neural ngram
1.0.0
神經概率語言模型的Pytorch實施。基於Pytorch示例Word Level語言模型的培訓和數據加載代碼。
要獲取Wikitext-2數據集,請運行:
./get-data.sh一個單詞級別的示例:
./main.py train --name wiki --order 5 --batch-size 32角色級別的示例:
./main.py train --name wiki-char --use-char --order 12 --emb-dim 20 --batch-size 1024如果您曾經有過手套矢量,則可以使用這些媒介:
./main.py train --name wiki --use-glove --glove-dir your/glove/dir --emb-dim 50其他一些數據參數是:
--lower # Lowercase all words in training data.
--no-headers # Remove all headers such as `=== History ===`. 有了以下論點,一個時期大約需要45分鐘:
./main.py train --name wiki --order 5 --use-glove --emb-dim 50 --hidden-dims 100
--batch-size 128 --epochs 10 # Test perplexity 224.89 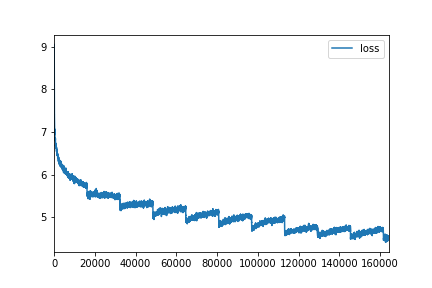
我們可以探索限制:
./main.py train --name wiki --order 13 --emb-dim 100 --hidden-dims 500
--epochs 40 --batch-size 512 --dropout 0.5 # Test perplexity 153.12 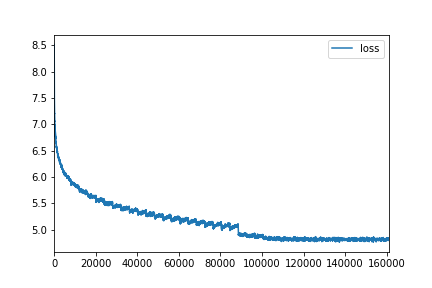
./main.py train --name wiki --order 13 --emb-dim 300 --hidden-dims 1400
--epochs 40 --batch-size 256 --dropout 0.65 # Test perplexity 152.64 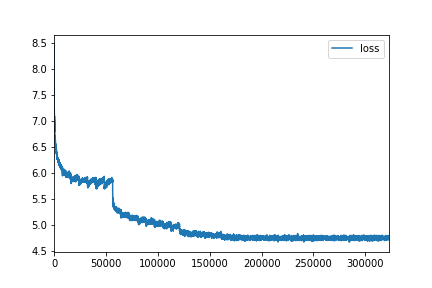
要生成文本,請使用:
./main.py generate --checkpoint path/to/saved/model <eos>令牌被換用的線代替,其餘的按原樣打印。
其他一代論點是:
--temperature 0.9 # Temperature to manipulate distribution.
--start # Provide an optional start of the generated text (can be longer than order)
--no-unk # Do not generate unks, especially useful for low --temperature.
--no-sos # Do not print <sos> tokens請參閱generate.txt中的一些生成文本。
要可視化模型的訓練嵌入,請使用:
./main.py plot --checkpoint path/to/saved/model這與數據集中1000個最常見單詞的K-Means群集著色擬合了2D T-SNE圖。對於T-SNE和K-均值的繪圖和Scikit-Learn的需要。
在此處查看示例HTML。 (github不會渲染HTML文件。渲染,下載和打開或使用此鏈接。)
python>=3.6
torch==0.3.0.post4
numpy
tqdm


