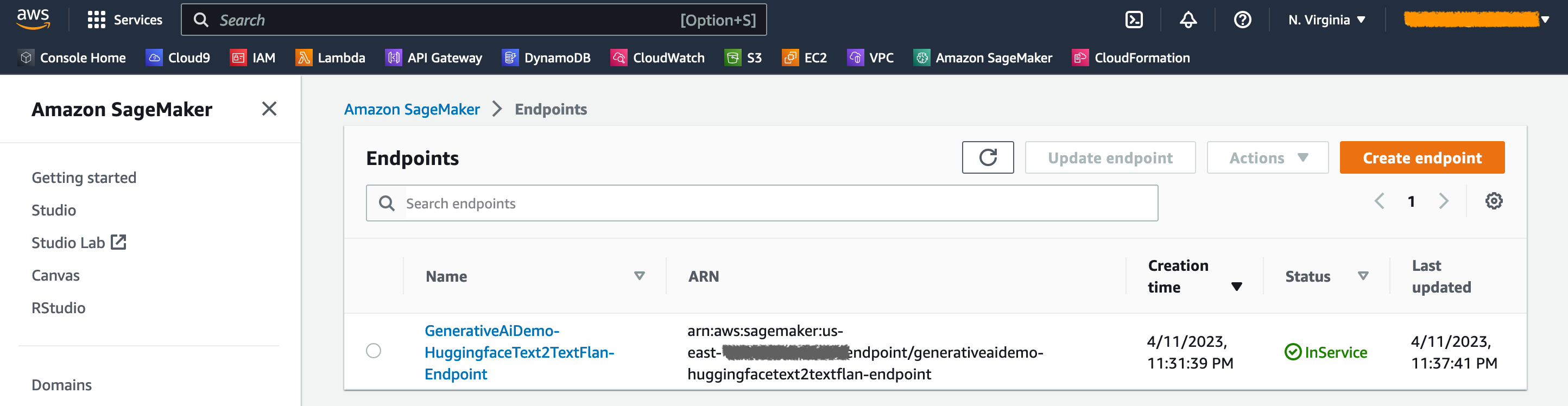
En la consola Sagemaker, puede ver los puntos finales del modelo implementado en la página de puntos finales .
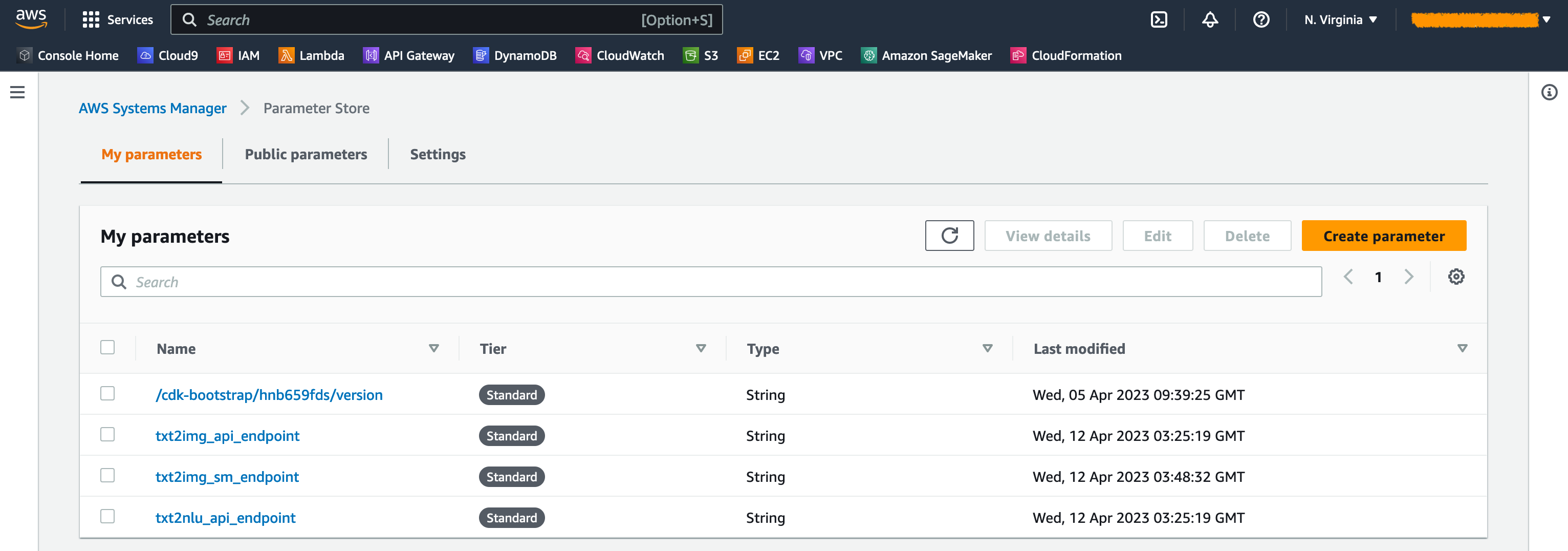
Cuando se lanzan las pilas, se generan algunos parámetros. Estos se almacenan en la tienda AWS Systems Manager Parameter. Para verlos, elija el almacén de parámetros en el panel de navegación en la consola del administrador de sistemas AWS.
