genai
v2.1.0
Installer | Licence | Code de conduite | Contributif
? Obtenez une aide GPT avec le code, les requêtes SQL, les dataframes, les exceptions et plus encore dans ipython.
? Prend en charge tous les environnements Jupyter, y compris Ipython, JupyterLab, Jupyter Notebook et Notableable.
Tl; dr commence maintenant
%pip install genai
%load_ext genai
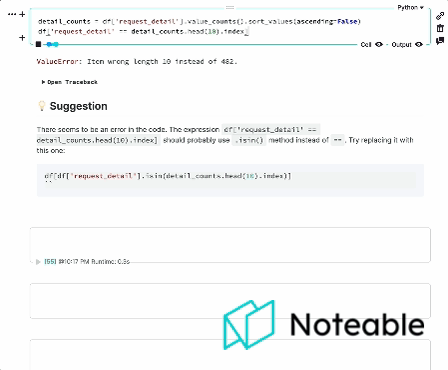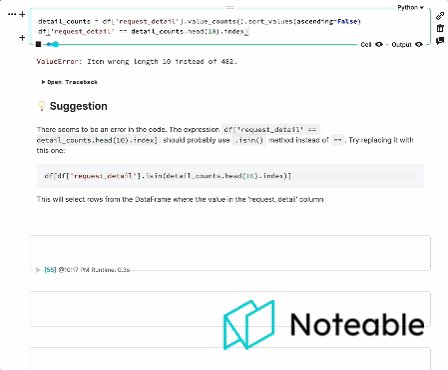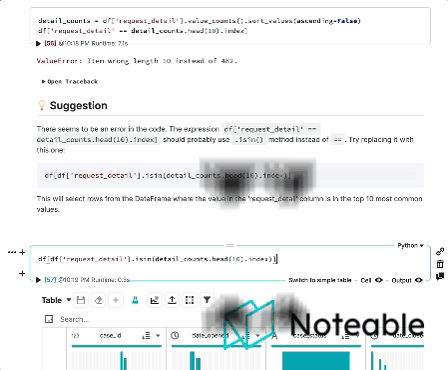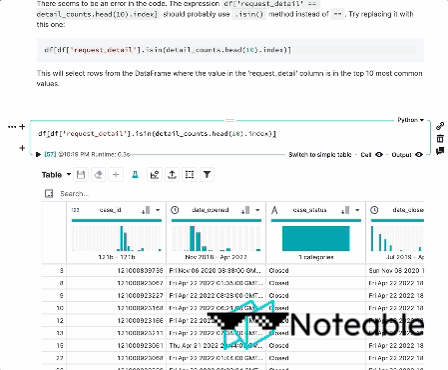
Nous avons pris le contexte d'Ipython, l'avons mélangé avec les grands modèles de langue d'Openai et vous offrons une expérience de ordinateur portable plus éclairée qui fonctionne dans tous les environnements Jupyter, y compris Ipython, JupyterLab, Jupyter Notebook et notable. ??
Python 3.8+
poetry add genaipip install genai Assurez-vous de définir la variable d'environnement OPENAI_API_KEY avant de l'utiliser dans Ipython ou votre plate-forme de carnet de choix préférée.
%load_ext genai
%%assist la commande magique pour générer du code à partir du langage naturel In [ 1 ]: % load_ext genai
In [ 2 ]: import pandas as pd
In [ 3 ]: df = pd . DataFrame ( dict ( col1 = [ 'a' , 'b' , 'c' ]), index = [ 'first' , 'second' , 'third' ])
In [ 4 ]: df . sort_values ()
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
TypeError Traceback ( most recent call last )
Cell In [ 4 ], line 1
- - - - > 1 df . sort_values ()
File ~ / . pyenv / versions / 3.9 . 9 / lib / python3 . 9 / site - packages / pandas / util / _decorators . py : 331 , in deprecate_nonkeyword_arguments . < locals > . decorate . < locals > . wrapper ( * args , ** kwargs )
325 if len ( args ) > num_allow_args :
326 warnings . warn (
327 msg . format ( arguments = _format_argument_list ( allow_args )),
328 FutureWarning ,
329 stacklevel = find_stack_level (),
330 )
- - > 331 return func ( * args , ** kwargs )
TypeError : sort_values () missing 1 required positional argument : 'by' Le message d'erreur indique que la méthode sort_values() d'un pandas dataframe manque un argument de position requis.
La méthode sort_values() vous oblige à passer un nom de colonne ou une liste de noms de colonne comme l'argument by argument. Ceci est utilisé pour déterminer comment le tri sera effectué.
Voici un exemple:
import pandas as pd
df = pd . DataFrame ({
'Name' : [ 'Alice' , 'Bob' , 'Carol' , 'David' , 'Eva' ],
'Age' : [ 32 , 24 , 28 , 35 , 29 ],
'Salary' : [ 60000 , 40000 , 35000 , 80000 , 45000 ]
})
# sort by Age column:
df_sorted = df . sort_values ( by = 'Age' )
print ( df_sorted ) Dans cet exemple, l'argument by est défini sur 'Age' , qui trie le dataframe par âge dans l'ordre croissant. Notez que vous pouvez également transmettre une liste de noms de colonnes si vous souhaitez trier par plusieurs colonnes.
In [ 1 ]: % load_ext genai
In [ 2 ]: % % assist
...:
...: Can you explain this query to me so I can be sure we ' re doing the right things ?
...:
...: `` ` sql
...: SELECT
...: COUNT ( * ) AS num_downloads ,
...: DATE_TRUNC ( DATE ( timestamp ), DAY ) AS day
...: FROM `bigquery-public-data.pypi.file_downloads`
...: WHERE
...: file . project = 'genai'
...: - - Only query the last 6 months of history
...: AND DATE ( timestamp )
...: BETWEEN DATE_TRUNC ( DATE_SUB ( CURRENT_DATE (), INTERVAL 6 MONTH ), MONTH )
...: AND CURRENT_DATE ()
...: GROUP BY day
...: ORDER BY day DESC "This is a SQL query that counts the number of downloads for the 'genai' project on the Python Package Index (PyPI) over the last 6 months, grouped by day. The query selects the count and the date, truncating the date to the day level so that it's easier to read.
Here is a breakdown of each part of the query:
- ` SELECT COUNT(*) AS num_downloads, DATE_TRUNC(DATE(timestamp), DAY) AS day ` : This selects the count of the number of rows matched by the query as ` num_downloads ` , and the date truncated to the day level as ` day ` .
- ` FROM ` bigquery-public-data.pypi.file_downloads``: This specifies the table to query from.
- ` WHERE file.project = 'genai' ` : This filters the rows by only including downloads for the 'genai' project.
- ` AND DATE(timestamp) BETWEEN DATE_TRUNC(DATE_SUB(CURRENT_DATE(), INTERVAL 6 MONTH), MONTH) AND CURRENT_DATE() ` : This filters the rows by only including downloads from the last 6 months. The ` DATE_SUB ` function subtracts 6 months from the current date ( ` CURRENT_DATE() ` ), ` DATE_TRUNC ` truncates the result to be the start of the month and ` DATE ` converts the timestamp column to a date so the ` BETWEEN ` condition can filter rows between the start of 6 months ago and "today."
- ` GROUP BY day ` : This groups the rows by day so that the counts are aggregated by date.
- ` ORDER BY day DESC ` : This orders the rows so that the most recent date appears first in the result."

