generative ai sagemaker cdk demo
1.0.0
As sementes de uma mudança de paradigma de aprendizado de máquina (ML) existem há décadas, mas com a pronta disponibilidade de capacidade de computação praticamente infinita, uma proliferação maciça de dados e o rápido avanço das tecnologias de ML, os clientes entre os setores estão adotando rapidamente e utilizando tecnologias de ML para transformar seus negócios.
Recentemente, aplicativos generativos de IA capturaram a atenção e a imaginação de todos. Estamos realmente em um ponto de inflexão emocionante na adoção generalizada do ML, e acreditamos que toda experiência e aplicativo do cliente serão reinventados com IA generativa.
A IA generativa é um tipo de IA que pode criar novos conteúdos e idéias, incluindo conversas, histórias, imagens, vídeos e música. Como toda a IA, a IA generativa é alimentada por modelos de ML-modelos muito grandes pré-treinados em vastos corpora de dados e comumente chamados de modelos de fundação (FMS).
O tamanho e a natureza de uso geral das FMs os tornam diferentes dos modelos tradicionais de ML, que normalmente executam tarefas específicas, como analisar texto para sentimentos, classificar imagens e prever tendências.
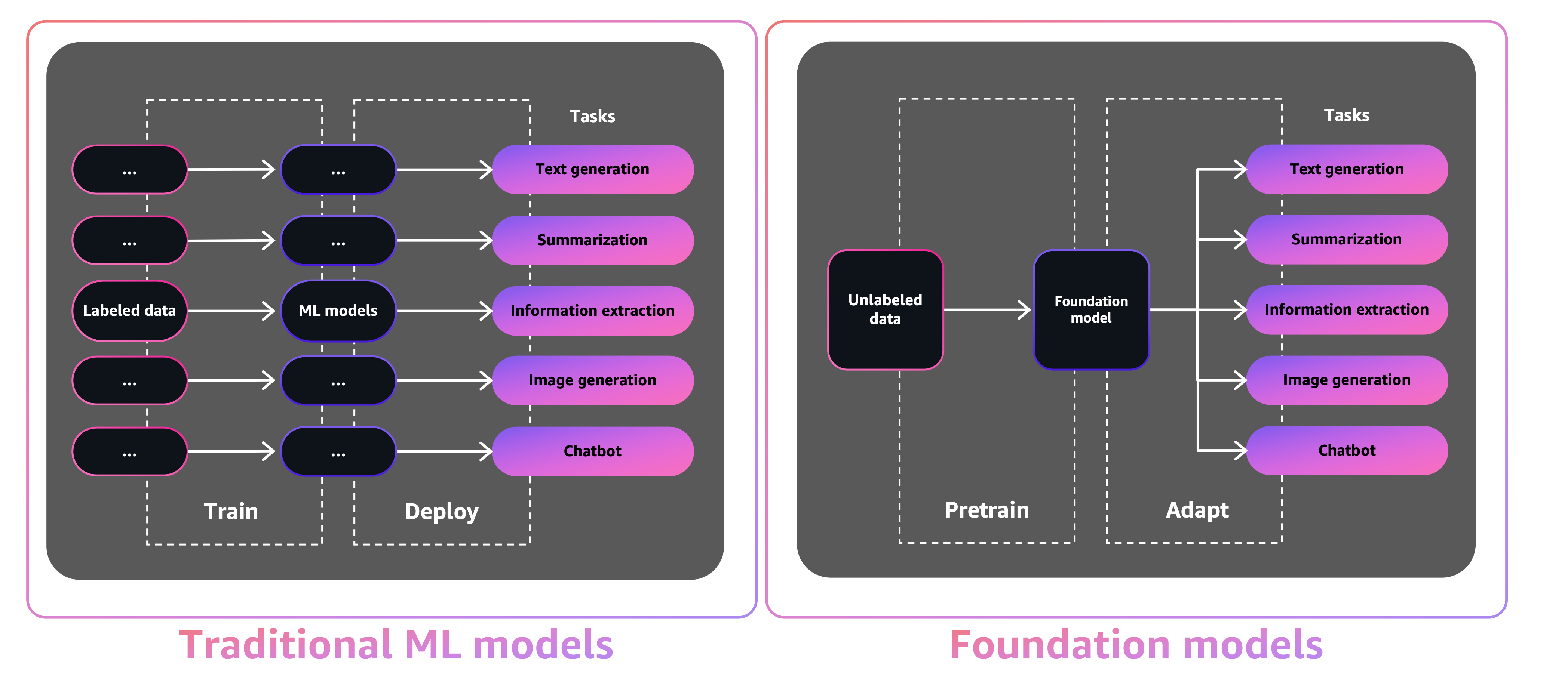
Com os modelos Tradition ML, para realizar cada tarefa específica, você precisa reunir dados rotulados, treinar um modelo e implantar esse modelo. Com os modelos de fundação, em vez de coletar dados rotulados para cada modelo e treinar vários modelos, você pode usar o mesmo FM pré-treinado para adaptar várias tarefas. Você também pode personalizar o FMS para executar funções específicas de domínio que estão diferenciando seus negócios, usando apenas uma pequena fração dos dados e computação necessários para treinar um modelo do zero.
A IA generativa tem o potencial de atrapalhar muitas indústrias, revolucionando a maneira como o conteúdo é criado e consumido. Produção de conteúdo original, geração de código, aprimoramento do atendimento ao cliente e resumo de documentos são casos de uso típicos de IA generativa.
O Amazon Sagemaker Jumpstart fornece modelos pré-treinados e de código aberto para uma ampla gama de tipos de problemas para ajudá-lo a começar com o ML. Você pode treinar e ajustar incrementalmente esses modelos antes da implantação. O Jumpstart também fornece modelos de solução que configuram infraestrutura para casos de uso comum e notebooks de exemplo executáveis para ML com a Amazon Sagemaker.
Com mais de 600 modelos pré-treinados disponíveis e crescendo todos os dias, o JumpStart permite que os desenvolvedores incorporem rápida e facilmente técnicas de ML de ponta em seus fluxos de trabalho de produção. Você pode acessar os modelos pré-treinados, modelos de solução e exemplos através da página de destino do Jumpstart no Amazon Sagemaker Studio. Você também pode acessar os modelos Jumpstart usando o Sagemaker Python SDK. Para obter informações sobre como usar os modelos Jumpstart programaticamente, consulte Use Sagemaker Jumpstart Algoritmos com modelos pré -criados.
Em abril de 2023, a AWS revelou a Amazon Bedrock, que fornece uma maneira de criar aplicativos generativos de IA por meio de modelos pré-treinados de startups, incluindo AI21 Labs, Aipic e AI de estabilidade. A Amazon Bedrock também oferece acesso aos Modelos da Fundação Titan, uma família de modelos treinados internamente pela AWS. Com a experiência sem servidor do Amazon Bedrock, você pode encontrar facilmente o modelo certo para suas necessidades, começar rapidamente, personalizar privadamente o FMS com seus próprios dados e integrá -los facilmente e implantá -los em seus aplicativos usando as ferramentas e recursos da AWS, sem que você gerencie com que os modelos de sagema de sagema de sagema de sagema de sagema de sagema de sagema de sagema de sagema de sagema de sagema de sagema de sagema de sagema para o sagema de sagema de sagema para o sagmaker.
Nesta postagem, mostramos como implantar modelos de IA generativos de imagem e texto do JumpStart usando o Kit de Desenvolvimento de Cloud AWS (AWS CDK). O AWS CDK é uma estrutura de desenvolvimento de software de código aberto para definir seus recursos de aplicativos em nuvem usando linguagens de programação familiares como o Python.
Usamos o modelo de difusão estável para geração de imagens e o modelo Flan-T5-XL para entendimento da linguagem natural (NLU) e geração de texto de abraçar o rosto no Jumpstart.
O aplicativo da Web é construído no Streamlit, uma biblioteca Python de código aberto que facilita a criação e o compartilhamento de aplicativos da Web personalizados e bonitos para ML e ciência de dados. Host o aplicativo da Web usando o Amazon Elastic Container Service (Amazon ECS) com a AWS Fargate e ele é acessado por meio de um balanceador de carga de aplicativos. Fargate é uma tecnologia que você pode usar com o Amazon ECS para executar contêineres sem precisar gerenciar servidores ou clusters ou máquinas virtuais. Os pontos finais generativos do modelo de IA são lançados a partir de imagens Jumpstart no Amazon Elastic Container Registry (Amazon ECR). Os dados do modelo são armazenados no Amazon Simple Storage Service (Amazon S3) na conta Jumpstart. O aplicativo da Web interage com os modelos via Amazon API Gateway e as funções da AWS Lambda, como mostrado no diagrama a seguir.