Para evitar un costo innecesario, limpie toda la infraestructura creada con el siguiente comando en su estación de trabajo:
cdk destroy --all
Ingrese y en la solicitud. Este paso toma alrededor de 10 minutos. Compruebe si todos los recursos se eliminan en la consola. También elimine los activos de los cubos S3 creados por el AWS CDK en la consola Amazon S3, así como los repositorios de activos en Amazon ECR.
Como se demuestra en esta publicación, puede usar el AWS CDK para implementar modelos AI generativos en JumpStart. Mostramos un ejemplo de generación de imágenes y un ejemplo de generación de texto utilizando una interfaz de usuario alimentada por streylit, lambda y API Gateway.
Ahora puede construir sus proyectos de IA generativos utilizando modelos AI previamente capacitados en JumpStart. También puede extender este proyecto para ajustar los modelos de base para su caso de uso y controlar el acceso a los puntos finales de la puerta de enlace de la API.
Lo invitamos a probar la solución y contribuir al proyecto en GitHub.
Este código de muestra está disponible bajo una licencia MIT modificada. Consulte el archivo de licencia para obtener más información. Además, revise las licencias respectivas para la difusión estable y los modelos Flan-T5-XL en la cara abrazada.
Hantzley Taucucoor es un líder de arquitectura de soluciones asociadas de APJ con sede en Singapur. Tiene 20 años de experiencia en la industria de las TIC que abarca múltiples áreas funcionales, incluida la arquitectura de soluciones, el desarrollo de negocios, la estrategia de ventas, la consultoría y el liderazgo. Dirige un equipo de arquitectos senior de soluciones que permiten a los socios desarrollar soluciones conjuntas, desarrollar capacidades técnicas y dirigirlos a través de la fase de implementación a medida que los clientes migran y modernizan sus aplicaciones a AWS. El trabajo externo, le gusta pasar tiempo con su familia, ver películas y caminar.
Kwonyul Choi es un CTO en Babitalk, una startup de la plataforma de cuidado de belleza coreana, con sede en Seúl. Antes de este papel, Kownyul trabajó como ingeniero de desarrollo de software en AWS con un enfoque en AWS CDK y Amazon Sagemaker.
Arunprasath Shankar es un arquitecto senior de soluciones especializadas de IA/ML con AWS, ayudando a los clientes globales a escalar sus soluciones de IA de manera efectiva y eficiente en la nube. En su tiempo libre, a Arun le gusta ver películas de ciencia ficción y escuchar música clásica.
Satish Uplreti es un PSA líder en migración y PYME de seguridad en la organización asociada en APJ. Satish tiene 20 años de experiencia que abarcan tecnologías privadas de nubes privadas y nubes públicas. Desde que se unió a AWS en agosto de 2020 como especialista en migración, proporciona un amplio asesoramiento técnico y apoyo a los socios de AWS para planificar e implementar migraciones complejas.
En esta sección, proporcionamos una visión general del código en este proyecto.
