generative ai sagemaker cdk demo
1.0.0
Die Saatgut eines Paradigmenverschiebung eines maschinellen Lernens (ML) bestehen seit Jahrzehnten, aber mit der seriösen Verfügbarkeit praktisch unendlicher Rechenkapazität, einer massiven Verbreitung von Daten und dem schnellen Fortschritt von ML -Technologien, die Kunden in allen Branchen rasch übernehmen und nutzen ML -Technologien, um ihre Geschäfte zu transformieren.
Erst kürzlich haben generative KI -Anwendungen die Aufmerksamkeit und Fantasie aller aufgenommen. Wir befinden uns wirklich an einem aufregenden Wendepunkt in der weit verbreiteten Einführung von ML, und wir glauben, dass jedes Kundenerlebnis und jede Anwendung mit generativer KI neu erfunden werden.
Generative KI ist eine Art KI, die neue Inhalte und Ideen erstellen kann, einschließlich Gesprächen, Geschichten, Bildern, Videos und Musik. Wie bei allen KI wird generative KI von ML-Modellen angetrieben-sehr große Modelle, die auf riesige Datenkorpora vorhanden sind und allgemein als Foundation Models (FMS) bezeichnet werden.
Die Größe und die allgemeine Natur von FMS unterscheiden sie von herkömmlichen ML-Modellen, die typischerweise bestimmte Aufgaben ausführen, z. B. die Analyse des Textes für Stimmung, Klassifizierung von Bildern und Prognose-Trends.
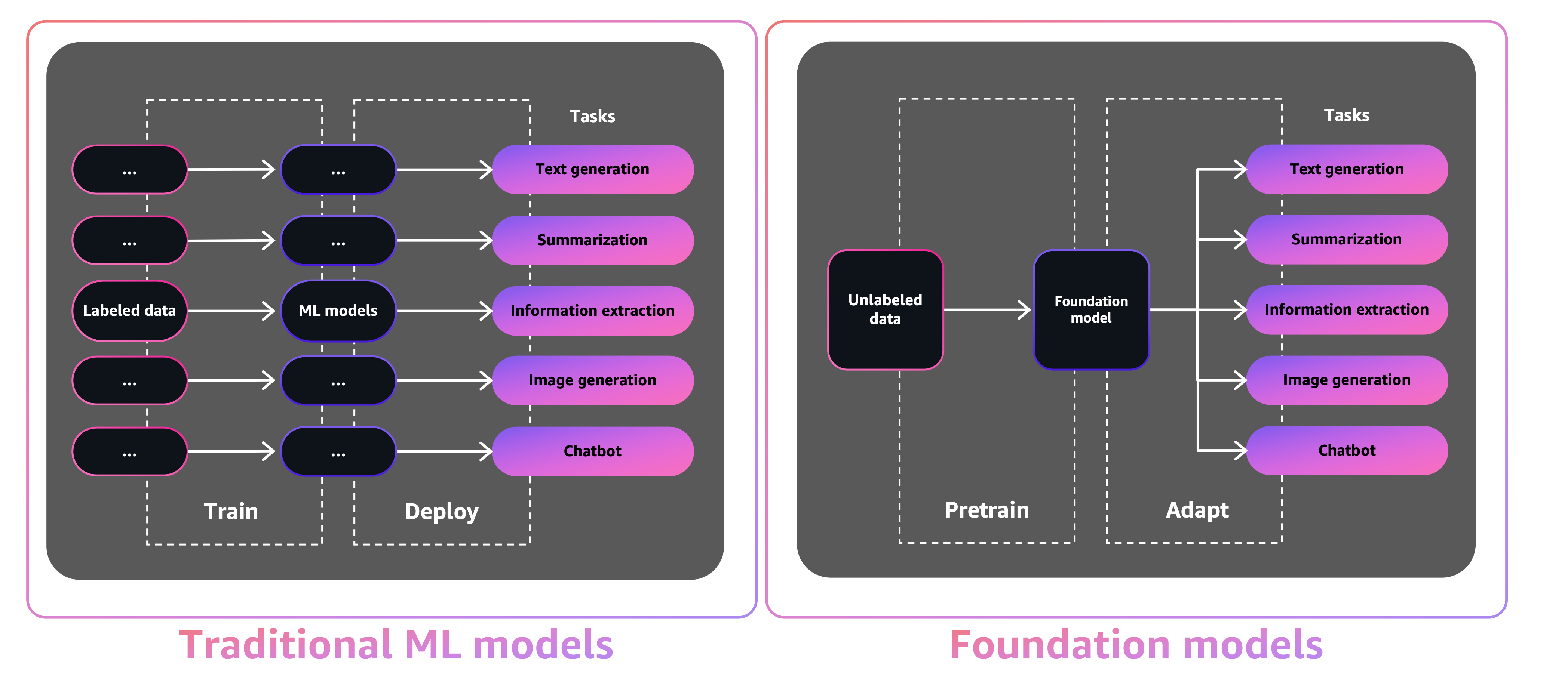
Mit traditionellen ML -Modellen müssen Sie, um jede spezifische Aufgabe zu erreichen, beschriftete Daten sammeln, ein Modell trainieren und dieses Modell bereitstellen. Mit Foundation-Modellen können Sie anstatt markierte Daten für jedes Modell zu sammeln und mehrere Modelle zu trainieren, die gleiche vorgebrachte FM verwenden, um verschiedene Aufgaben anzupassen. Sie können FMS auch an domänenspezifische Funktionen anpassen, die sich an Ihre Unternehmen unterscheiden, wobei Sie nur einen kleinen Teil der Daten verwenden und für die Ausbildung eines Modells von Grund auf berechnen werden.
Generative KI hat das Potenzial, viele Branchen zu stören, indem die Art und Weise revolutioniert wird, wie Inhalte erstellt und konsumiert werden. Die ursprüngliche Inhaltsproduktion, die Erzeugung der Code, die Verbesserung des Kundendienstes und die Zusammenfassung der Dokumente sind typische Anwendungsfälle von generativer KI.
Der Amazon Sagemaker Jumpstart bietet vorgeschriebene Open-Source-Modelle für eine Vielzahl von Problemtypen, mit denen Sie mit ML beginnen können. Sie können diese Modelle vor dem Einsatz inkrementell trainieren und einstellen. JumpStart bietet auch Lösungsvorlagen, die die Infrastruktur für gemeinsame Anwendungsfälle einrichten, und ausführbare Beispielbücher für ML mit Amazon Sagemaker.
Mit über 600 vorhandenen Modellen, die täglich verfügbar sind und täglich wachsen, ermöglicht JumpStart es den Entwicklern, schnelle und einfache ML-Techniken in ihre Produktionsworkflows in Einbeziehung in die Hand zu bringen. Sie können über die Sprungstart-Landing-Seite im Amazon Sagemaker Studio auf die vorgeborenen Modelle, Lösungsvorlagen und Beispiele zugreifen. Mit dem Sagemaker Python SDK können Sie auch Sprungstart -Modelle zugreifen. Informationen zur programmgesteuerten Verwendung von Sprungstart -Modellen finden Sie unter Verwendung von Sagemaker -Jumpstart -Algorithmen mit vorbereiteten Modellen.
Im April 2023 enthüllte AWS Amazon Bedrock, das eine Möglichkeit bietet, generative AI-betriebene Apps über vorgebliebene Modelle von Startups wie AI21 Labs, Anthropic und Stability AI zu erstellen. Amazon Bedrock bietet auch Zugang zu Titan Foundation Models, einer Familie von Models, die von AWS intern ausgebildet wurden. Mit der serverlosen Erfahrung von Amazon -Grundgestein können Sie leicht das richtige Modell für Ihre Bedürfnisse finden, schnell gestartet, FMS privat mit Ihren eigenen Daten anpassen und sie einfach in Ihre Anwendungen mit den AWS -Tools und -funktionen integrieren und bereitstellen.