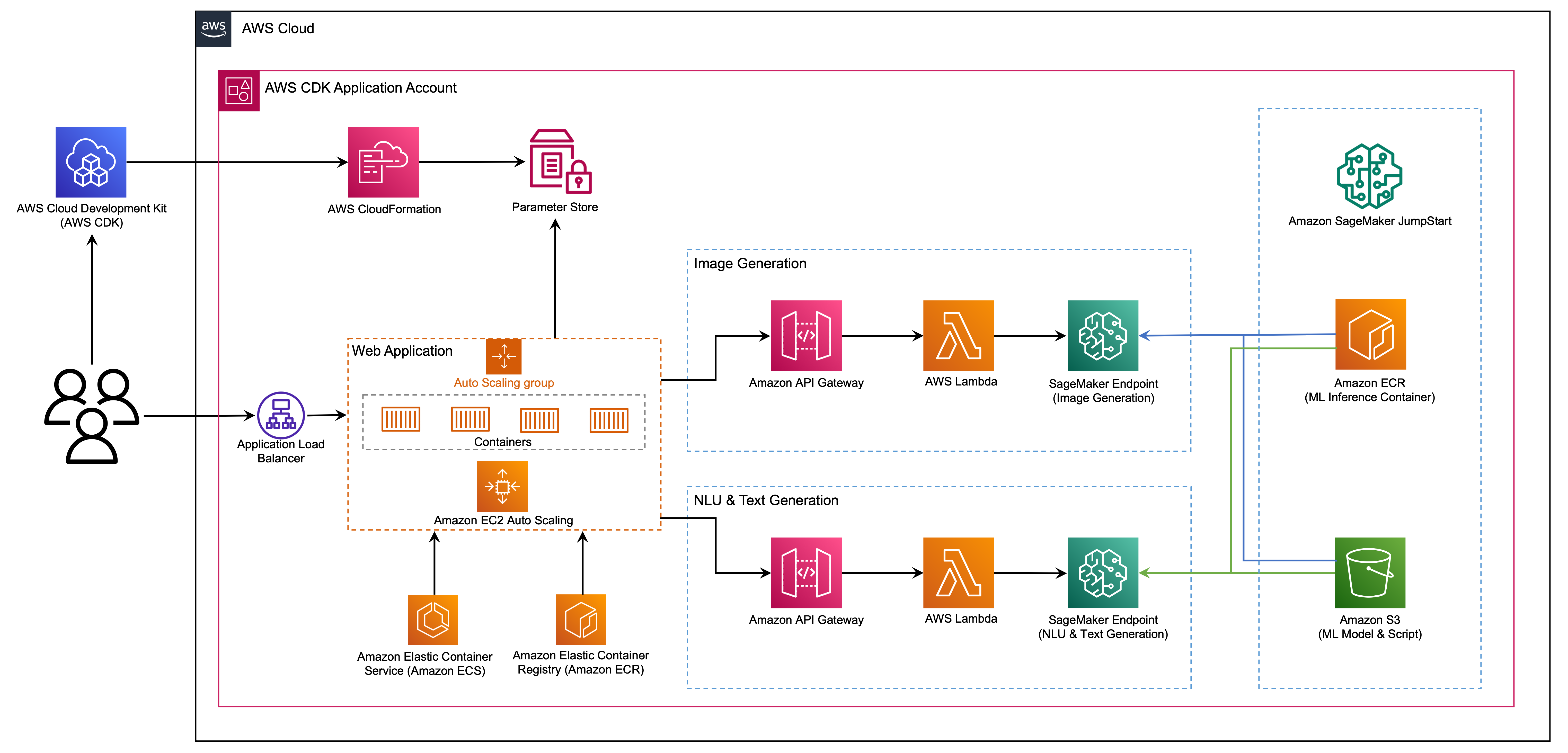
O API Gateway fornece ao aplicativo da Web e a outros clientes uma interface RESTful padrão, enquanto protege as funções Lambda que fazem interface com o modelo. Isso simplifica o código do aplicativo do cliente que consome os modelos. Os terminais do gateway da API são acessíveis ao público neste exemplo, permitindo a possibilidade de estender essa arquitetura para implementar diferentes controles de acesso à API e integrar -se a outros aplicativos.
Neste post, orientamos você pelas seguintes etapas:
Fornecemos uma visão geral do código neste projeto no apêndice no final desta postagem.
Você deve ter os seguintes pré -requisitos:
Você pode implantar a infraestrutura neste tutorial do seu computador local ou pode usar o AWS Cloud9 como sua estação de trabalho de implantação. O AWS Cloud9 vem pré-carregado com AWS CLI, AWS CDK e Docker. Se você optar pelo AWS Cloud9, crie o ambiente a partir do console da AWS.
O custo estimado para concluir esta postagem é de US $ 50, supondo que você deixe os recursos em execução por 8 horas. Certifique -se de excluir os recursos que você cria nesta postagem para evitar cobranças contínuas.
Se você ainda não possui a CLI da AWS em sua máquina local, consulte a instalação ou atualização da versão mais recente da AWS CLI e configurando a AWS CLI.
Instale o AWS CDK Toolkit usando o seguinte comando Node Package Manager:
npm install -g aws-cdk-lib@latest
Execute o seguinte comando para verificar a instalação correta e imprima o número da versão do AWS CDK:
cdk --version
Verifique se você está instalado no Docker em sua máquina local. Emitir o seguinte comando para verificar a versão:
docker --version
Na sua máquina local, clone o aplicativo AWS CDK com o seguinte comando:
git clone https://github.com/aws-samples/generative-ai-sagemaker-cdk-demo.git
Navegue até a pasta do projeto:
cd generative-ai-sagemaker-cdk-demo
Antes de implantarmos o aplicativo, vamos revisar a estrutura do diretório:
.
├── LICENSE
├── README.md
├── app.py
├── cdk.json
├── code
│ ├── lambda_txt2img
│ │ └── txt2img.py
│ └── lambda_txt2nlu
│ └── txt2nlu.py
├── construct
│ └── sagemaker_endpoint_construct.py
├── images
│ ├── architecture.png
│ ├── ...
├── requirements-dev.txt
├── requirements.txt
├── source.bat
├── stack
│ ├── __init__.py
│ ├── generative_ai_demo_web_stack.py
│ ├── generative_ai_txt2img_sagemaker_stack.py
│ ├── generative_ai_txt2nlu_sagemaker_stack.py
│ └── generative_ai_vpc_network_stack.py
├── tests
│ ├── __init__.py
│ └── ...
└── web-app
├── Dockerfile
├── Home.py
├── configs.py
├── img
│ └── sagemaker.png
├── pages
│ ├── 2_Image_Generation.py
│ └── 3_Text_Generation.py
└── requirements.txt A pasta de stack contém o código para cada pilha no aplicativo AWS CDK. A pasta de code contém o código para as funções da Amazon Lambda. O repositório também contém o aplicativo da Web localizado no web-app da pasta.
O arquivo cdk.json informa ao AWS CDK Toolkit como executar seu aplicativo.
Este aplicativo foi testado na região us-east-1 , mas deve funcionar em qualquer região que tenha os serviços e a instância de inferência necessários tipo ml.g4dn.4xlarge especificado em app.py.
Este projeto é configurado como um projeto Python padrão. Crie um ambiente virtual do Python usando o seguinte código:
python3 -m venv .venv
Use o seguinte comando para ativar o ambiente virtual:
source .venv/bin/activate
Se você estiver em uma plataforma Windows, ative o ambiente virtual da seguinte maneira:
.venvScriptsactivate.bat
Depois que o ambiente virtual é ativado, atualize o PIP para a versão mais recente:
python3 -m pip install --upgrade pip
Instale as dependências necessárias:
pip install -r requirements.txt
Antes de implantar qualquer aplicativo AWS CDK, você precisa inicializar um espaço em sua conta e na região em que você está implantando. Para inicializar na sua região padrão, emita o seguinte comando:
cdk bootstrap
Se você deseja implantar em uma conta e região específicas, emita o seguinte comando:
cdk bootstrap aws://ACCOUNT-NUMBER/REGION
Para obter mais informações sobre essa configuração, visite o início do AWS CDK.
O aplicativo AWS CDK contém várias pilhas, como mostrado no diagrama a seguir.
