AgentReview
1.0.0
| titre | emoji | couleur | colort | SDK | sdk_version | app_file | épinglé | licence | short_description |
|---|---|---|---|---|---|---|---|---|---|
AgentReview | ? | indigo | rose | gradio | 5.4.0 | app.py | FAUX | apache-2.0 | EMNLP 2024 |
Mise en œuvre officielle du document (ORAL) «EMNLP 2024 Piste principale (oral) - AgentReview: Exploration de la dynamique de la revue par les pairs avec des agents LLM
Demo | Site Web | ? Papier | ? Arxiv | Code
@inproceedings { jin2024agentreview ,
title = { AgentReview: Exploring Peer Review Dynamics with LLM Agents } ,
author = { Jin, Yiqiao and Zhao, Qinlin and Wang, Yiyang and Chen, Hao and Zhu, Kaijie and Xiao, Yijia and Wang, Jindong } ,
booktitle = { EMNLP } ,
year = { 2024 }
}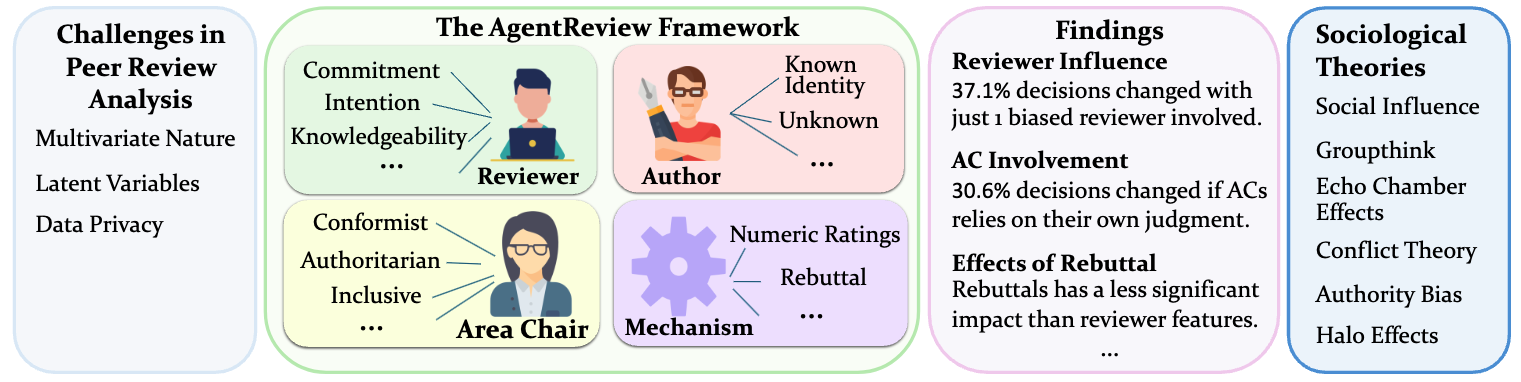
AgentReview est un cadre basé sur le modèle de grand langage (LLM) pionnier pour simuler les processus d'examen par les pairs, développés pour analyser et aborder les facteurs complexes et multivariés influençant les résultats de la revue. Contrairement aux méthodes statistiques traditionnelles, AgentReview capture les variables latentes tout en respectant la confidentialité des données de revue des pairs sensibles.
L'examen par les pairs est fondamental pour l'intégrité et l'avancement de la publication scientifique. Les méthodes traditionnelles de revue par les pairs analysent souvent l'exploration et les statistiques des données existantes d'examen par les pairs, qui ne traitent pas adéquatement la nature multivariée du processus, expliquent les variables latentes et sont davantage limitées par les problèmes de confidentialité en raison de la nature sensible des données. Nous introduisons AgentReview, le premier cadre de simulation de revue par les pairs de modèle de grande langue (LLM), qui démêle efficacement les impacts de plusieurs facteurs latents et aborde le problème de confidentialité. Notre étude révèle des informations importantes, notamment une variation notable de 37,1% des décisions sur papier dues aux préjugés des examinateurs, soutenues par des théories sociologiques telles que la théorie de l'influence sociale, la fatigue de l'altruisme et le biais de l'autorité. Nous pensons que cette étude pourrait offrir des informations précieuses pour améliorer la conception des mécanismes d'examen par les pairs.