In diesem Beitrag zeigen wir, wie Sie mit dem AWS Cloud Development Kit (AWS CDK) Bild- und Textgenerative KI -Modelle von Jumpstart bereitstellen. Das AWS CDK ist ein Open-Source-Softwareentwicklungsrahmen, mit dem Sie Ihre Cloud-Anwendungsressourcen mithilfe bekannter Programmiersprachen wie Python definieren können.
Wir verwenden das stabile Diffusionsmodell für die Bildgenerierung und das Flan-T5-XL-Modell für das Verständnis für natürliche Sprache (NLU) und die Textgenerierung vom Umarmen des Gesichts im Sprungstart.
Die Webanwendung basiert auf Streamlit, einer Open-Source-Python-Bibliothek, mit der schöne, benutzerdefinierte Web-Apps für ML und Data Science erstellt und freigegeben werden können. Wir hosten die Webanwendung mit Amazon Elastic Container Service (Amazon ECS) mit AWS Fargate auf und wird über einen Anwendungslastausgleich aufgerufen. Fargate ist eine Technologie, die Sie mit Amazon ECs verwenden können, um Container auszuführen, ohne Server oder Cluster oder virtuelle Maschinen verwalten zu müssen. Die generativen AI -Modellendpunkte werden aus Jumpstart -Bildern in der Amazon Elastic Container Registry (Amazon ECR) gestartet. Modelldaten werden im Amazon Simple Storage Service (Amazon S3) im JumpStart -Konto gespeichert. Die Webanwendung interagiert mit den Modellen über Amazon API Gateway und AWS Lambda -Funktionen, wie im folgenden Diagramm gezeigt.
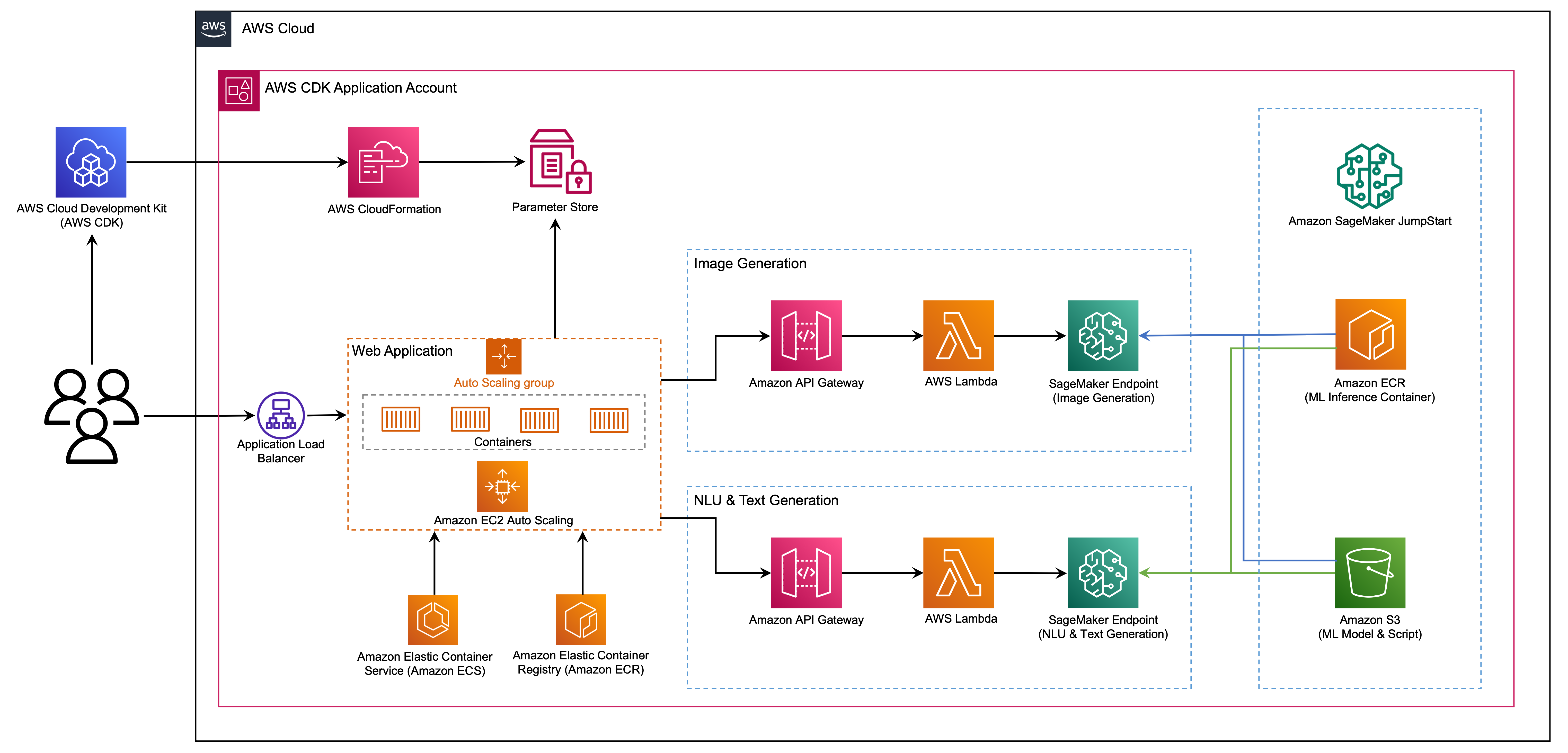
API Gateway bietet der Webanwendung und anderen Clients eine Standard -Rastful -Schnittstelle, während die Lambda -Funktionen, die mit dem Modell eine Schnittstellen haben, abschirmen. Dies vereinfacht den Client -Anwendungscode, der die Modelle verbraucht. Die API -Gateway -Endpunkte sind in diesem Beispiel öffentlich zugänglich und ermöglichen die Möglichkeit, diese Architektur zu erweitern, um verschiedene API -Zugriffskontrollen zu implementieren und in andere Anwendungen zu integrieren.
In diesem Beitrag führen wir Sie durch die folgenden Schritte:
Wir geben einen Überblick über den Code in diesem Projekt im Anhang am Ende dieses Beitrags.
Sie müssen die folgenden Voraussetzungen haben:
Sie können die Infrastruktur in diesem Tutorial von Ihrem lokalen Computer von AWS Cloud9 als Bereitstellungs -Workstation bereitstellen. AWS Cloud9 wird mit AWS CLI, AWS CDK und Docker vorinstalliert. Wenn Sie sich für AWS Cloud9 entscheiden, erstellen Sie die Umgebung aus der AWS -Konsole.
Die geschätzten Kosten für den Abschluss dieses Beitrags betragen 50 US -Dollar, vorausgesetzt, Sie lassen die Ressourcen 8 Stunden lang laufend. Stellen Sie sicher, dass Sie die in diesem Beitrag erstellten Ressourcen löschen, um laufende Gebühren zu vermeiden.
Wenn Sie die AWS CLI noch nicht auf Ihrem lokalen Computer haben, finden Sie in der neuesten Version der AWS -CLI und konfigurieren Sie die AWS -CLI.
Installieren Sie den AWS -CDK -Toolkit weltweit mit dem folgenden Befehl node packagemanager:
npm install -g aws-cdk-lib@latest
Führen Sie den folgenden Befehl aus, um die richtige Installation zu überprüfen und die Versionsnummer des AWS -CDK zu drucken:
cdk --version
Stellen Sie sicher, dass Sie Docker auf Ihrem lokalen Computer installiert haben. Geben Sie den folgenden Befehl aus, um die Version zu überprüfen:
docker --version
Klonen Sie auf Ihrer lokalen Maschine die AWS -CDK -Anwendung mit dem folgenden Befehl:
git clone https://github.com/aws-samples/generative-ai-sagemaker-cdk-demo.git
Navigieren Sie zum Projektordner:
cd generative-ai-sagemaker-cdk-demo
Bevor wir die Anwendung bereitstellen, überprüfen wir die Verzeichnisstruktur:
.
├── LICENSE
├── README.md
├── app.py
├── cdk.json
├── code
│ ├── lambda_txt2img
│ │ └── txt2img.py
│ └── lambda_txt2nlu
│ └── txt2nlu.py
├── construct
│ └── sagemaker_endpoint_construct.py
├── images
│ ├── architecture.png
│ ├── ...