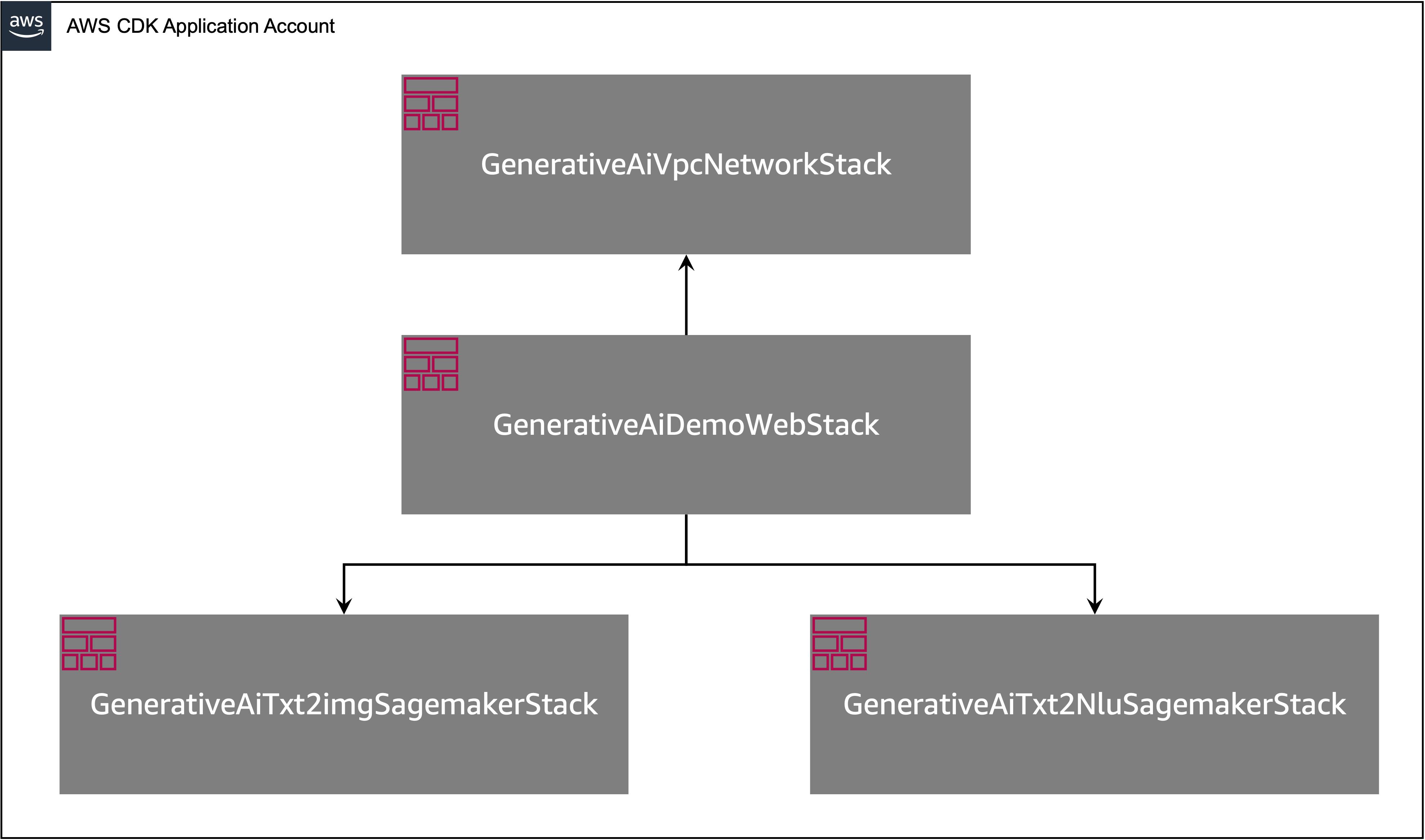
Você pode listar pilhas no seu aplicativo CDK com o seguinte comando:
cdk listVocê deve obter a seguinte saída:
GenerativeAiTxt2imgSagemakerStack
GenerativeAiTxt2nluSagemakerStack
GenerativeAiVpcNetworkStack
GenerativeAiDemoWebStack
Outros comandos úteis da AWS CDK:
cdk ls - lista todas as pilhas no aplicativocdk synth - Emite o modelo de Formação de Cloud Synthesized AWScdk deploy - implanta esta pilha na sua conta e região padrão da AWScdk diff - compara a pilha implantada com o estado atualcdk docs - abre a documentação da AWS CDKA próxima seção mostra como implantar o aplicativo AWS CDK.
O aplicativo AWS CDK será implantado na região padrão com base na sua configuração de estação de trabalho. Se você deseja forçar a implantação em uma região específica, defina sua variável de ambiente AWS_DEFAULT_REGION de acordo.
Neste ponto, você pode implantar o aplicativo AWS CDK. Primeiro, você inicia a pilha de rede VPC:
cdk deploy GenerativeAiVpcNetworkStack
Se você for solicitado, insira y a prosseguir com a implantação. Você deve ver uma lista de recursos da AWS que estão sendo provisionados na pilha. Esta etapa leva cerca de 3 minutos para ser concluída.
Em seguida, você inicia a pilha de aplicativos da web:
cdk deploy GenerativeAiDemoWebStack
Depois de analisar a pilha, o AWS CDK exibirá a lista de recursos na pilha. Digite y para prosseguir com a implantação. Esta etapa leva cerca de 5 minutos.
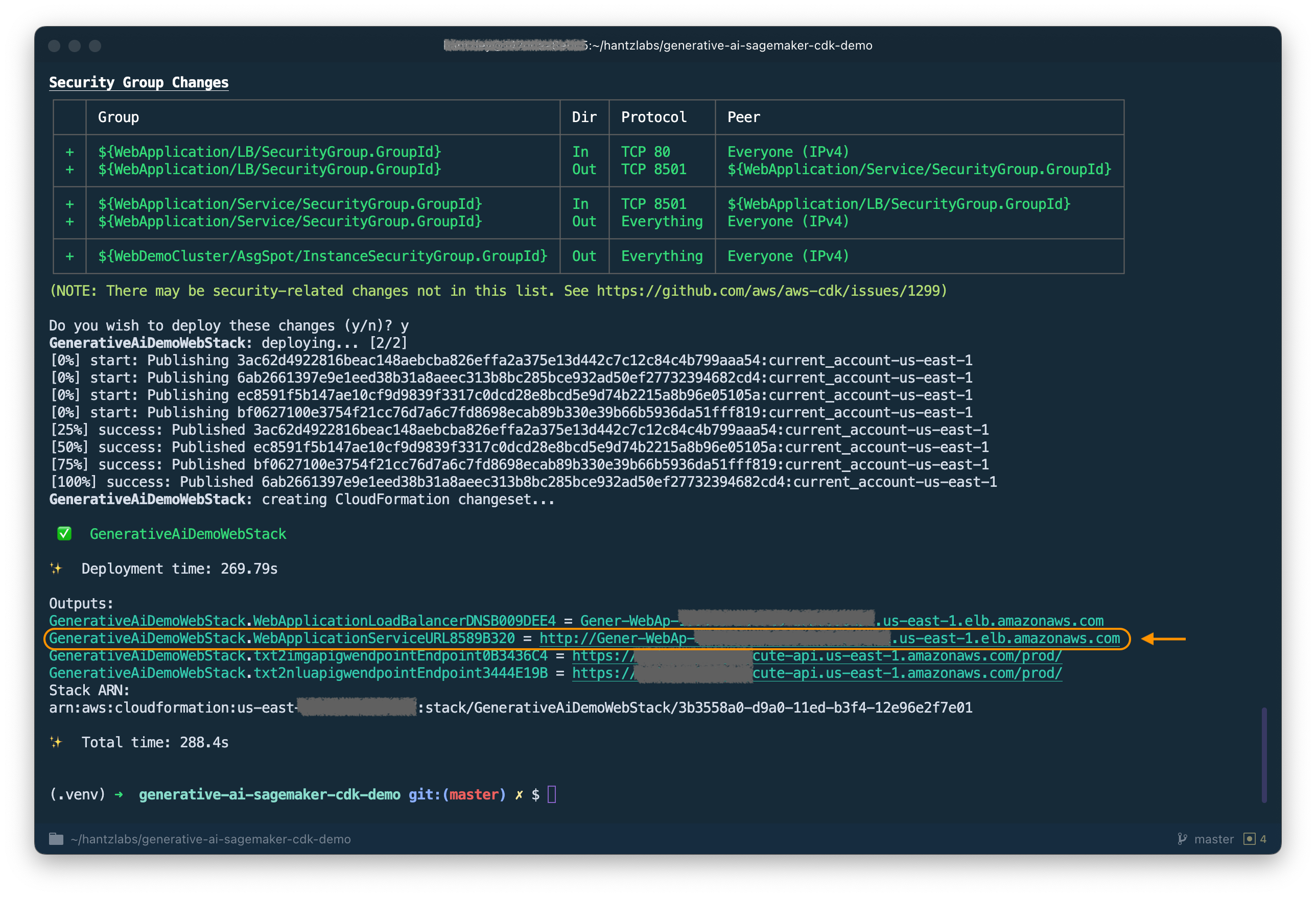
Anote o WebApplicationServiceURL da saída como você o usará mais tarde. Você também pode recuperá -lo posteriormente no console de formação de nuvem, sob as saídas do GenerativeAiDemoWebStack .
Agora, inicie a pilha de terminais do modelo da geração de imagens:
cdk deploy GenerativeAiTxt2imgSagemakerStack
Esta etapa leva cerca de 8 minutos. O ponto final do modelo de geração de imagem é implantado, agora podemos usá -lo.
