neural ngram
1.0.0
神経確率論的言語モデルのPytorch実装。 Pytorchの例の単語レベル言語モデルに基づくトレーニングとデータロードのコード。
wikitext-2データセットを取得するには、実行してください。
./get-data.sh単語レベルの例:
./main.py train --name wiki --order 5 --batch-size 32キャラクターレベルの例:
./main.py train --name wiki-char --use-char --order 12 --emb-dim 20 --batch-size 1024前提条件のグローブベクターがある場合は、次のことを使用できます。
./main.py train --name wiki --use-glove --glove-dir your/glove/dir --emb-dim 50他のデータの引数は次のとおりです。
--lower # Lowercase all words in training data.
--no-headers # Remove all headers such as `=== History ===`. 次の議論で、1つのエポックには約45分かかります。
./main.py train --name wiki --order 5 --use-glove --emb-dim 50 --hidden-dims 100
--batch-size 128 --epochs 10 # Test perplexity 224.89 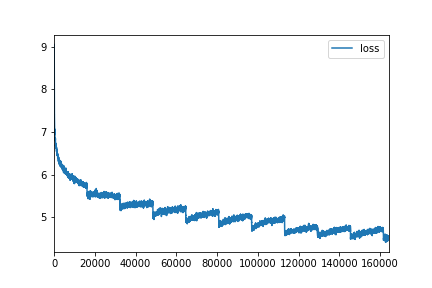
制限を探ることができます:
./main.py train --name wiki --order 13 --emb-dim 100 --hidden-dims 500
--epochs 40 --batch-size 512 --dropout 0.5 # Test perplexity 153.12 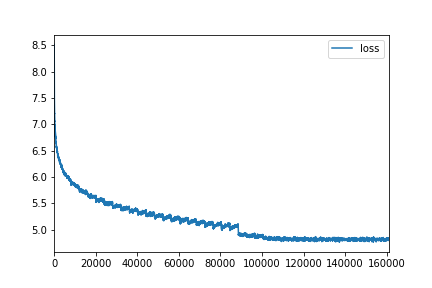
./main.py train --name wiki --order 13 --emb-dim 300 --hidden-dims 1400
--epochs 40 --batch-size 256 --dropout 0.65 # Test perplexity 152.64 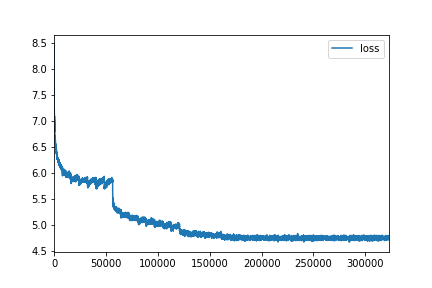
テキストを生成するには、使用してください。
./main.py generate --checkpoint path/to/saved/model <eos>トークンは新しいラインに置き換えられ、残りはそのまま印刷されます。
他の世代の議論は次のとおりです。
--temperature 0.9 # Temperature to manipulate distribution.
--start # Provide an optional start of the generated text (can be longer than order)
--no-unk # Do not generate unks, especially useful for low --temperature.
--no-sos # Do not print <sos> tokensGenerate.txtの生成されたテキストをご覧ください。
モデルの訓練された埋め込みを視覚化するには、以下を使用してください。
./main.py plot --checkpoint path/to/saved/modelこれは、データセット内の1000の最も一般的な単語のk-meansクラスターカラーリングを備えた2D T-SNEプロットに適合します。これには、T-SNEおよびK-meansのプロットとScikit-LearnのためにBokehが必要です。
ここでHTMLの例を参照してください。 (GitHubはHTMLファイルをレンダリングしません。このリンクをレンダリング、ダウンロード、開く、または使用します。)
python>=3.6
torch==0.3.0.post4
numpy
tqdm