├── requirements-dev.txt
├── requirements.txt
├── source.bat
├── stack
│ ├── __init__.py
│ ├── generative_ai_demo_web_stack.py
│ ├── generative_ai_txt2img_sagemaker_stack.py
│ ├── generative_ai_txt2nlu_sagemaker_stack.py
│ └── generative_ai_vpc_network_stack.py
├── tests
│ ├── __init__.py
│ └── ...
└── web-app
├── Dockerfile
├── Home.py
├── configs.py
├── img
│ └── sagemaker.png
├── pages
│ ├── 2_Image_Generation.py
│ └── 3_Text_Generation.py
└── requirements.txt Der stack enthält den Code für jeden Stapel in der AWS -CDK -Anwendung. Der code enthält den Code für die Amazon Lambda -Funktionen. Das Repository enthält auch die Webanwendung unter der Ordner web-app .
Die cdk.json -Datei gibt dem AWS CDK Toolkit mit, wie Sie Ihre Anwendung ausführen.
Diese Anwendung wurde in der Region us-east-1 getestet, sollte jedoch in jeder Region funktionieren, in der die erforderlichen Dienste und Inferenzinstanztyp ml.g4dn.4xlarge in App.Py angegeben sind.
Dieses Projekt ist wie ein Standard -Python -Projekt eingerichtet. Erstellen Sie eine virtuelle Python -Umgebung mit dem folgenden Code:
python3 -m venv .venv
Verwenden Sie den folgenden Befehl, um die virtuelle Umgebung zu aktivieren:
source .venv/bin/activate
Wenn Sie sich auf einer Windows -Plattform befinden, aktivieren Sie die virtuelle Umgebung wie folgt:
.venvScriptsactivate.bat
Nachdem die virtuelle Umgebung aktiviert wurde, upgraden Sie PIP auf die neueste Version ein:
python3 -m pip install --upgrade pip
Installieren Sie die erforderlichen Abhängigkeiten:
pip install -r requirements.txt
Bevor Sie eine AWS -CDK -Anwendung bereitstellen, müssen Sie einen Speicherplatz in Ihrem Konto und die Region, in die Sie bereitstellen, starten. Um in Ihrer Standardregion zu starten, geben Sie den folgenden Befehl aus:
cdk bootstrap
Wenn Sie in ein bestimmtes Konto und eine bestimmte Region bereitstellen möchten, geben Sie den folgenden Befehl aus:
cdk bootstrap aws://ACCOUNT-NUMBER/REGION
Weitere Informationen zu diesem Setup finden Sie unter Erste Schritte mit dem AWS -CDK.
Die AWS -CDK -Anwendung enthält mehrere Stapel, wie im folgenden Diagramm gezeigt.
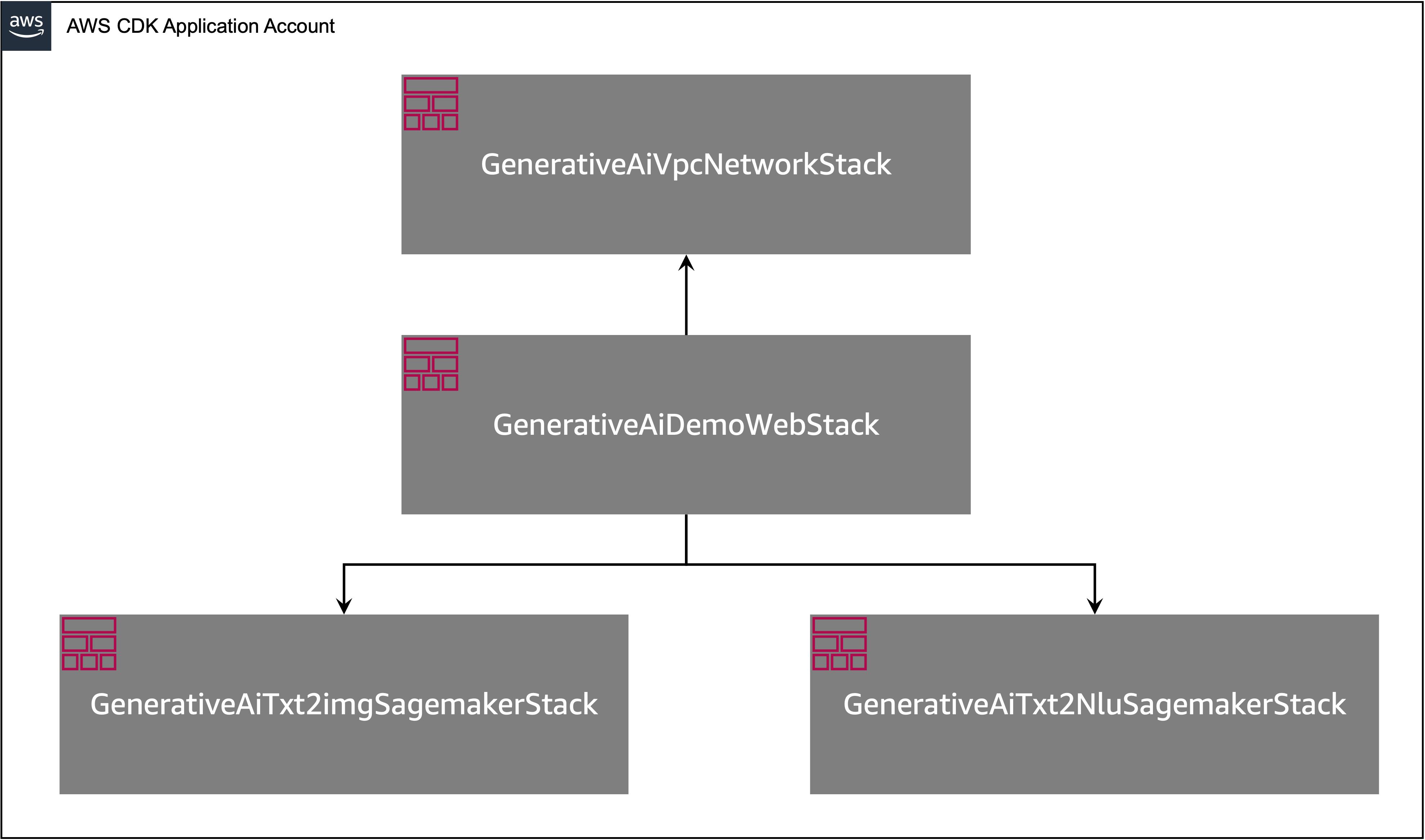
Sie können Stapel in Ihrer CDK -Anwendung mit dem folgenden Befehl auflisten:
cdk listSie sollten die folgende Ausgabe erhalten:
GenerativeAiTxt2imgSagemakerStack
GenerativeAiTxt2nluSagemakerStack
GenerativeAiVpcNetworkStack
GenerativeAiDemoWebStack
Andere nützliche AWS -CDK -Befehle:
cdk ls - Listet alle Stapel in der App aufcdk synth - emittiert die synthetisierte AWS -CloudFormation -Vorlagecdk deploy - Bereitet diesen Stack für Ihr Standard -AWS -Konto und Ihre Region bereitcdk diff - vergleicht den bereitgestellten Stack mit dem aktuellen Zustandcdk docs - Öffnet die AWS -CDK -DokumentationDer nächste Abschnitt zeigt, wie Sie die AWS -CDK -Anwendung bereitstellen.
Die AWS -CDK -Anwendung wird basierend auf Ihrer Workstation -Konfiguration in der Standardregion bereitgestellt. Wenn Sie die Bereitstellung in einer bestimmten Region erzwingen möchten, setzen Sie Ihre Umgebungsvariable für AWS_DEFAULT_REGION entsprechend.
Zu diesem Zeitpunkt können Sie die AWS -CDK -Anwendung bereitstellen. Zuerst starten Sie den VPC Network Stack:
cdk deploy GenerativeAiVpcNetworkStack
Wenn Sie aufgefordert werden, geben Sie y ein, um mit der Bereitstellung fortzufahren. Sie sollten eine Liste von AWS -Ressourcen sehen, die im Stapel bereitgestellt werden. Dieser Schritt dauert ungefähr 3 Minuten.
