neural ngram
1.0.0
신경 확률 언어 모델의 Pytorch 구현. Pytorch 예제 워드 레벨 언어 모델을 기반으로 한 교육 및 데이터 로딩 코드.
Wikitext-2 데이터 세트를 얻으려면 실행 :
./get-data.sh단어 수준 예 :
./main.py train --name wiki --order 5 --batch-size 32문자 수준 예 :
./main.py train --name wiki-char --use-char --order 12 --emb-dim 20 --batch-size 1024사전 입사 장갑 벡터가 있다면 다음을 사용할 수 있습니다.
./main.py train --name wiki --use-glove --glove-dir your/glove/dir --emb-dim 50다른 데이터 인수는 다음과 같습니다.
--lower # Lowercase all words in training data.
--no-headers # Remove all headers such as `=== History ===`. 다음 논쟁에서 하나의 에포크는 약 45 분이 걸립니다.
./main.py train --name wiki --order 5 --use-glove --emb-dim 50 --hidden-dims 100
--batch-size 128 --epochs 10 # Test perplexity 224.89 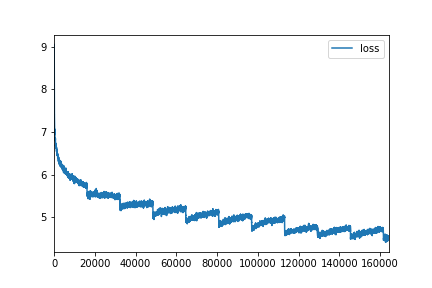
한계를 탐색 할 수 있습니다.
./main.py train --name wiki --order 13 --emb-dim 100 --hidden-dims 500
--epochs 40 --batch-size 512 --dropout 0.5 # Test perplexity 153.12 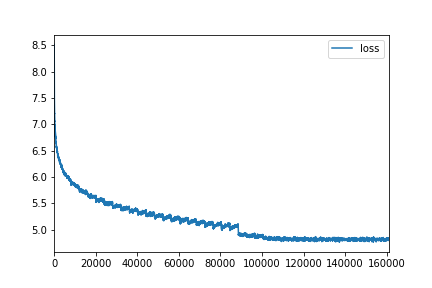
./main.py train --name wiki --order 13 --emb-dim 300 --hidden-dims 1400
--epochs 40 --batch-size 256 --dropout 0.65 # Test perplexity 152.64 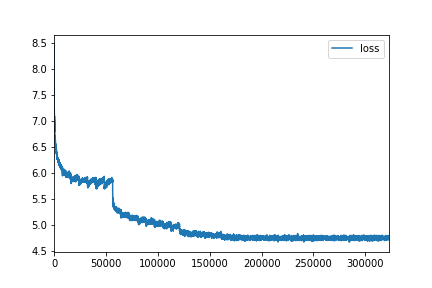
텍스트를 생성하려면 사용하십시오.
./main.py generate --checkpoint path/to/saved/model <eos> 토큰은 Newline으로 대체되고 나머지는 그대로 인쇄됩니다.
다른 세대 주장은 다음과 같습니다.
--temperature 0.9 # Temperature to manipulate distribution.
--start # Provide an optional start of the generated text (can be longer than order)
--no-unk # Do not generate unks, especially useful for low --temperature.
--no-sos # Do not print <sos> tokensGenerate.txt에서 생성 된 텍스트를 참조하십시오.
모델의 훈련 된 임베딩을 시각화하려면 다음을 사용하십시오.
./main.py plot --checkpoint path/to/saved/model이것은 데이터 세트에서 1000 개의 가장 일반적인 단어의 k-means 클러스터 색칠과 함께 2D t-sne 플롯에 맞습니다. T-SNE 및 K-MEAN의 경우 보케가 플로팅 및 Scikit-Learn을 요구합니다.
여기에서 HTML 예를 참조하십시오. (Github는 HTML 파일을 렌더링하지 않습니다.이 링크 렌더링, 다운로드 및 열기 또는 사용하려면).
python>=3.6
torch==0.3.0.post4
numpy
tqdm