Aplicación AWS CDK
La aplicación principal de AWS CDK está contenida en el archivo app.py en el directorio raíz. El proyecto consta de múltiples pilas, por lo que tenemos que importar las pilas:
#!/usr/bin/env python3
import aws_cdk as cdk
from stack . generative_ai_vpc_network_stack import GenerativeAiVpcNetworkStack
from stack . generative_ai_demo_web_stack import GenerativeAiDemoWebStack
from stack . generative_ai_txt2nlu_sagemaker_stack import GenerativeAiTxt2nluSagemakerStack
from stack . generative_ai_txt2img_sagemaker_stack import GenerativeAiTxt2imgSagemakerStackDefinimos nuestros modelos de IA generativos y obtenemos los URI relacionados de Sagemaker:
from script . sagemaker_uri import *
import boto3
region_name = boto3 . Session (). region_name
env = { "region" : region_name }
#Text to Image model parameters
TXT2IMG_MODEL_ID = "model-txt2img-stabilityai-stable-diffusion-v2-1-base"
TXT2IMG_INFERENCE_INSTANCE_TYPE = "ml.g4dn.4xlarge"
TXT2IMG_MODEL_TASK_TYPE = "txt2img"
TXT2IMG_MODEL_INFO = get_sagemaker_uris ( model_id = TXT2IMG_MODEL_ID ,
model_task_type = TXT2IMG_MODEL_TASK_TYPE ,
instance_type = TXT2IMG_INFERENCE_INSTANCE_TYPE ,
region_name = region_name )
#Text to NLU image model parameters
TXT2NLU_MODEL_ID = "huggingface-text2text-flan-t5-xl"
TXT2NLU_INFERENCE_INSTANCE_TYPE = "ml.g4dn.4xlarge"
TXT2NLU_MODEL_TASK_TYPE = "text2text"
TXT2NLU_MODEL_INFO = get_sagemaker_uris ( model_id = TXT2NLU_MODEL_ID ,
model_task_type = TXT2NLU_MODEL_TASK_TYPE ,
instance_type = TXT2NLU_INFERENCE_INSTANCE_TYPE ,
region_name = region_name ) La función get_sagemaker_uris recupera toda la información del modelo de Amazon JumpStart. Ver script/sagemaker_uri.py.
Luego, instanciamos las pilas:
app = cdk . App ()
network_stack = GenerativeAiVpcNetworkStack ( app , "GenerativeAiVpcNetworkStack" , env = env )
GenerativeAiDemoWebStack ( app , "GenerativeAiDemoWebStack" , vpc = network_stack . vpc , env = env )
GenerativeAiTxt2nluSagemakerStack ( app , "GenerativeAiTxt2nluSagemakerStack" , env = env , model_info = TXT2NLU_MODEL_INFO )
GenerativeAiTxt2imgSagemakerStack ( app , "GenerativeAiTxt2imgSagemakerStack" , env = env , model_info = TXT2IMG_MODEL_INFO )
app . synth () La primera pila que se lanzará es la pila VPC, GenerativeAiVpcNetworkStack . La pila de aplicaciones web, GenerativeAiDemoWebStack , depende de la pila VPC. La dependencia se realiza a través del parámetro que pasa vpc=network_stack.vpc .
Consulte App.py para ver el código completo.
Pila de red VPC
En la pila GenerativeAiVpcNetworkStack creamos una VPC con una subred pública y una subred privada que abarca dos zonas de disponibilidad (AZS):
self . output_vpc = ec2 . Vpc ( self , "VPC" ,
nat_gateways = 1 ,
ip_addresses = ec2 . IpAddresses . cidr ( "10.0.0.0/16" ),
max_azs = 2 ,
subnet_configuration = [
ec2 . SubnetConfiguration ( name = "public" , subnet_type = ec2 . SubnetType . PUBLIC , cidr_mask = 24 ),
ec2 . SubnetConfiguration ( name = "private" , subnet_type = ec2 . SubnetType . PRIVATE_WITH_EGRESS , cidr_mask = 24 )
]
)Consulte /stack/Generative_AI_VPC_NetWork_stack.py para el código completo.
Pila de aplicaciones web de demostración
En la pila GenerativeAiDemoWebStack lanzamos funciones Lambda y los respectivos puntos finales de puerta de enlace de la API de Amazon a través de los cuales la aplicación web interactúa con los puntos finales del modelo Sagemaker. Consulte el siguiente fragmento de código:
# Defines an AWS Lambda function for Image Generation service
lambda_txt2img = _lambda . Function (
self , "lambda_txt2img" ,
runtime = _lambda . Runtime . PYTHON_3_9 ,
code = _lambda . Code . from_asset ( "code/lambda_txt2img" ),
handler = "txt2img.lambda_handler" ,
role = role ,
timeout = Duration . seconds ( 180 ),
memory_size = 512 ,
vpc_subnets = ec2 . SubnetSelection (
subnet_type = ec2 . SubnetType . PRIVATE_WITH_EGRESS
),
vpc = vpc
)
# Defines an Amazon API Gateway endpoint for Image Generation service
txt2img_apigw_endpoint = apigw . LambdaRestApi (
self , "txt2img_apigw_endpoint" ,
handler = lambda_txt2img
)La aplicación web está contenedor y alojada en Amazon ECS con Fargate. Consulte el siguiente fragmento de código:
# Create Fargate service
fargate_service = ecs_patterns . ApplicationLoadBalancedFargateService (
self , "WebApplication" ,
cluster = cluster , # Required
cpu = 2048 , # Default is 256 (512 is 0.5 vCPU, 2048 is 2 vCPU)
desired_count = 1 , # Default is 1
task_image_options = ecs_patterns . ApplicationLoadBalancedTaskImageOptions (
image = image ,
container_port = 8501 ,
),
#load_balancer_name="gen-ai-demo",
memory_limit_mib = 4096 , # Default is 512
public_load_balancer = True ) # Default is TrueConsulte /stack/Generative_AI_Demo_Web_Stack.py para el código completo.