Dann starten Sie den Webanwendungsstapel:
cdk deploy GenerativeAiDemoWebStack
Nach der Analyse des Stacks zeigt der AWS -CDK die Ressourcenliste im Stapel an. Geben Sie y ein, um mit dem Einsatz fortzufahren. Dieser Schritt dauert ungefähr 5 Minuten.
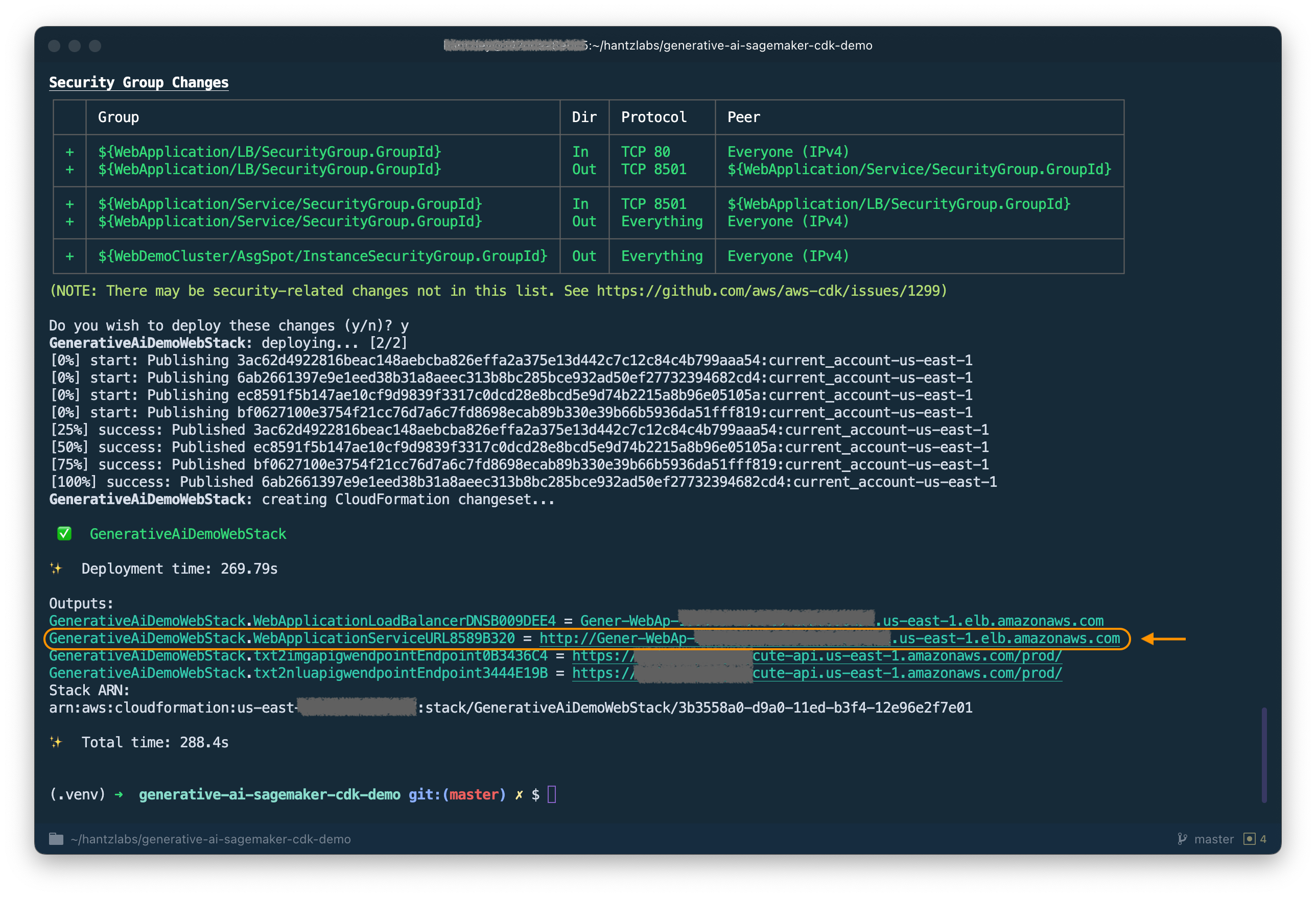
HINWEIS DIE WebApplicationServiceURL von der Ausgabe, da Sie sie später verwenden. Sie können es später auch in der CloudFormation -Konsole unter den GenerativeAiDemoWebStack -Stapelausgängen abrufen.
Starten Sie nun den AI -Modell Endpoint -Stack der Bildgenerierung:
cdk deploy GenerativeAiTxt2imgSagemakerStack
Dieser Schritt dauert ungefähr 8 Minuten. Der Bildgenerierungsmodellendpunkt wird bereitgestellt, wir können es jetzt verwenden.
Das erste Beispiel zeigt, wie eine stabile Diffusion verwendet wird, eine leistungsstarke generative Modellierungstechnik, die die Erstellung hochwertiger Bilder aus Texteingabeaufforderungen ermöglicht.
WebApplicationServiceURL auf die GenerativeAiDemoWebStack zuzugeben. 
Wählen Sie im Navigationsbereich Bildgenerierung .
Der Sagemaker-Endpunktname und die API-GW-URL -Felder werden vorgepopuliert, aber Sie können die Eingabeaufforderung für die Bildbeschreibung ändern, wenn Sie möchten.
Wählen Sie Bild erzeugen .
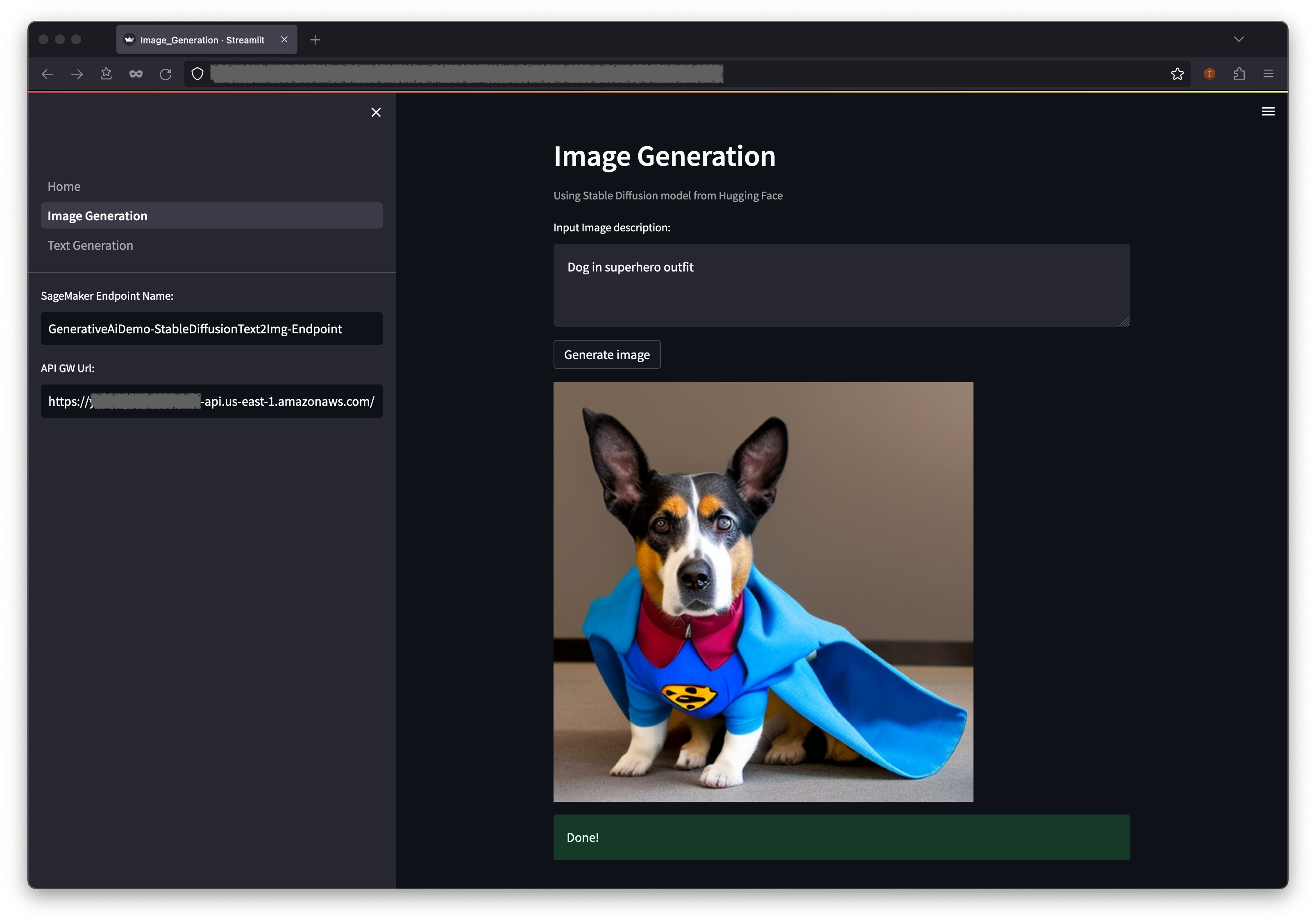
Die Anwendung wird beim Sagemaker -Endpunkt aufgerufen. Es dauert ein paar Sekunden. Ein Bild mit den Charasteristik in Ihrer Bildbeschreibung wird angezeigt.