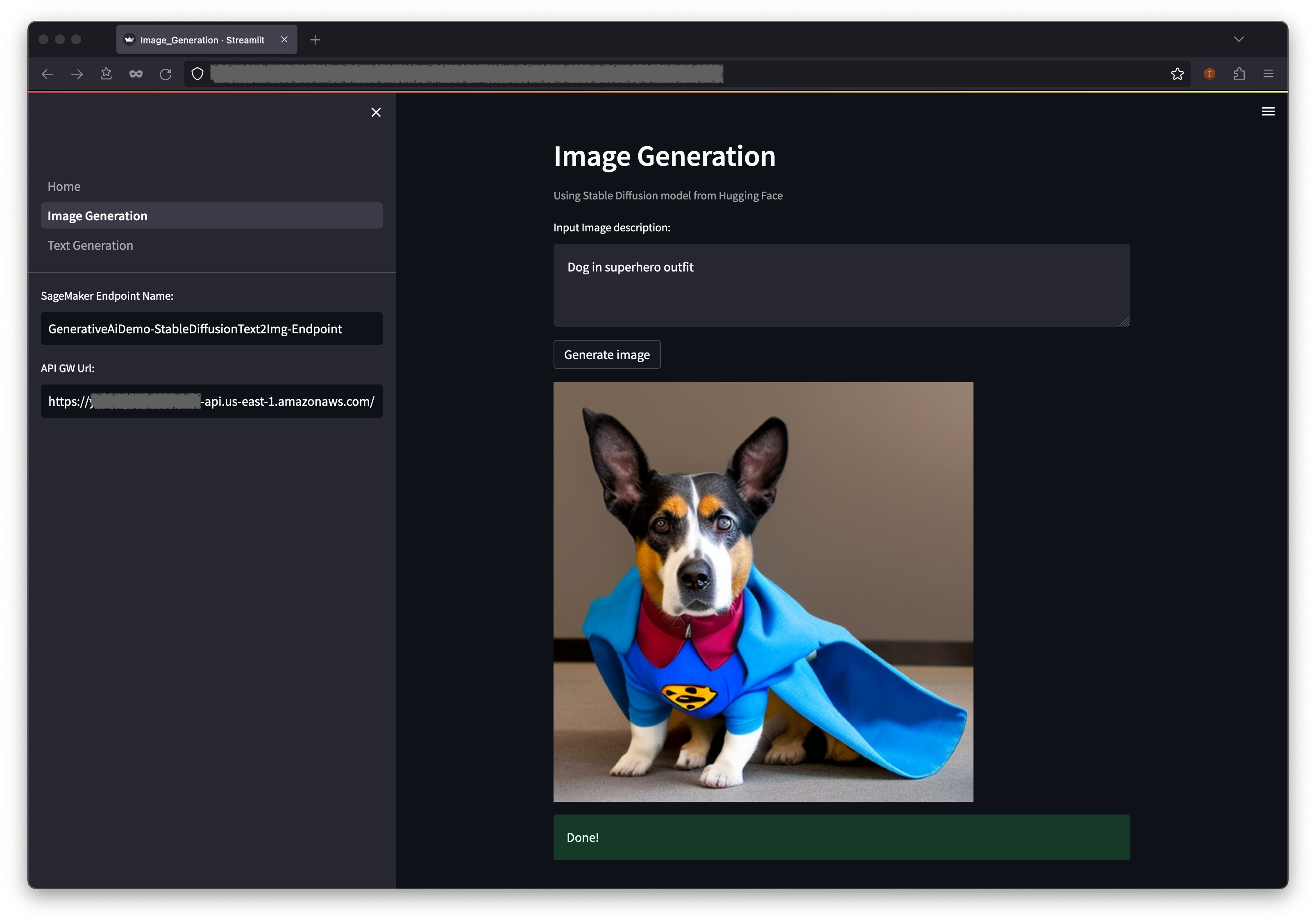
O primeiro exemplo demonstra como utilizar difusão estável, uma poderosa técnica de modelagem generativa que permite a criação de imagens de alta qualidade a partir de avisos de texto.
WebApplicationServiceURL a partir da saída do GenerativeAiDemoWebStack no seu navegador. 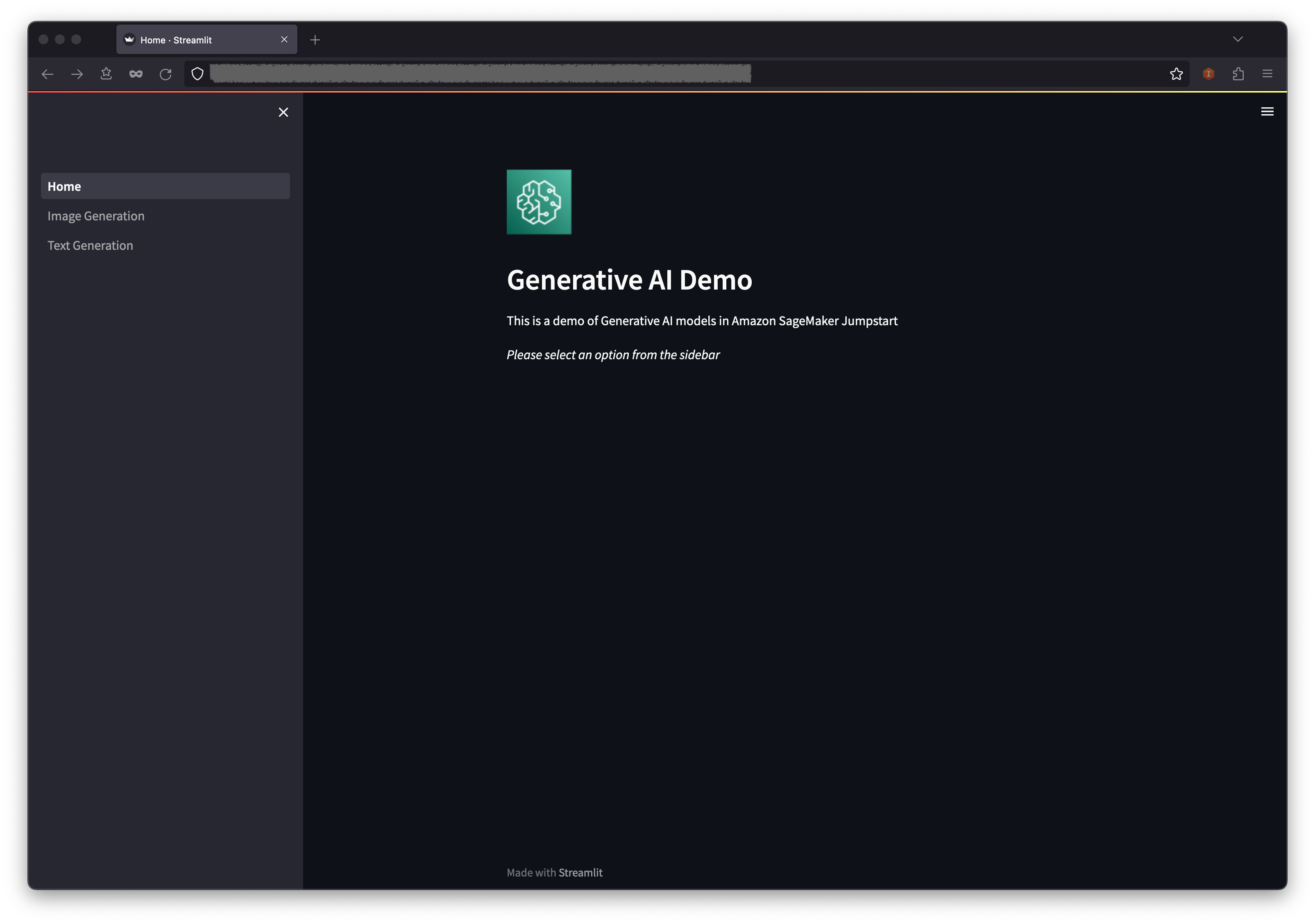
No painel de navegação, escolha a geração de imagens .
Os campos de URL do Sagemaker Endpoint e API GW URL serão pré-populados, mas você pode alterar o prompt para a descrição da imagem, se quiser.
Escolha gerar imagem .
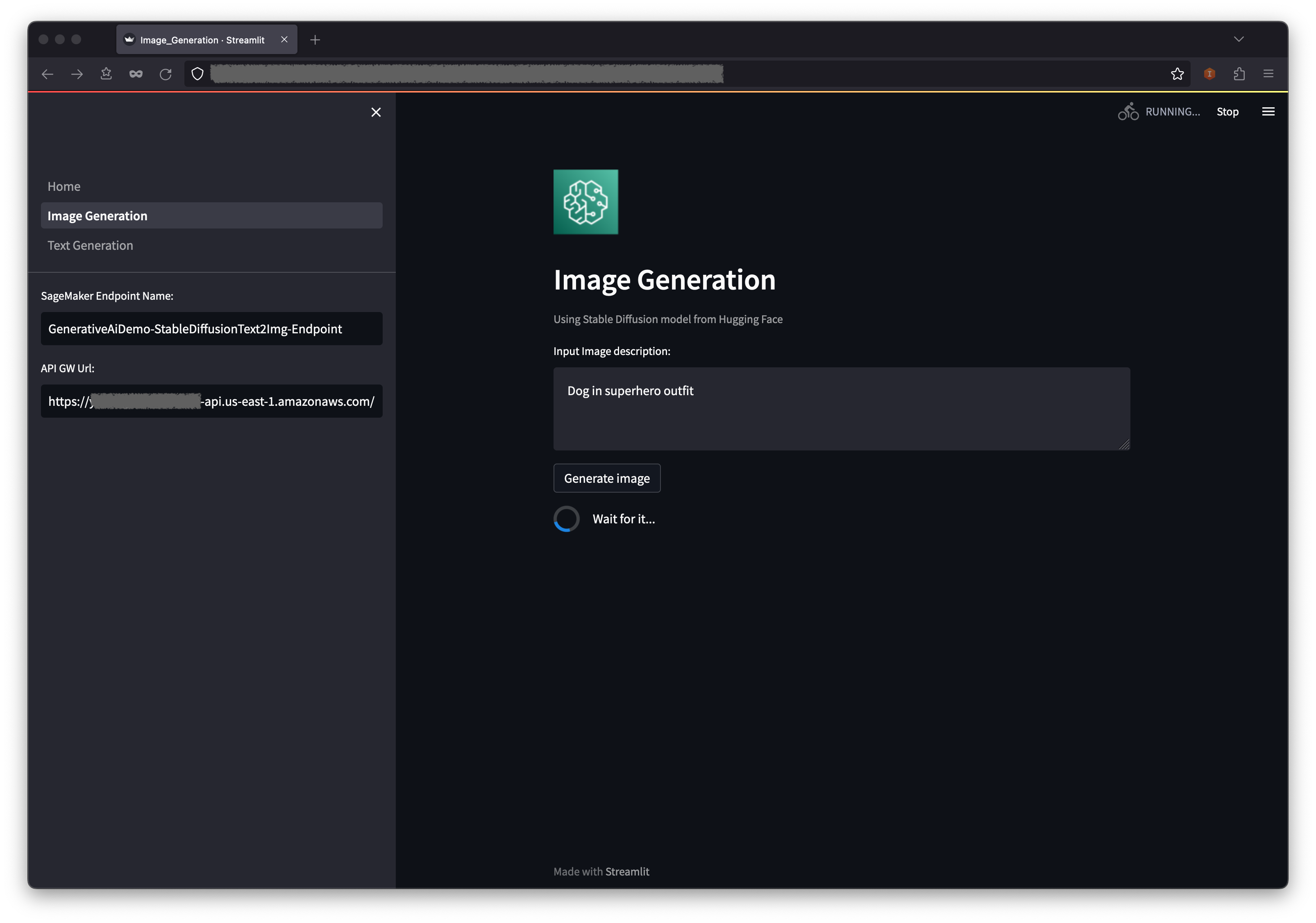
O aplicativo fará uma chamada para o terminal de sagemaker. Leva alguns segundos. Uma imagem com a descrição de Charasteristics na sua imagem será exibida.