Pila de puntos finales del modelo sagemaker de generación de imágenes
La pila GenerativeAiTxt2imgSagemakerStack crea el punto final del modelo de generación de imágenes de Sagemaker JumpStart y almacena el nombre de punto final en la tienda AWS Systems Manager Parameter. Este parámetro será utilizado por la aplicación web. Vea el siguiente código:
endpoint = SageMakerEndpointConstruct ( self , "TXT2IMG" ,
project_prefix = "GenerativeAiDemo" ,
role_arn = role . role_arn ,
model_name = "StableDiffusionText2Img" ,
model_bucket_name = model_info [ "model_bucket_name" ],
model_bucket_key = model_info [ "model_bucket_key" ],
model_docker_image = model_info [ "model_docker_image" ],
variant_name = "AllTraffic" ,
variant_weight = 1 ,
instance_count = 1 ,
instance_type = model_info [ "instance_type" ],
environment = {
"MMS_MAX_RESPONSE_SIZE" : "20000000" ,
"SAGEMAKER_CONTAINER_LOG_LEVEL" : "20" ,
"SAGEMAKER_PROGRAM" : "inference.py" ,
"SAGEMAKER_REGION" : model_info [ "region_name" ],
"SAGEMAKER_SUBMIT_DIRECTORY" : "/opt/ml/model/code" ,
},
deploy_enable = True
)
ssm . StringParameter ( self , "txt2img_sm_endpoint" , parameter_name = "txt2img_sm_endpoint" , string_value = endpoint . endpoint_name )Ver /stack/Generative_AI_TXT2Img_SageMaker_stack.py para el código completo.
NLU y Generación de texto Sagemaker Modelo Endpoint Stack
La pila GenerativeAiTxt2nluSagemakerStack crea el punto final del modelo NLU y de generación de texto de JumpStart y almacena el nombre de punto final en Systems Manager Parameter Store. Este parámetro también será utilizado por la aplicación web. Vea el siguiente código:
endpoint = SageMakerEndpointConstruct ( self , "TXT2NLU" ,
project_prefix = "GenerativeAiDemo" ,
role_arn = role . role_arn ,
model_name = "HuggingfaceText2TextFlan" ,
model_bucket_name = model_info [ "model_bucket_name" ],
model_bucket_key = model_info [ "model_bucket_key" ],
model_docker_image = model_info [ "model_docker_image" ],
variant_name = "AllTraffic" ,
variant_weight = 1 ,
instance_count = 1 ,
instance_type = model_info [ "instance_type" ],
environment = {
"MODEL_CACHE_ROOT" : "/opt/ml/model" ,
"SAGEMAKER_ENV" : "1" ,
"SAGEMAKER_MODEL_SERVER_TIMEOUT" : "3600" ,
"SAGEMAKER_MODEL_SERVER_WORKERS" : "1" ,
"SAGEMAKER_PROGRAM" : "inference.py" ,
"SAGEMAKER_SUBMIT_DIRECTORY" : "/opt/ml/model/code/" ,
"TS_DEFAULT_WORKERS_PER_MODEL" : "1"
},
deploy_enable = True
)
ssm . StringParameter ( self , "txt2nlu_sm_endpoint" , parameter_name = "txt2nlu_sm_endpoint" , string_value = endpoint . endpoint_name )Ver /stack/Generative_AI_TXT2NLU_SAGEMAKER_STACK.py para el código completo.
La aplicación web
La aplicación web se encuentra en el directorio /Web-APP. Es una aplicación de transmisión que se envía según el DockerFile:
FROM --platform=linux/x86_64 python:3.9
EXPOSE 8501
WORKDIR /app
COPY requirements.txt ./requirements.txt
RUN pip3 install -r requirements.txt
COPY . .
CMD streamlit run Home.py
--server.headless true
--browser.serverAddress= "0.0.0.0"
--server.enableCORS false
--browser.gatherUsageStats falsePara obtener más información sobre Streamlit, consulte la documentación de Orexlit.