Das zweite Beispiel dreht sich um die Verwendung des FLAN-T5-XL-Modells, das ein Fundament oder ein großes Sprachmodell (LLM) ist, um das Lernen des Kontext-Lernens für die Textgenerierung zu erreichen und gleichzeitig ein breites Spektrum von Aufgaben des natürlichen Sprachverständnisses (NLU) und natürlicher Sprache (natürliche Sprache zu erzeugen).
Einige Umgebungen können die Anzahl der Endpunkte einschränken, die Sie jeweils starten können. Wenn dies der Fall ist, können Sie jeweils einen Sagemaker -Endpunkt starten. Um einen Sagemaker -Endpunkt in der AWS -CDK -App zu stoppen, müssen Sie den bereitgestellten Endpoint -Stack zerstören und bevor Sie den anderen Endpoint -Stack starten. Um den AI -Modell der Bildgenerierung abzulehnen, geben Sie den folgenden Befehl aus:
cdk destroy GenerativeAiTxt2imgSagemakerStack
Starten Sie dann den AI -Modell Endpoint Stack der Textgenerierung:
cdk deploy GenerativeAiTxt2nluSagemakerStack
Geben Sie y an die Eingabeaufforderungen ein.
Führen Sie die folgenden Schritte aus:
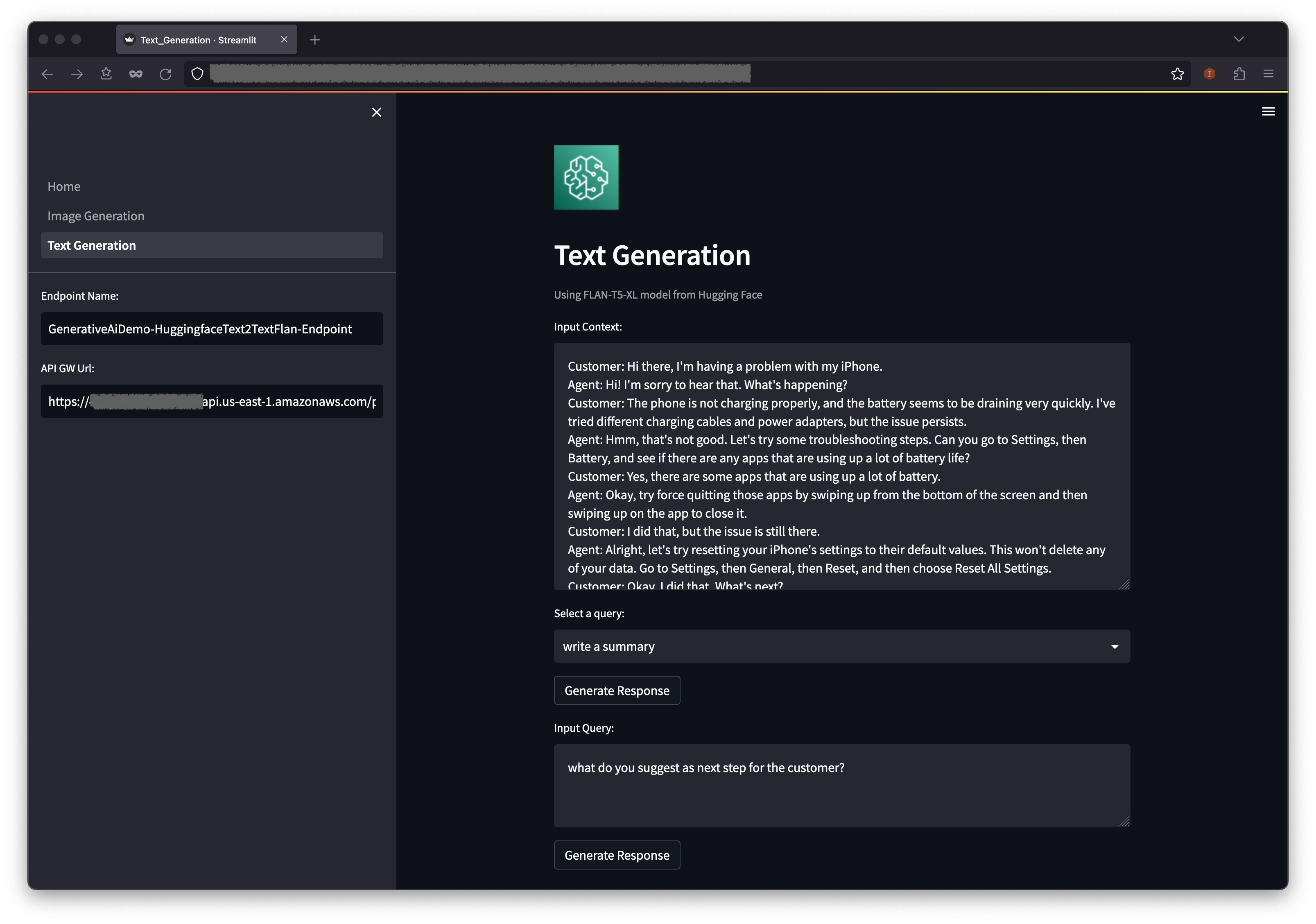
Unter dem Kontext finden Sie einige präpopulierte Abfragen in den Dropdown -Menüoptionen.