O segundo exemplo se concentra no uso do modelo FLAN-T5-XL, que é um modelo de base ou grande idioma (LLM), para obter aprendizado no contexto para geração de texto, além de abordar uma ampla gama de tarefas de compreensão da linguagem natural (NLU) e geração de linguagem natural (NLG).
Alguns ambientes podem limitar o número de pontos de extremidade que você pode ser lançado por vez. Se for esse o caso, você pode iniciar um terminal de sagemaker por vez. Para interromper um terminal de sagemaker no aplicativo AWS CDK, você deve destruir a pilha de terminais implantados e antes de lançar a outra pilha de terminais. Para recusar o terminal do modelo de geração de imagem, emita o seguinte comando:
cdk destroy GenerativeAiTxt2imgSagemakerStack
Em seguida, inicie a pilha de terminais do modelo de geração de texto:
cdk deploy GenerativeAiTxt2nluSagemakerStack
Digite y nos prompts.
Após o lançamento da pilha de terminais do modelo de geração de texto, complete as seguintes etapas:
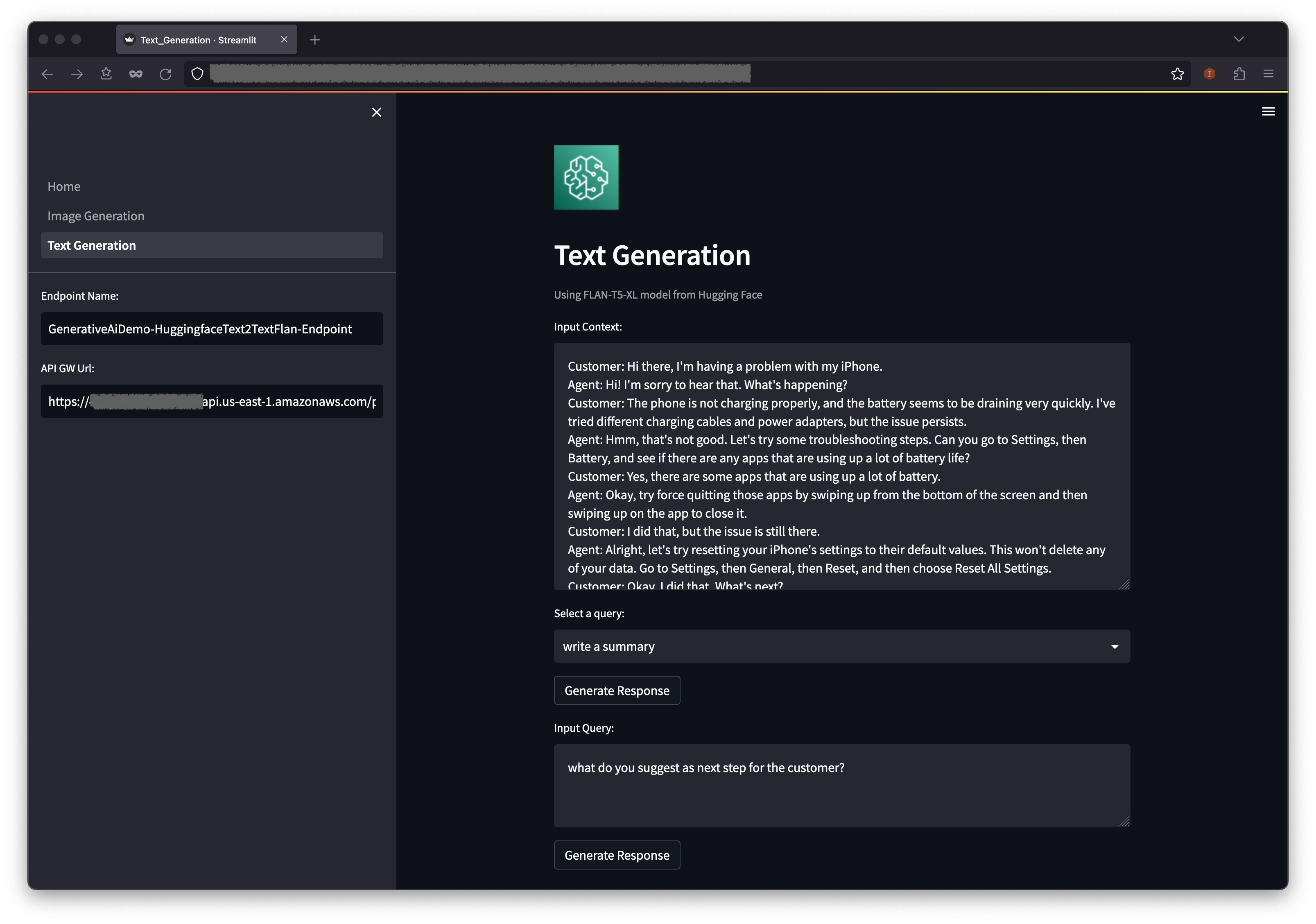
Abaixo do contexto, você encontrará algumas consultas preparadas nas opções de menu suspenso.