Télécharger les données
Téléchargez les deux fichiers zip dans cette Dropbox:
Unzip agentreview_paper_data.zip sous data/ , qui contient:
unzip AgentReview_Paper_Data.zip -d data/ (Facultatif) Unzip AgentReview_llm_reviews.zip sous outputs/ , qui contient les avis générés par LLM, (notre ensemble de données généré par LLM)
unzip AgentReview_LLM_Review.zip -d outputs/Installer les packages requis :
cd AgentReview/
pip install -r requirements.txt
Si vous utilisez l'API OpenAI, définissez Openai_API_KEY.
export OPENAI_API_KEY=... # Format: sk-...Si vous utilisez l'API AzureOpenai, définissez ce qui suit
export AZURE_ENDPOINT=... # Format: https://<your-endpoint>.openai.azure.com/
export AZURE_DEPLOYMENT=... # Your Azure OpenAI deployment here
export AZURE_OPENAI_KEY=... # Your Azure OpenAI key hereExécuter le projet
Définissez les variables d'environnement dans run.sh et exécutez-la:
bash run.sh Remarque: Tous les fichiers du projet doivent être exécutés à partir du répertoire AgentReview .
Démo
Une démo peut être trouvée dans notebooks/demo.ipynb
Vous pouvez ajouter un nouveau paramètre dans agentreview/experiment_config.py , puis ajouter le paramètre en tant que nouvelle entrée au dictionnaire all_settings :
all_settings = {
"BASELINE" : baseline_setting ,
"benign_Rx1" : benign_Rx1_setting ,
...
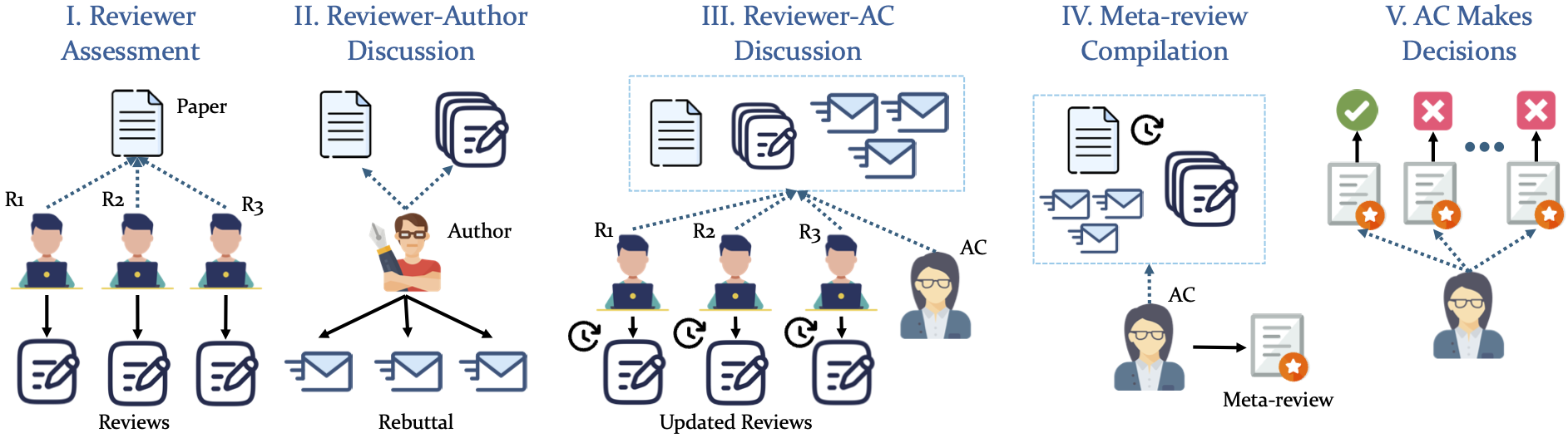
" your_setting_name ": your_setting Notre simulation adopte un pipeline structuré en 5 phases
Ce projet est concédé sous licence Apache-2.0.
L'implémentation est partiellement basée sur le cadre Chatarena.