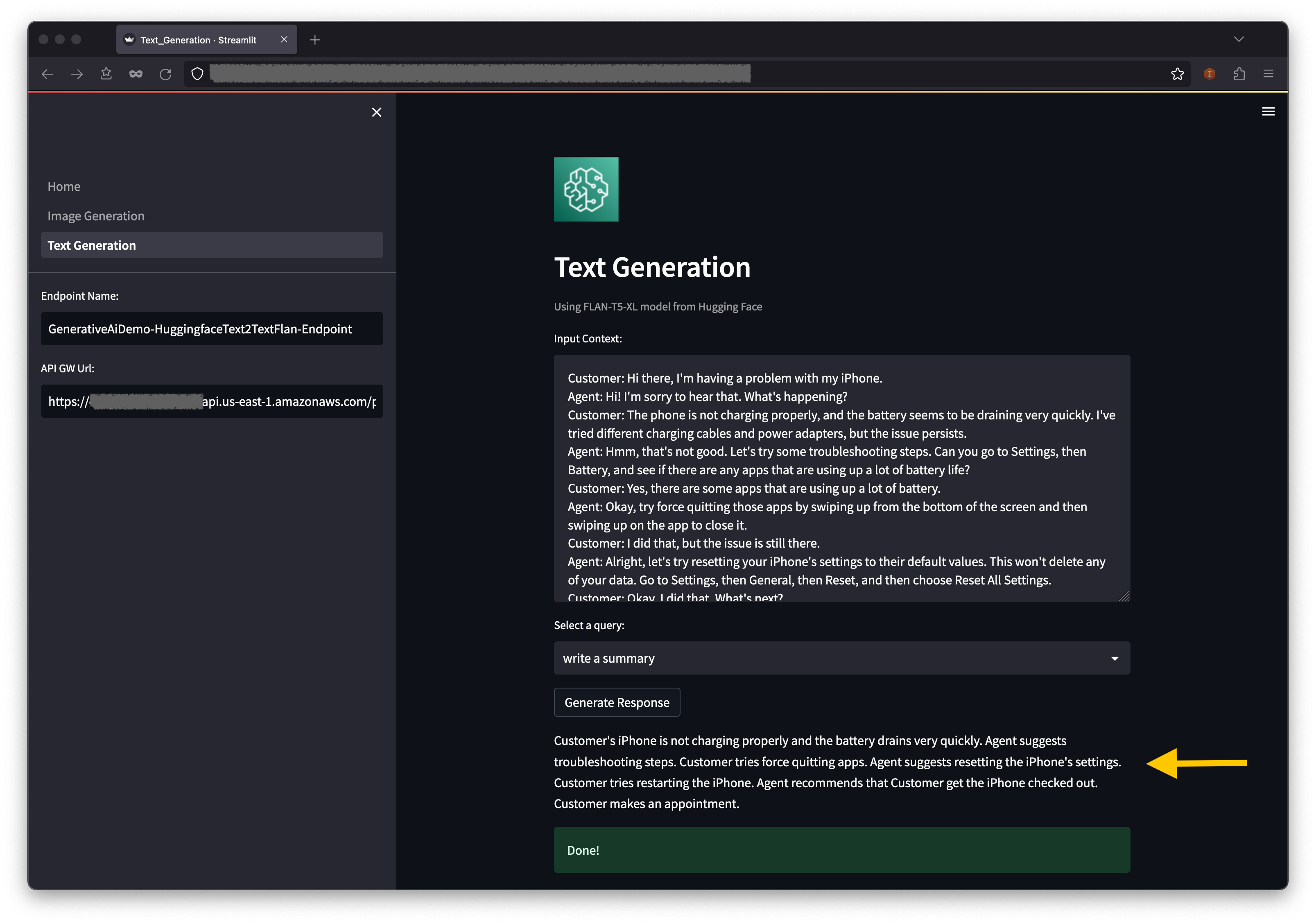
Sie können auch Ihre eigene Abfrage in das Feld für Eingabeabfragen eingeben und eine Antwort generieren .
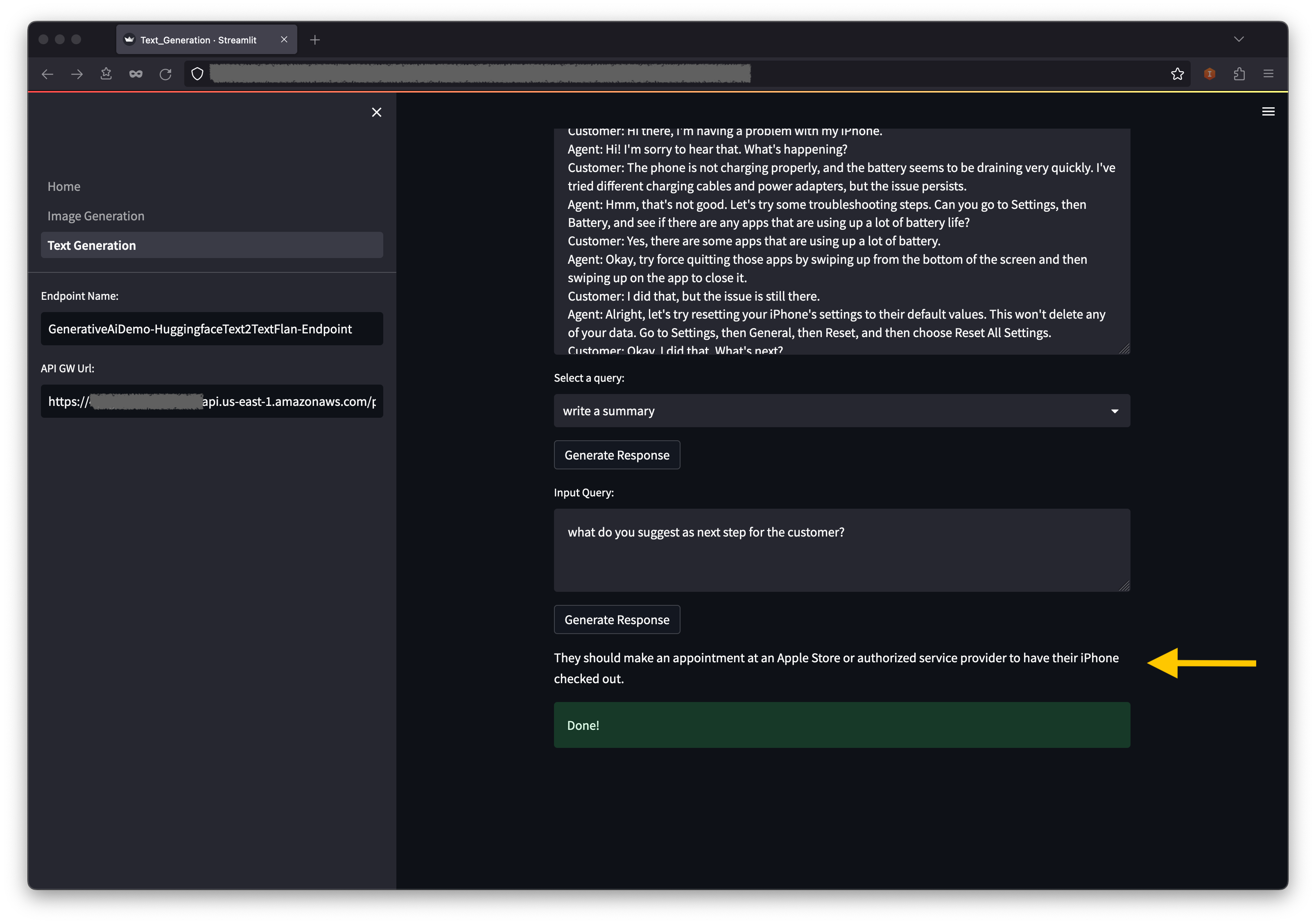
Wählen Sie auf der AWS CloudFormation -Konsole Stapel im Navigationsbereich aus, um die stapelgesteuerten Stapel anzuzeigen.