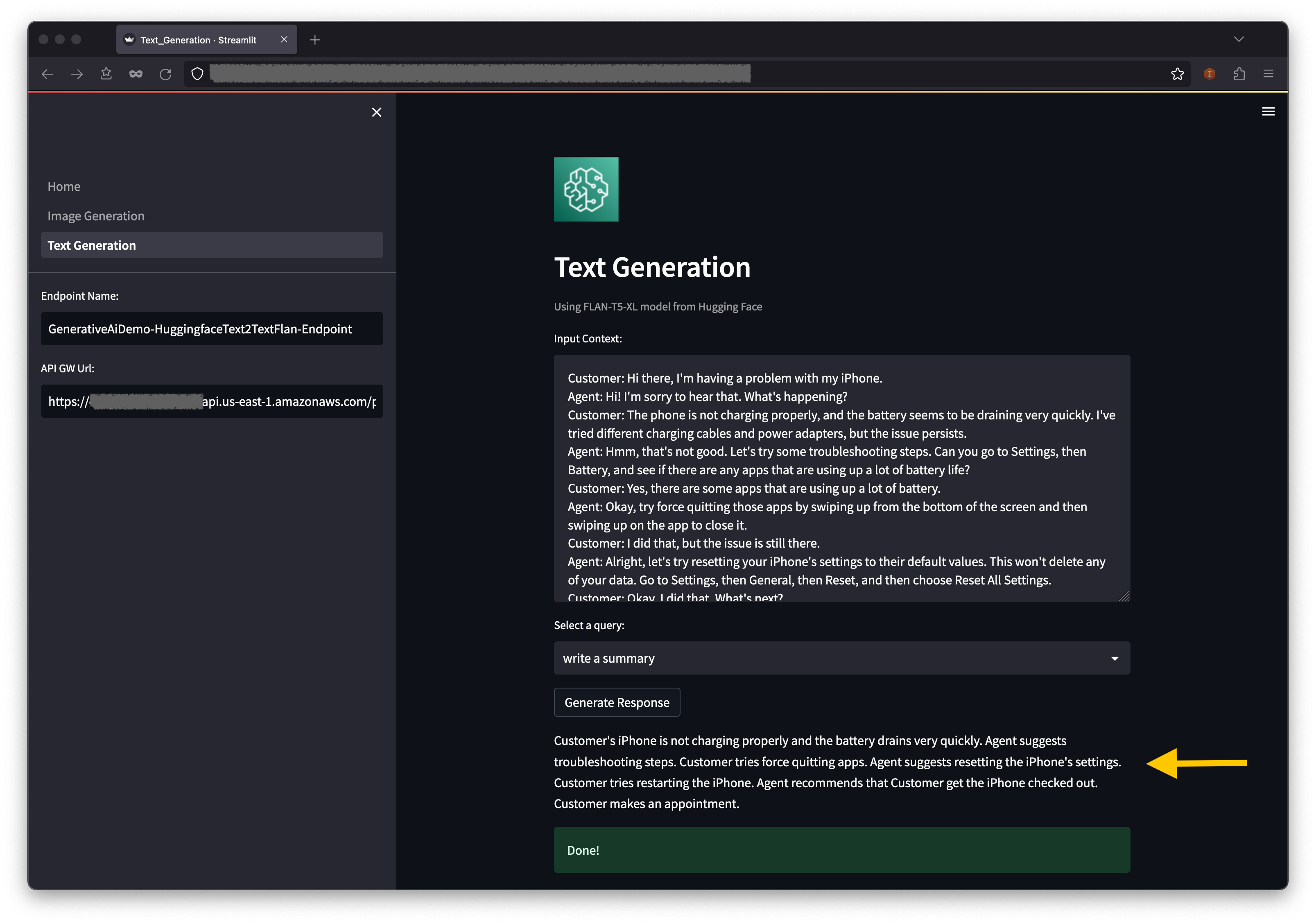
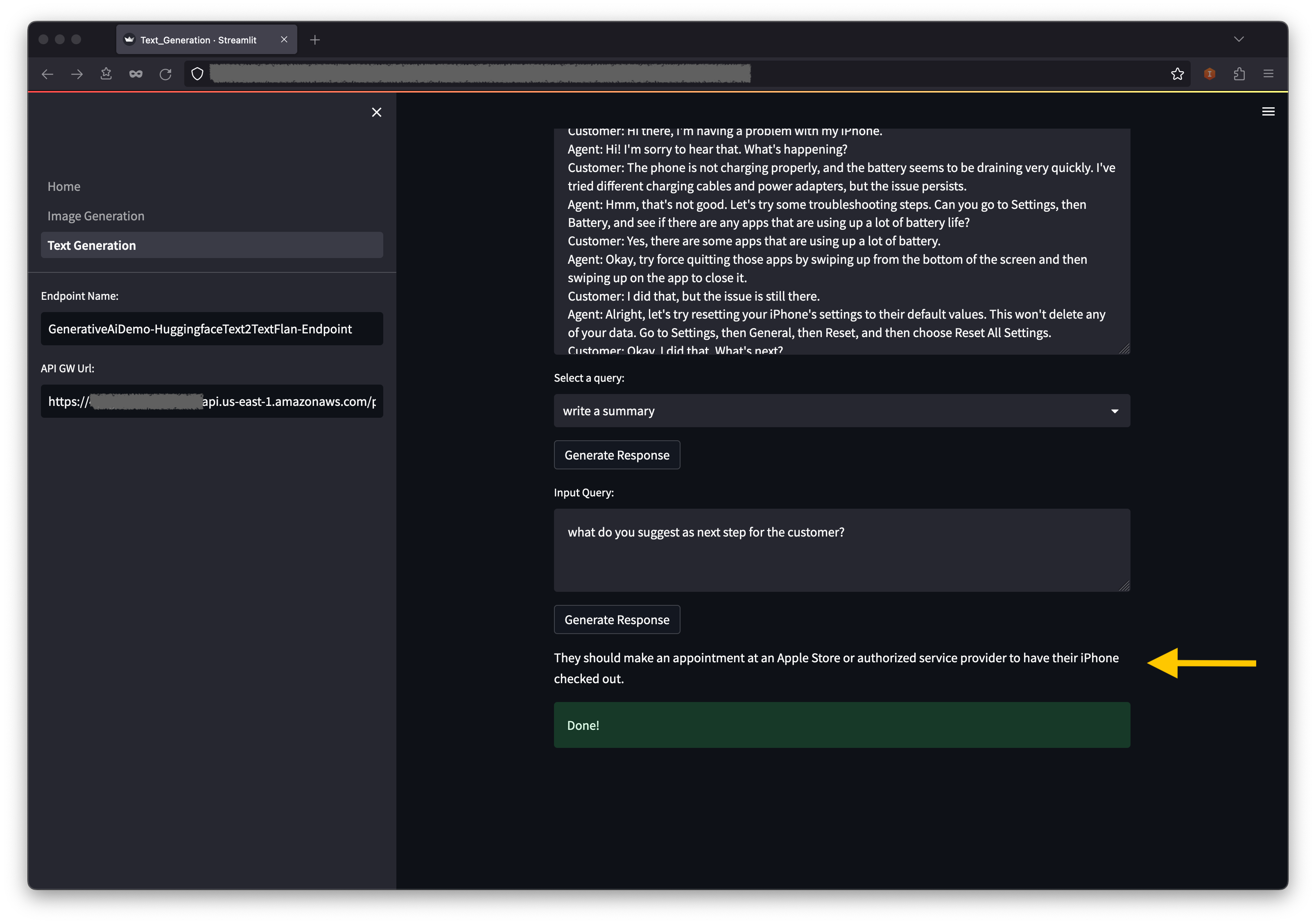
Você também pode inserir sua própria consulta no campo de consulta de entrada e escolher gerar resposta .
No console do AWS CloudFormation, escolha pilhas no painel de navegação para visualizar as pilhas implantadas.
No console do Amazon ECS, você pode ver os clusters na página de clusters .
No console da AWS Lambda, você pode ver as funções na página Funções .
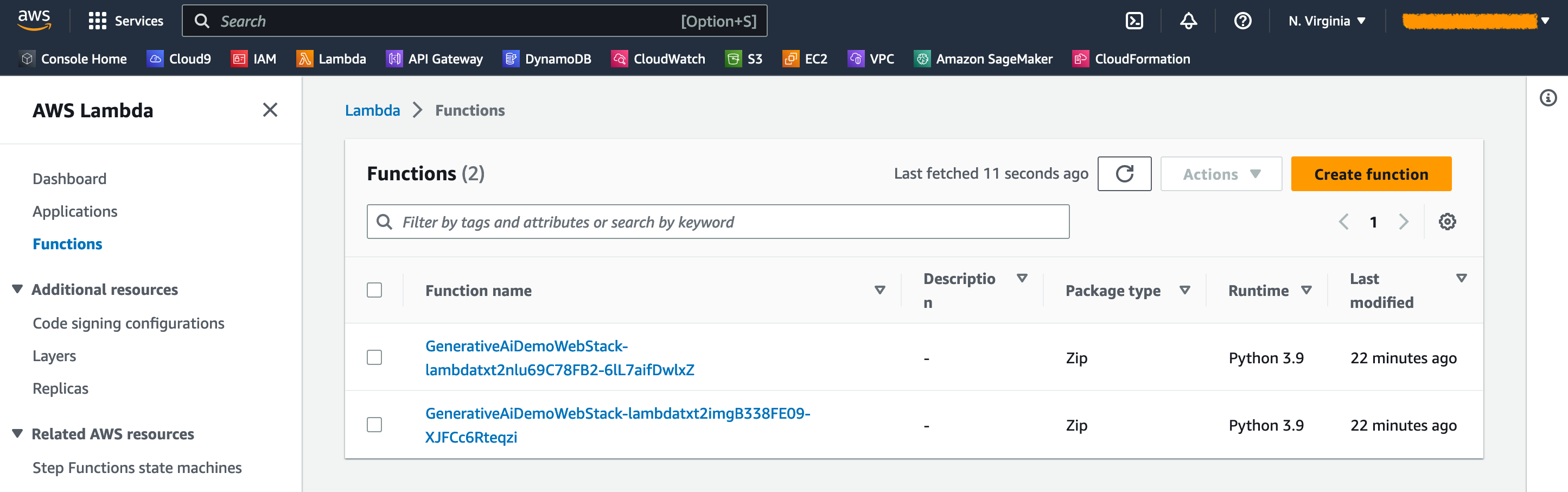
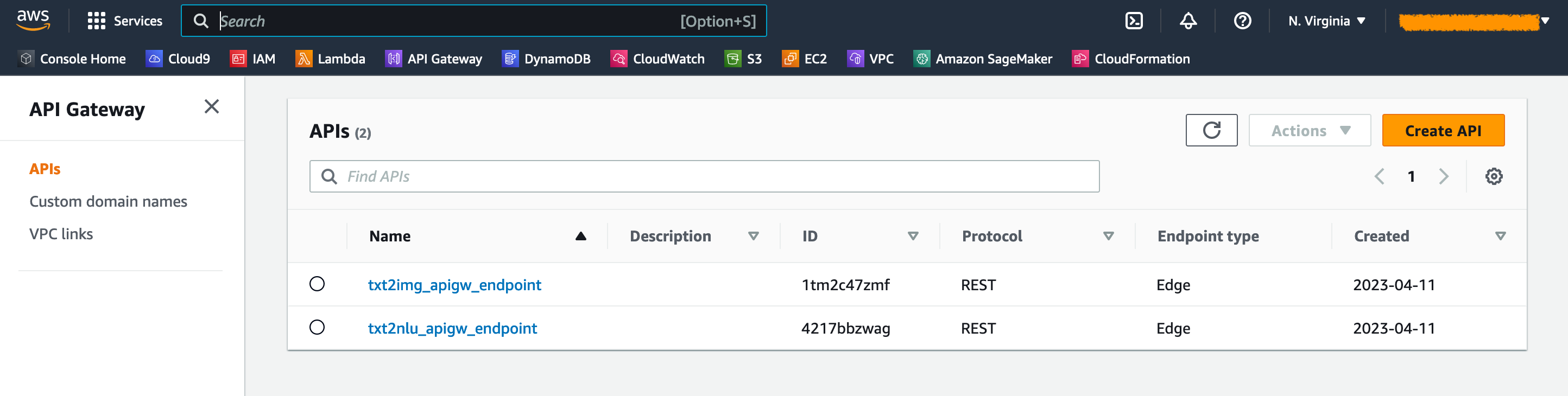
No console do gateway da API, você pode ver os pontos de extremidade do gateway da API na página APIs .
