AgentReview
1.0.0
| title | emoji | colorFrom | colorTo | sdk | sdk_version | app_file | pinned | license | short_description |
|---|---|---|---|---|---|---|---|---|---|
AgentReview |
? |
indigo |
pink |
gradio |
5.4.0 |
app.py |
false |
apache-2.0 |
EMNLP 2024 |
Official implementation for the ?EMNLP 2024 main track (Oral) paper -- AgentReview: Exploring Peer Review Dynamics with LLM Agents
Demo | Website | ? Paper | ?arXiv | Code
@inproceedings{jin2024agentreview,
title={AgentReview: Exploring Peer Review Dynamics with LLM Agents},
author={Jin, Yiqiao and Zhao, Qinlin and Wang, Yiyang and Chen, Hao and Zhu, Kaijie and Xiao, Yijia and Wang, Jindong},
booktitle={EMNLP},
year={2024}
}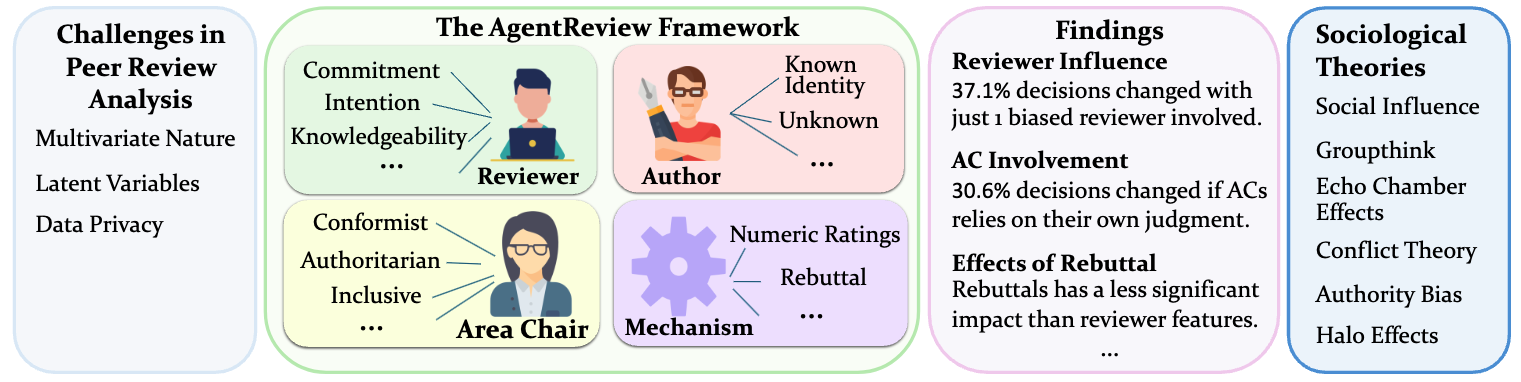
AgentReview is a pioneering large language model (LLM)-based framework for simulating peer review processes, developed to analyze and address the complex, multivariate factors influencing review outcomes. Unlike traditional statistical methods, AgentReview captures latent variables while respecting the privacy of sensitive peer review data.
Peer review is fundamental to the integrity and advancement of scientific publication. Traditional methods of peer review analyses often rely on exploration and statistics of existing peer review data, which do not adequately address the multivariate nature of the process, account for the latent variables, and are further constrained by privacy concerns due to the sensitive nature of the data. We introduce AgentReview, the first large language model (LLM) based peer review simulation framework, which effectively disentangles the impacts of multiple latent factors and addresses the privacy issue. Our study reveals significant insights, including a notable 37.1% variation in paper decisions due to reviewers' biases, supported by sociological theories such as the social influence theory, altruism fatigue, and authority bias. We believe that this study could offer valuable insights to improve the design of peer review mechanisms.
Download the data
Download both zip files in this Dropbox:
Unzip AgentReview_Paper_Data.zip under data/, which contains:
unzip AgentReview_Paper_Data.zip -d data/(Optional) Unzip AgentReview_LLM_Reviews.zip under outputs/, which contains the LLM-generated reviews, (our LLM-generated dataset)
unzip AgentReview_LLM_Review.zip -d outputs/Install Required Packages:
cd AgentReview/
pip install -r requirements.txt
If you use OpenAI API, set OPENAI_API_KEY.
export OPENAI_API_KEY=... # Format: sk-...If you use AzureOpenAI API, set the following
export AZURE_ENDPOINT=... # Format: https://<your-endpoint>.openai.azure.com/
export AZURE_DEPLOYMENT=... # Your Azure OpenAI deployment here
export AZURE_OPENAI_KEY=... # Your Azure OpenAI key hereRunning the Project
Set the environment variables in run.sh and run it:
bash run.shNote: all project files should be run from the AgentReview directory.
Demo
A demo can be found in notebooks/demo.ipynb
You can add a new setting in agentreview/experiment_config.py, then add the setting as a new entry to the all_settings dictionary:
all_settings = {
"BASELINE": baseline_setting,
"benign_Rx1": benign_Rx1_setting,
...
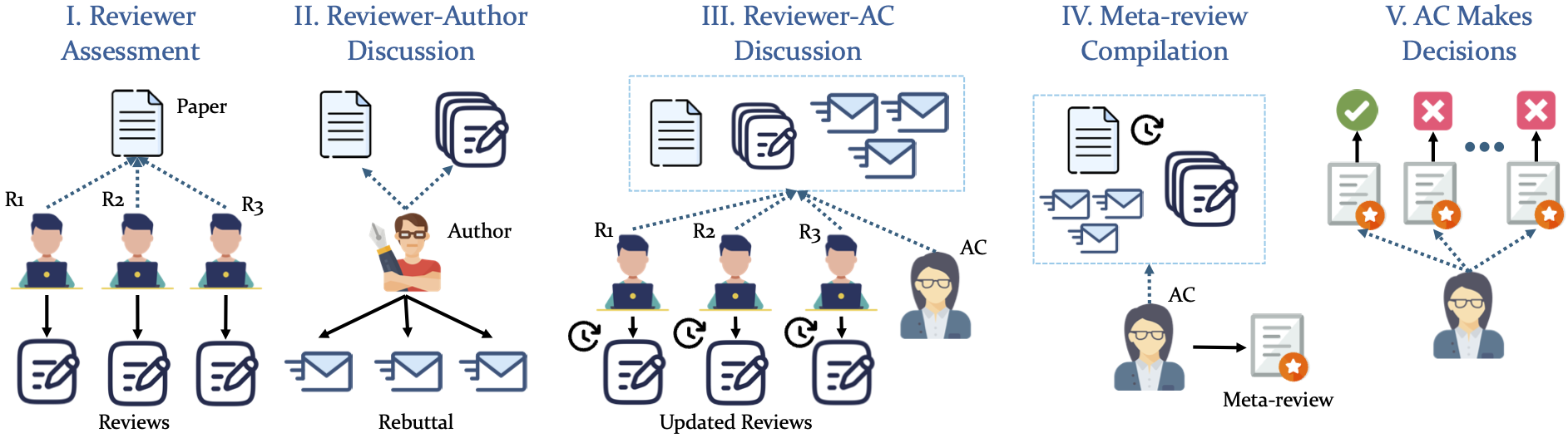
"your_setting_name": your_settingOur simulation adopts a structured, 5-phase pipeline
This project is licensed under the Apache-2.0 License.
The implementation is partially based on the chatarena framework.