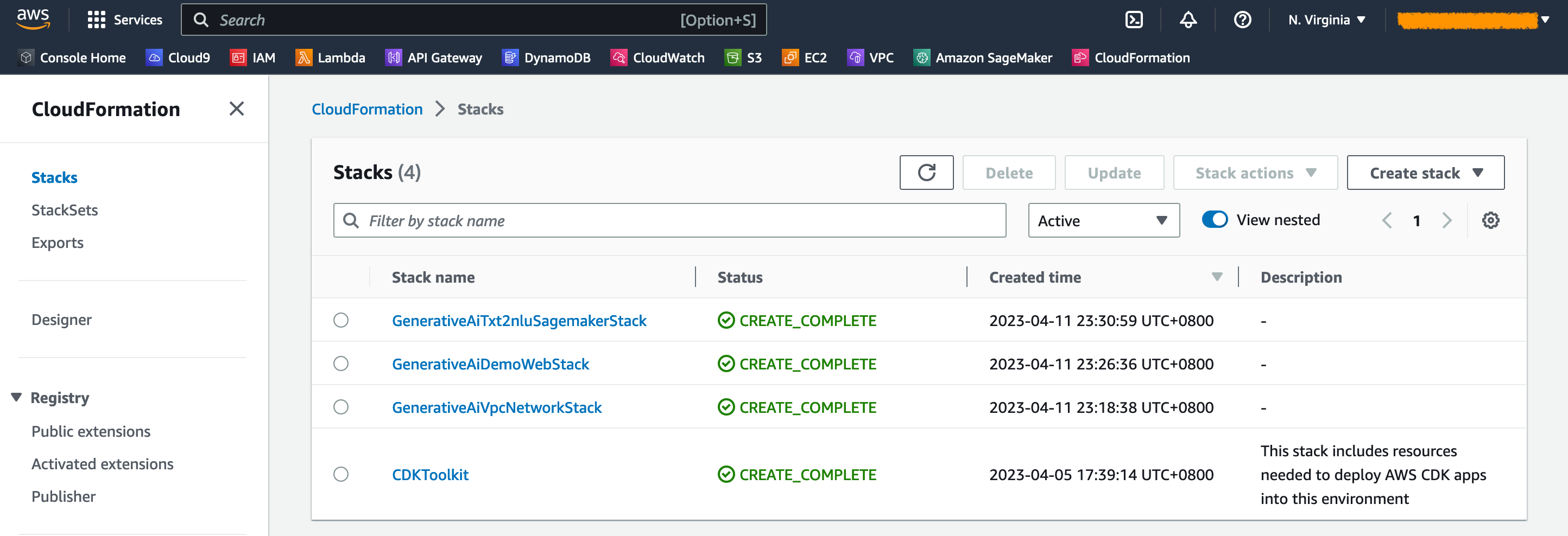
Auf der Amazon ECS -Konsole sehen Sie die Cluster auf der Seite Cluster .
Auf der AWS Lambda -Konsole können Sie die Funktionen auf der Seite Funktionen sehen.
Auf der API -Gateway -Konsole sehen Sie die API -Gateway -Endpunkte auf der APIS -Seite.
Auf der Sagemaker -Konsole sehen Sie die bereitgestellten Modellendpunkte auf der Seite der Endpunkte .
Wenn die Stapel gestartet werden, werden einige Parameter generiert. Diese werden im AWS Systems Manager -Parameterspeicher gespeichert. Um sie anzusehen, wählen Sie Parameterspeicher im Navigationsbereich der AWS Systems Manager -Konsole.
Um unnötige Kosten zu vermeiden, beseitigen Sie die gesamte Infrastruktur, die mit dem folgenden Befehl auf Ihrer Workstation erstellt wurde:
cdk destroy --all
Geben Sie y an der Eingabeaufforderung ein. Dieser Schritt dauert ungefähr 10 Minuten. Überprüfen Sie, ob alle Ressourcen auf der Konsole gelöscht werden. Löschen Sie auch die von der AWS CDK auf der Amazon S3 -Konsole erstellten Assets S3 -Eimer sowie die Repositories für Vermögenswerte bei Amazon ECR.
Wie in diesem Beitrag gezeigt, können Sie mit dem AWS -CDK generative KI -Modelle in Jumpstart bereitstellen. Wir haben ein Beispiel für Bildgenerierung und ein Beispiel für Textgenerierung unter Verwendung einer Benutzeroberfläche angezeigt, die von Streamlit, Lambda und API Gateway betrieben wird.
Sie können jetzt Ihre generativen KI-Projekte mit vorgeborenen KI-Modellen in Jumpstart erstellen. Sie können dieses Projekt auch so erweitern, dass die Grundlagenmodelle für Ihren Anwendungsfall optimieren und den Zugriff auf API-Gateway-Endpunkte steuern.
Wir laden Sie ein, die Lösung zu testen und zum Projekt auf GitHub beizutragen.
Dieser Beispielcode wird unter einer modifizierten MIT -Lizenz zur Verfügung gestellt. Weitere Informationen finden Sie in der Lizenzdatei. Überprüfen Sie auch die jeweiligen Lizenzen für die stabilen Modelle Diffusion- und Flan-T5-XL-Modelle für das Umarmungsgesicht.
Hantzley Tauckoor ist ein APJ Partner Solutions Architecture Leader mit Sitz in Singapur. Er verfügt über 20 Jahre Erfahrung in der IKT -Branche, die mehrere funktionale Bereiche umfasst, darunter Lösungsarchitektur, Geschäftsentwicklung, Vertriebsstrategie, Beratung und Führung. Er leitet ein Team von Senior Solutions -Architekten, das es Partnern ermöglicht, gemeinsame Lösungen zu entwickeln, technische Funktionen aufzubauen und sie durch die Implementierungsphase zu lenken, während die Kunden ihre Anwendungen auf AWS migrieren und modernisieren. Außerhalb der Arbeit verbringt er gerne Zeit mit seiner Familie, schaut sich Filme an und wandert.
Kwonyul Choi ist CTO in Babitalk, einem Startup der koreanischen Schönheitspflegeplattform mit Sitz in Seoul. Vor dieser Rolle arbeitete Kownyul als Softwareentwicklungsingenieur bei AWS mit einem Fokus auf AWS CDK und Amazon Sagemaker.
Arunprasath Shankar ist ein leitender Architekt für KI/ML -Fachlösungen mit AWS und hilft den globalen Kunden dabei, ihre KI -Lösungen effektiv und effizient in der Cloud zu skalieren. In seiner Freizeit schaut sich Arun gerne Science-Fiction-Filme an und hört klassische Musik.
Satish Upreti ist eine Migrations -Leiterin PSA und Security SMU in der Partnerorganisation in APJ. Satish verfügt über 20 Jahre Erfahrung in Bezug auf private Cloud- und öffentliche Cloud-Technologien. Seit er im August 2020 als Migrationsspezialist zu AWS eintritt, bietet er AWS -Partnern umfangreiche technische Beratung und Unterstützung, um komplexe Migrationen zu planen und umzusetzen.
In diesem Abschnitt geben wir einen Überblick über den Code in diesem Projekt.
AWS CDK -Anwendung
Die Haupt -AWS -CDK -Anwendung ist in der app.py -Datei im Stammverzeichnis enthalten. Das Projekt besteht aus mehreren Stapeln, daher müssen wir die Stapel importieren:
#!/usr/bin/env python3
import aws_cdk as cdk
from stack . generative_ai_vpc_network_stack import GenerativeAiVpcNetworkStack
from stack . generative_ai_demo_web_stack import GenerativeAiDemoWebStack
from stack . generative_ai_txt2nlu_sagemaker_stack import GenerativeAiTxt2nluSagemakerStack
from stack . generative_ai_txt2img_sagemaker_stack import GenerativeAiTxt2imgSagemakerStackWir definieren unsere generativen KI -Modelle und erhalten die zugehörigen URIs von Sagemaker:
from script . sagemaker_uri import *
import boto3
region_name = boto3 . Session (). region_name
env = { "region" : region_name }
#Text to Image model parameters
TXT2IMG_MODEL_ID = "model-txt2img-stabilityai-stable-diffusion-v2-1-base"
TXT2IMG_INFERENCE_INSTANCE_TYPE = "ml.g4dn.4xlarge"
TXT2IMG_MODEL_TASK_TYPE = "txt2img"
TXT2IMG_MODEL_INFO = get_sagemaker_uris ( model_id = TXT2IMG_MODEL_ID ,
model_task_type = TXT2IMG_MODEL_TASK_TYPE ,
instance_type = TXT2IMG_INFERENCE_INSTANCE_TYPE ,
region_name = region_name )
#Text to NLU image model parameters
TXT2NLU_MODEL_ID = "huggingface-text2text-flan-t5-xl"
TXT2NLU_INFERENCE_INSTANCE_TYPE = "ml.g4dn.4xlarge"
TXT2NLU_MODEL_TASK_TYPE = "text2text"
TXT2NLU_MODEL_INFO = get_sagemaker_uris ( model_id = TXT2NLU_MODEL_ID ,
model_task_type = TXT2NLU_MODEL_TASK_TYPE ,
instance_type = TXT2NLU_INFERENCE_INSTANCE_TYPE ,
region_name = region_name ) Die Funktion get_sagemaker_uris ruft alle Modellinformationen von Amazon Jumpstart ab. Siehe Skript/Sagemaker_uri.py.