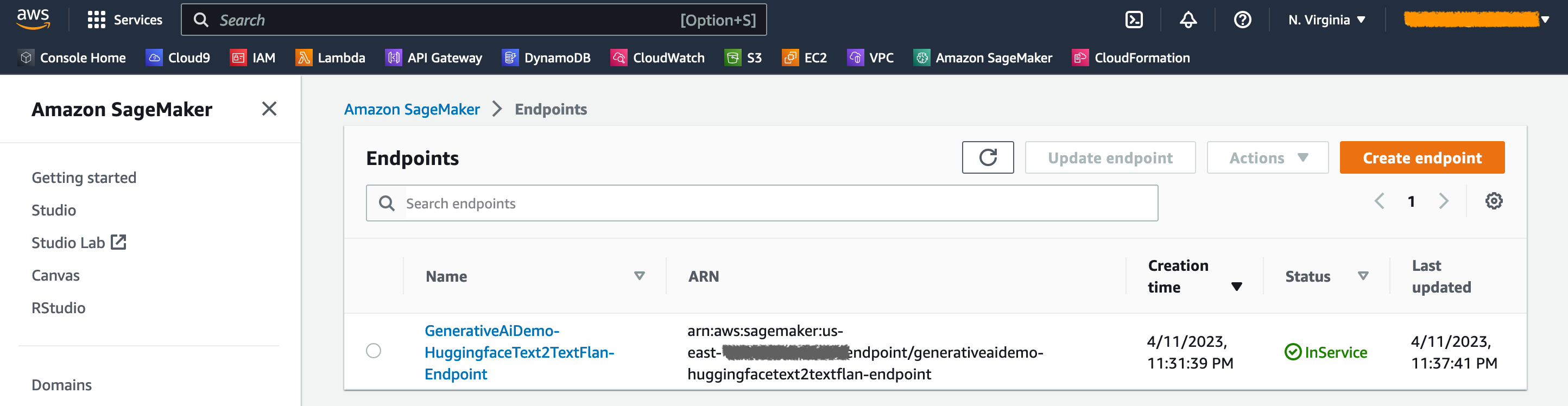
No console do Sagemaker, você pode ver os pontos de extremidade do modelo implantado na página Pontos de extremidade .
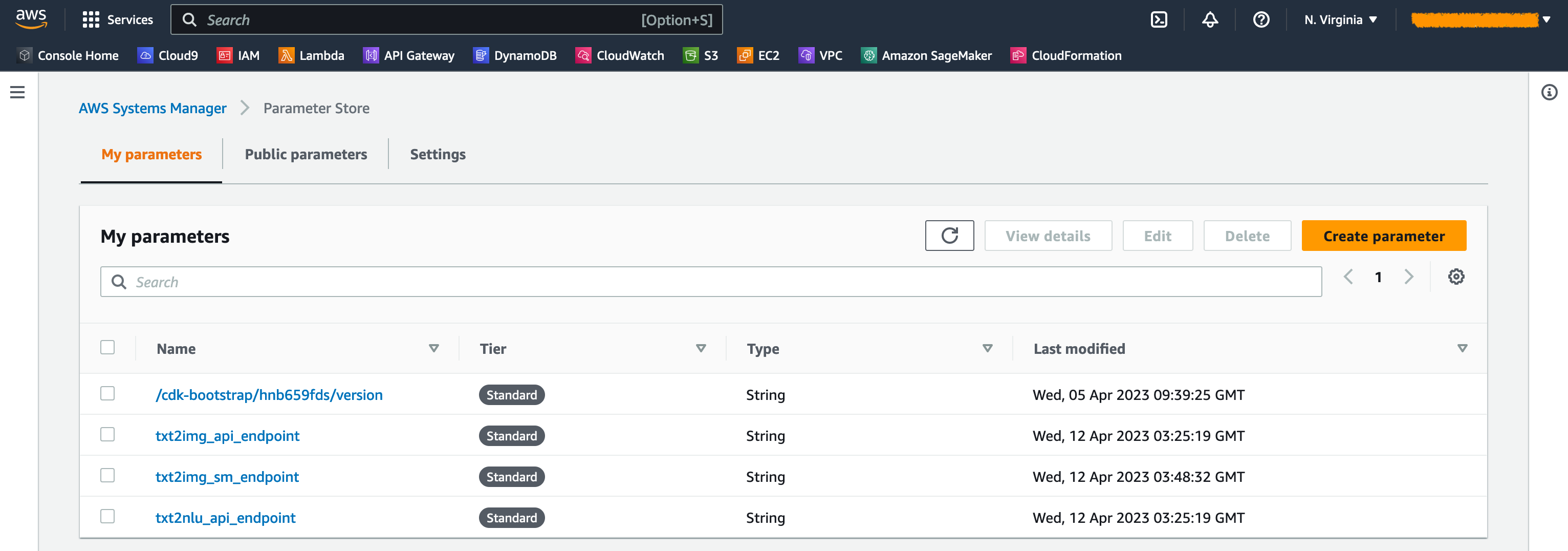
Quando as pilhas são lançadas, alguns parâmetros são gerados. Eles são armazenados no armazenamento de parâmetros do AWS Systems Manager. Para visualizá -los, escolha o armazenamento de parâmetros no painel de navegação no console do AWS Systems Manager.
Para evitar custos desnecessários, limpe toda a infraestrutura criada com o seguinte comando em sua estação de trabalho:
cdk destroy --all
Digite y no prompt. Esta etapa leva cerca de 10 minutos. Verifique se todos os recursos são excluídos no console. Exclua também os baldes S3 de ativos criados pelo AWS CDK no console Amazon S3, bem como os repositórios de ativos no Amazon ECR.
Conforme demonstrado nesta postagem, você pode usar o AWS CDK para implantar modelos generativos de IA no JumpStart. Mostramos um exemplo de geração de imagens e um exemplo de geração de texto usando uma interface de usuário alimentada por gateway de streamlit, lambda e API.
Agora você pode criar seus projetos generativos de IA usando modelos de IA pré-treinados no JumpStart. Você também pode estender este projeto para ajustar os modelos de fundação para o seu caso de uso e controle de acesso aos pontos de extremidade do gateway da API.
Convidamos você a testar a solução e contribuir para o projeto no GitHub.
Este código de amostra é disponibilizado sob uma licença MIT modificada. Consulte o arquivo de licença para obter mais informações. Além disso, revise as respectivas licenças para os modelos estáveis de difusão e FLAN-T5-XL no rosto abraçando.
Hantzley Tauckoor é um líder de arquitetura da APJ Partner Solutions com sede em Cingapura. Ele tem 20 anos de experiência na indústria de TIC, abrangendo várias áreas funcionais, incluindo arquitetura de soluções, desenvolvimento de negócios, estratégia de vendas, consultoria e liderança. Ele lidera uma equipe de arquitetos de soluções seniores que permitem que os parceiros desenvolvam soluções conjuntas, construam recursos técnicos e os conduzam pela fase de implementação, à medida que os clientes migram e modernizam seus aplicativos para a AWS. Fora do trabalho, ele gosta de passar tempo com sua família, assistindo filmes e caminhando.
Kwonyul Choi é um CTO no Babitalk, uma startup de plataforma de cuidados com a beleza coreana, com sede em Seul. Antes dessa função, Kownyul trabalhou como engenheiro de desenvolvimento de software na AWS, com foco na AWS CDK e na Amazon Sagemaker.
Arunprasath Shankar é um arquiteto de soluções especializadas em IA/ML da AWS, ajudando os clientes globais a escalar suas soluções de IA de maneira eficaz e eficiente na nuvem. Em seu tempo livre, Arun gosta de assistir filmes de ficção científica e ouvir música clássica.
Satish ustreti é um PSA de líder de migração e PME de segurança na organização parceira em APJ. Satish tem 20 anos de experiência, abrangendo tecnologias privadas em nuvem privada e em nuvem pública. Desde que ingressou na AWS em agosto de 2020 como especialista em migração, ele fornece extensos conselhos técnicos e apoio aos parceiros da AWS para planejar e implementar migrações complexas.
Nesta seção, fornecemos uma visão geral do código neste projeto.
