genai
v2.1.0
Instalar | Licencia | Código de conducta | Que contribuye
? Obtenga ayuda GPT con código, consultas SQL, marcos de datos, excepciones y más en Ipython.
? Admite todos los entornos Jupyter, incluidos Ipython, Jupyterlab, Jupyter Notebook y notable.
Tl; Dr empieza ahora
%pip install genai
%load_ext genai
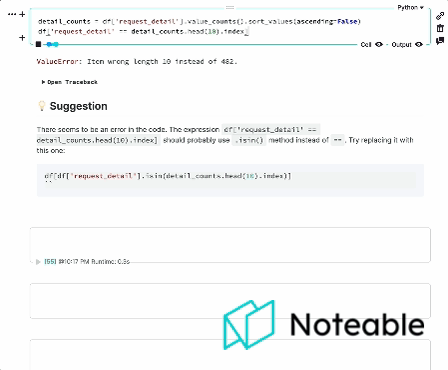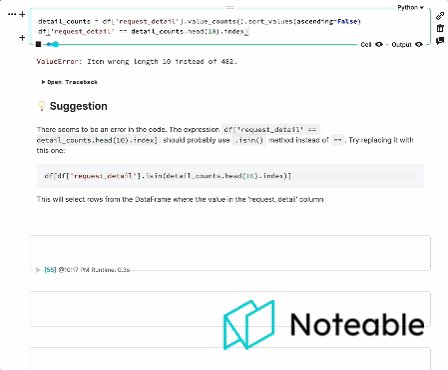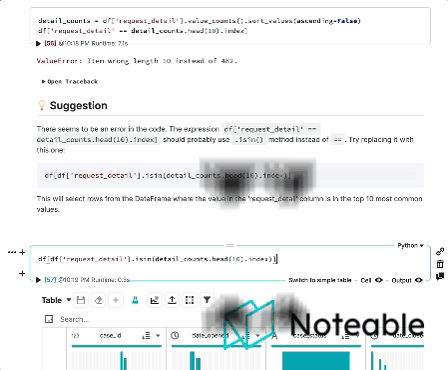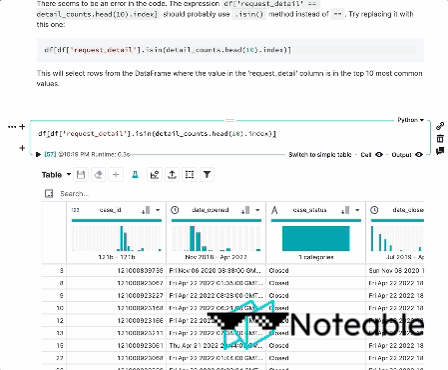
Hemos tomado el contexto de Ipython, lo mezclamos con los modelos de idiomas grandes de Openai y le brindamos una experiencia de cuaderno más informada que funciona en todos los entornos Jupyter, incluidos Ipython, Jupyterlab, Jupyter Notebook y notable. ?
Python 3.8+
poetry add genaipip install genai Asegúrese de establecer la variable de entorno OPENAI_API_KEY primero antes de usarla en Ipython o en su plataforma de cuaderno preferido de elección.
%load_ext genai
%%assist Magic Command para generar código desde el lenguaje natural In [ 1 ]: % load_ext genai
In [ 2 ]: import pandas as pd
In [ 3 ]: df = pd . DataFrame ( dict ( col1 = [ 'a' , 'b' , 'c' ]), index = [ 'first' , 'second' , 'third' ])
In [ 4 ]: df . sort_values ()
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
TypeError Traceback ( most recent call last )
Cell In [ 4 ], line 1
- - - - > 1 df . sort_values ()
File ~ / . pyenv / versions / 3.9 . 9 / lib / python3 . 9 / site - packages / pandas / util / _decorators . py : 331 , in deprecate_nonkeyword_arguments . < locals > . decorate . < locals > . wrapper ( * args , ** kwargs )
325 if len ( args ) > num_allow_args :
326 warnings . warn (
327 msg . format ( arguments = _format_argument_list ( allow_args )),
328 FutureWarning ,
329 stacklevel = find_stack_level (),
330 )
- - > 331 return func ( * args , ** kwargs )
TypeError : sort_values () missing 1 required positional argument : 'by' El mensaje de error indica que el método sort_values() de un marco de datos pandas le falta un argumento posicional requerido.
El método sort_values() requiere que pase un nombre de columna o lista de nombres de columna como by . Esto se usa para determinar cómo se realizará la clasificación.
Aquí hay un ejemplo:
import pandas as pd
df = pd . DataFrame ({
'Name' : [ 'Alice' , 'Bob' , 'Carol' , 'David' , 'Eva' ],
'Age' : [ 32 , 24 , 28 , 35 , 29 ],
'Salary' : [ 60000 , 40000 , 35000 , 80000 , 45000 ]
})
# sort by Age column:
df_sorted = df . sort_values ( by = 'Age' )
print ( df_sorted ) En este ejemplo, el by se establece en 'Age' , que clasifica el marco de datos por edad en orden ascendente. Tenga en cuenta que también puede pasar una lista de nombres de columnas si desea ordenar por varias columnas.
In [ 1 ]: % load_ext genai
In [ 2 ]: % % assist
...:
...: Can you explain this query to me so I can be sure we ' re doing the right things ?
...:
...: `` ` sql
...: SELECT
...: COUNT ( * ) AS num_downloads ,
...: DATE_TRUNC ( DATE ( timestamp ), DAY ) AS day
...: FROM `bigquery-public-data.pypi.file_downloads`
...: WHERE
...: file . project = 'genai'
...: - - Only query the last 6 months of history
...: AND DATE ( timestamp )
...: BETWEEN DATE_TRUNC ( DATE_SUB ( CURRENT_DATE (), INTERVAL 6 MONTH ), MONTH )
...: AND CURRENT_DATE ()
...: GROUP BY day
...: ORDER BY day DESC "This is a SQL query that counts the number of downloads for the 'genai' project on the Python Package Index (PyPI) over the last 6 months, grouped by day. The query selects the count and the date, truncating the date to the day level so that it's easier to read.
Here is a breakdown of each part of the query:
- ` SELECT COUNT(*) AS num_downloads, DATE_TRUNC(DATE(timestamp), DAY) AS day ` : This selects the count of the number of rows matched by the query as ` num_downloads ` , and the date truncated to the day level as ` day ` .
- ` FROM ` bigquery-public-data.pypi.file_downloads``: This specifies the table to query from.
- ` WHERE file.project = 'genai' ` : This filters the rows by only including downloads for the 'genai' project.
- ` AND DATE(timestamp) BETWEEN DATE_TRUNC(DATE_SUB(CURRENT_DATE(), INTERVAL 6 MONTH), MONTH) AND CURRENT_DATE() ` : This filters the rows by only including downloads from the last 6 months. The ` DATE_SUB ` function subtracts 6 months from the current date ( ` CURRENT_DATE() ` ), ` DATE_TRUNC ` truncates the result to be the start of the month and ` DATE ` converts the timestamp column to a date so the ` BETWEEN ` condition can filter rows between the start of 6 months ago and "today."
- ` GROUP BY day ` : This groups the rows by day so that the counts are aggregated by date.
- ` ORDER BY day DESC ` : This orders the rows so that the most recent date appears first in the result."