Dann instanziieren wir die Stapel:
app = cdk . App ()
network_stack = GenerativeAiVpcNetworkStack ( app , "GenerativeAiVpcNetworkStack" , env = env )
GenerativeAiDemoWebStack ( app , "GenerativeAiDemoWebStack" , vpc = network_stack . vpc , env = env )
GenerativeAiTxt2nluSagemakerStack ( app , "GenerativeAiTxt2nluSagemakerStack" , env = env , model_info = TXT2NLU_MODEL_INFO )
GenerativeAiTxt2imgSagemakerStack ( app , "GenerativeAiTxt2imgSagemakerStack" , env = env , model_info = TXT2IMG_MODEL_INFO )
app . synth () Der erste Stapel, der auf den Markt kommt, ist der VPC Stack, GenerativeAiVpcNetworkStack . Der Web -Anwendungsstack, GenerativeAiDemoWebStack , ist vom VPC -Stack abhängig. Die Abhängigkeit erfolgt über Parameter vpc=network_stack.vpc übergeben werden.
Siehe App.py für den vollständigen Code.
VPC Network Stack
Im GenerativeAiVpcNetworkStack -Stack erstellen wir ein VPC mit einem öffentlichen Subnetz und einem privaten Subnetz in zwei Verfügbarkeitszonen (AZS):
self . output_vpc = ec2 . Vpc ( self , "VPC" ,
nat_gateways = 1 ,
ip_addresses = ec2 . IpAddresses . cidr ( "10.0.0.0/16" ),
max_azs = 2 ,
subnet_configuration = [
ec2 . SubnetConfiguration ( name = "public" , subnet_type = ec2 . SubnetType . PUBLIC , cidr_mask = 24 ),
ec2 . SubnetConfiguration ( name = "private" , subnet_type = ec2 . SubnetType . PRIVATE_WITH_EGRESS , cidr_mask = 24 )
]
)Siehe /stack/generative_ai_vpc_network_stack.py für den vollständigen Code.
Demo -Webanwendungsstack
Im GenerativeAiDemoWebStack -Stack starten wir Lambda -Funktionen und die jeweiligen Amazon -API -Gateway -Endpunkte, über die die Webanwendung mit den Endpunkten des Sagemaker -Modells interagiert. Siehe den folgenden Code -Snippet:
# Defines an AWS Lambda function for Image Generation service
lambda_txt2img = _lambda . Function (
self , "lambda_txt2img" ,
runtime = _lambda . Runtime . PYTHON_3_9 ,
code = _lambda . Code . from_asset ( "code/lambda_txt2img" ),
handler = "txt2img.lambda_handler" ,
role = role ,
timeout = Duration . seconds ( 180 ),
memory_size = 512 ,
vpc_subnets = ec2 . SubnetSelection (
subnet_type = ec2 . SubnetType . PRIVATE_WITH_EGRESS
),
vpc = vpc
)
# Defines an Amazon API Gateway endpoint for Image Generation service
txt2img_apigw_endpoint = apigw . LambdaRestApi (
self , "txt2img_apigw_endpoint" ,
handler = lambda_txt2img
)Die Webanwendung wird mit Fargate in Amazon ECS Containerisiert und gehostet. Siehe den folgenden Code -Snippet:
# Create Fargate service
fargate_service = ecs_patterns . ApplicationLoadBalancedFargateService (
self , "WebApplication" ,
cluster = cluster , # Required
cpu = 2048 , # Default is 256 (512 is 0.5 vCPU, 2048 is 2 vCPU)
desired_count = 1 , # Default is 1
task_image_options = ecs_patterns . ApplicationLoadBalancedTaskImageOptions (
image = image ,
container_port = 8501 ,
),
#load_balancer_name="gen-ai-demo",
memory_limit_mib = 4096 , # Default is 512
public_load_balancer = True ) # Default is TrueSiehe /stack/generative_ai_demo_web_stack.py für den vollständigen Code.
Bildgenerierung Sagemaker Modellendpunkt Stack
Der GenerativeAiTxt2imgSagemakerStack Stack erstellt den Bildgenerierungsmodellendpunkt aus Sagemaker Jumpstart und speichert den Endpunktnamen im AWS -Systemmanager -Parameterspeicher. Dieser Parameter wird von der Webanwendung verwendet. Siehe den folgenden Code:
endpoint = SageMakerEndpointConstruct ( self , "TXT2IMG" ,
project_prefix = "GenerativeAiDemo" ,
role_arn = role . role_arn ,
model_name = "StableDiffusionText2Img" ,
model_bucket_name = model_info [ "model_bucket_name" ],
model_bucket_key = model_info [ "model_bucket_key" ],
model_docker_image = model_info [ "model_docker_image" ],
variant_name = "AllTraffic" ,
variant_weight = 1 ,
instance_count = 1 ,
instance_type = model_info [ "instance_type" ],
environment = {
"MMS_MAX_RESPONSE_SIZE" : "20000000" ,
"SAGEMAKER_CONTAINER_LOG_LEVEL" : "20" ,
"SAGEMAKER_PROGRAM" : "inference.py" ,
"SAGEMAKER_REGION" : model_info [ "region_name" ],
"SAGEMAKER_SUBMIT_DIRECTORY" : "/opt/ml/model/code" ,
},
deploy_enable = True
)
ssm . StringParameter ( self , "txt2img_sm_endpoint" , parameter_name = "txt2img_sm_endpoint" , string_value = endpoint . endpoint_name )Siehe /stack/generative_ai_txt2img_sagemaker_stack.py für den vollständigen Code.
NLU- und Textgeneration Sagemaker Model Endpoint Stack
Der GenerativeAiTxt2nluSagemakerStack -Stack erstellt den Endpunkt der NLU- und Textgenerierung von Jumpstart und speichert den Endpunktnamen im Systemmanager -Parameterspeicher. Dieser Parameter wird auch von der Webanwendung verwendet. Siehe den folgenden Code:
endpoint = SageMakerEndpointConstruct ( self , "TXT2NLU" ,
project_prefix = "GenerativeAiDemo" ,
role_arn = role . role_arn ,
model_name = "HuggingfaceText2TextFlan" ,
model_bucket_name = model_info [ "model_bucket_name" ],
model_bucket_key = model_info [ "model_bucket_key" ],
model_docker_image = model_info [ "model_docker_image" ],
variant_name = "AllTraffic" ,
variant_weight = 1 ,
instance_count = 1 ,
instance_type = model_info [ "instance_type" ],
environment = {
"MODEL_CACHE_ROOT" : "/opt/ml/model" ,
"SAGEMAKER_ENV" : "1" ,
"SAGEMAKER_MODEL_SERVER_TIMEOUT" : "3600" ,
"SAGEMAKER_MODEL_SERVER_WORKERS" : "1" ,
"SAGEMAKER_PROGRAM" : "inference.py" ,
"SAGEMAKER_SUBMIT_DIRECTORY" : "/opt/ml/model/code/" ,
"TS_DEFAULT_WORKERS_PER_MODEL" : "1"
},
deploy_enable = True
)
ssm . StringParameter ( self , "txt2nlu_sm_endpoint" , parameter_name = "txt2nlu_sm_endpoint" , string_value = endpoint . endpoint_name )Siehe /stack/generative_ai_txt2nlu_sagemaker_stack.py für den vollständigen Code.
Die Webanwendung
Die Webanwendung befindet sich im Verzeichnis /Web-App. Es handelt sich um eine stromleuchte Anwendung, die gemäß der Dockerfile containeriert wird:
FROM --platform=linux/x86_64 python:3.9
EXPOSE 8501
WORKDIR /app
COPY requirements.txt ./requirements.txt
RUN pip3 install -r requirements.txt
COPY . .
CMD streamlit run Home.py
--server.headless true
--browser.serverAddress= "0.0.0.0"
--server.enableCORS false
--browser.gatherUsageStats falseWeitere Informationen zu Streamlit finden Sie unter streamlit -Dokumentation.