Aplicativo AWS CDK
O aplicativo AWS CDK principal está contido no arquivo app.py no diretório raiz. O projeto consiste em várias pilhas, então temos que importar as pilhas:
#!/usr/bin/env python3
import aws_cdk as cdk
from stack . generative_ai_vpc_network_stack import GenerativeAiVpcNetworkStack
from stack . generative_ai_demo_web_stack import GenerativeAiDemoWebStack
from stack . generative_ai_txt2nlu_sagemaker_stack import GenerativeAiTxt2nluSagemakerStack
from stack . generative_ai_txt2img_sagemaker_stack import GenerativeAiTxt2imgSagemakerStackDefinimos nossos modelos generativos de IA e recebemos os URIs relacionados do Sagemaker:
from script . sagemaker_uri import *
import boto3
region_name = boto3 . Session (). region_name
env = { "region" : region_name }
#Text to Image model parameters
TXT2IMG_MODEL_ID = "model-txt2img-stabilityai-stable-diffusion-v2-1-base"
TXT2IMG_INFERENCE_INSTANCE_TYPE = "ml.g4dn.4xlarge"
TXT2IMG_MODEL_TASK_TYPE = "txt2img"
TXT2IMG_MODEL_INFO = get_sagemaker_uris ( model_id = TXT2IMG_MODEL_ID ,
model_task_type = TXT2IMG_MODEL_TASK_TYPE ,
instance_type = TXT2IMG_INFERENCE_INSTANCE_TYPE ,
region_name = region_name )
#Text to NLU image model parameters
TXT2NLU_MODEL_ID = "huggingface-text2text-flan-t5-xl"
TXT2NLU_INFERENCE_INSTANCE_TYPE = "ml.g4dn.4xlarge"
TXT2NLU_MODEL_TASK_TYPE = "text2text"
TXT2NLU_MODEL_INFO = get_sagemaker_uris ( model_id = TXT2NLU_MODEL_ID ,
model_task_type = TXT2NLU_MODEL_TASK_TYPE ,
instance_type = TXT2NLU_INFERENCE_INSTANCE_TYPE ,
region_name = region_name ) A função get_sagemaker_uris recupera todas as informações do modelo da Amazon Jumpstart. Consulte Script/Sagemaker_uri.py.
Então, instanciamos as pilhas:
app = cdk . App ()
network_stack = GenerativeAiVpcNetworkStack ( app , "GenerativeAiVpcNetworkStack" , env = env )
GenerativeAiDemoWebStack ( app , "GenerativeAiDemoWebStack" , vpc = network_stack . vpc , env = env )
GenerativeAiTxt2nluSagemakerStack ( app , "GenerativeAiTxt2nluSagemakerStack" , env = env , model_info = TXT2NLU_MODEL_INFO )
GenerativeAiTxt2imgSagemakerStack ( app , "GenerativeAiTxt2imgSagemakerStack" , env = env , model_info = TXT2IMG_MODEL_INFO )
app . synth () A primeira pilha a ser lançada é a pilha VPC, GenerativeAiVpcNetworkStack . A pilha de aplicativos da web, GenerativeAiDemoWebStack , depende da pilha VPC. A dependência é feita através do parâmetro Passando vpc=network_stack.vpc .
Consulte App.py para obter o código completo.
Pilha de rede VPC
Na pilha GenerativeAiVpcNetworkStack , criamos um VPC com uma sub -rede pública e uma sub -rede privada que abrange duas zonas de disponibilidade (AZS):
self . output_vpc = ec2 . Vpc ( self , "VPC" ,
nat_gateways = 1 ,
ip_addresses = ec2 . IpAddresses . cidr ( "10.0.0.0/16" ),
max_azs = 2 ,
subnet_configuration = [
ec2 . SubnetConfiguration ( name = "public" , subnet_type = ec2 . SubnetType . PUBLIC , cidr_mask = 24 ),
ec2 . SubnetConfiguration ( name = "private" , subnet_type = ec2 . SubnetType . PRIVATE_WITH_EGRESS , cidr_mask = 24 )
]
)Veja /stack/generative_ai_vpc_network_stack.py para o código completo.
Pilha de aplicativos de demonstração
Na pilha de GenerativeAiDemoWebStack lançamos funções Lambda e os respectivos endpoints do Amazon API Gateway, através dos quais o aplicativo da Web interage com os pontos de extremidade do modelo de sagema. Veja o seguinte snippet de código:
# Defines an AWS Lambda function for Image Generation service
lambda_txt2img = _lambda . Function (
self , "lambda_txt2img" ,
runtime = _lambda . Runtime . PYTHON_3_9 ,
code = _lambda . Code . from_asset ( "code/lambda_txt2img" ),
handler = "txt2img.lambda_handler" ,
role = role ,
timeout = Duration . seconds ( 180 ),
memory_size = 512 ,
vpc_subnets = ec2 . SubnetSelection (
subnet_type = ec2 . SubnetType . PRIVATE_WITH_EGRESS
),
vpc = vpc
)
# Defines an Amazon API Gateway endpoint for Image Generation service
txt2img_apigw_endpoint = apigw . LambdaRestApi (
self , "txt2img_apigw_endpoint" ,
handler = lambda_txt2img
)O aplicativo da Web é contêineido e hospedado no Amazon ECS com Fargate. Veja o seguinte snippet de código:
# Create Fargate service
fargate_service = ecs_patterns . ApplicationLoadBalancedFargateService (
self , "WebApplication" ,
cluster = cluster , # Required
cpu = 2048 , # Default is 256 (512 is 0.5 vCPU, 2048 is 2 vCPU)
desired_count = 1 , # Default is 1
task_image_options = ecs_patterns . ApplicationLoadBalancedTaskImageOptions (
image = image ,
container_port = 8501 ,
),
#load_balancer_name="gen-ai-demo",
memory_limit_mib = 4096 , # Default is 512
public_load_balancer = True ) # Default is TrueVeja /stack/generative_ai_demo_web_stack.py para o código completo.
Geração de imagens Sagemaker Model endpoint Stack
A pilha GenerativeAiTxt2imgSagemakerStack cria o ponto final do modelo de geração de imagens do Sagemaker Jumpstart e armazena o nome do terminal no armazenamento de parâmetros do AWS Systems Manager. Este parâmetro será usado pelo aplicativo da web. Veja o seguinte código:
endpoint = SageMakerEndpointConstruct ( self , "TXT2IMG" ,
project_prefix = "GenerativeAiDemo" ,
role_arn = role . role_arn ,
model_name = "StableDiffusionText2Img" ,
model_bucket_name = model_info [ "model_bucket_name" ],
model_bucket_key = model_info [ "model_bucket_key" ],
model_docker_image = model_info [ "model_docker_image" ],
variant_name = "AllTraffic" ,
variant_weight = 1 ,
instance_count = 1 ,
instance_type = model_info [ "instance_type" ],
environment = {
"MMS_MAX_RESPONSE_SIZE" : "20000000" ,
"SAGEMAKER_CONTAINER_LOG_LEVEL" : "20" ,
"SAGEMAKER_PROGRAM" : "inference.py" ,
"SAGEMAKER_REGION" : model_info [ "region_name" ],
"SAGEMAKER_SUBMIT_DIRECTORY" : "/opt/ml/model/code" ,
},
deploy_enable = True
)
ssm . StringParameter ( self , "txt2img_sm_endpoint" , parameter_name = "txt2img_sm_endpoint" , string_value = endpoint . endpoint_name )Consulte /stack/generative_ai_txt2img_sageMaker_stack.py para o código completo.
NLU e geração de texto Sagemaker Model endpoint Stack
A pilha GenerativeAiTxt2nluSagemakerStack cria o terminal NLU e o modelo de geração de texto do JumpStart e armazena o nome do terminal no armazenamento de parâmetros do Systems Manager. Este parâmetro também será usado pelo aplicativo da web. Veja o seguinte código:
endpoint = SageMakerEndpointConstruct ( self , "TXT2NLU" ,
project_prefix = "GenerativeAiDemo" ,
role_arn = role . role_arn ,
model_name = "HuggingfaceText2TextFlan" ,
model_bucket_name = model_info [ "model_bucket_name" ],
model_bucket_key = model_info [ "model_bucket_key" ],
model_docker_image = model_info [ "model_docker_image" ],
variant_name = "AllTraffic" ,
variant_weight = 1 ,
instance_count = 1 ,
instance_type = model_info [ "instance_type" ],
environment = {
"MODEL_CACHE_ROOT" : "/opt/ml/model" ,
"SAGEMAKER_ENV" : "1" ,
"SAGEMAKER_MODEL_SERVER_TIMEOUT" : "3600" ,
"SAGEMAKER_MODEL_SERVER_WORKERS" : "1" ,
"SAGEMAKER_PROGRAM" : "inference.py" ,
"SAGEMAKER_SUBMIT_DIRECTORY" : "/opt/ml/model/code/" ,
"TS_DEFAULT_WORKERS_PER_MODEL" : "1"
},
deploy_enable = True
)
ssm . StringParameter ( self , "txt2nlu_sm_endpoint" , parameter_name = "txt2nlu_sm_endpoint" , string_value = endpoint . endpoint_name )Consulte /stack/generative_ai_txt2nlu_sageMaker_stack.py para o código completo.
O aplicativo da web
O aplicativo da web está localizado no diretório /web-aplicativo. É um aplicativo de streamlit que é recipiente de acordo com o DockerFile:
FROM --platform=linux/x86_64 python:3.9
EXPOSE 8501
WORKDIR /app
COPY requirements.txt ./requirements.txt
RUN pip3 install -r requirements.txt
COPY . .
CMD streamlit run Home.py
--server.headless true
--browser.serverAddress= "0.0.0.0"
--server.enableCORS false
--browser.gatherUsageStats falsePara saber mais sobre o StreamLit, consulte a documentação do streamlit.


