neural ngram
1.0.0
تنفيذ Pytorch لنموذج اللغة الاحتمالية العصبية. رمز للتدريب وتحميل البيانات استنادًا إلى نموذج لغة مستوى Word Pytorch.
للحصول على مجموعة بيانات Wikitext-2 ، قم بتشغيل:
./get-data.shمثال على مستوى الكلمات:
./main.py train --name wiki --order 5 --batch-size 32مثال على مستوى الشخصية:
./main.py train --name wiki-char --use-char --order 12 --emb-dim 20 --batch-size 1024إذا كان لديك ناقلات قفازات مسبقة ، فيمكنك استخدامها:
./main.py train --name wiki --use-glove --glove-dir your/glove/dir --emb-dim 50بعض وسائط البيانات الأخرى هي:
--lower # Lowercase all words in training data.
--no-headers # Remove all headers such as `=== History ===`. مع الحجج التالية ، تستغرق الحقبة حوالي 45 دقيقة:
./main.py train --name wiki --order 5 --use-glove --emb-dim 50 --hidden-dims 100
--batch-size 128 --epochs 10 # Test perplexity 224.89 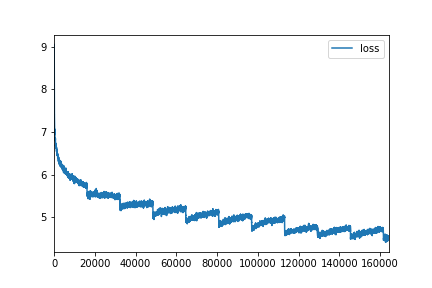
يمكننا استكشاف الحدود:
./main.py train --name wiki --order 13 --emb-dim 100 --hidden-dims 500
--epochs 40 --batch-size 512 --dropout 0.5 # Test perplexity 153.12 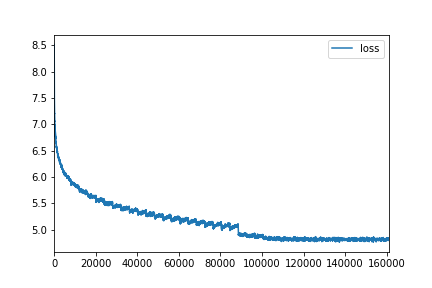
./main.py train --name wiki --order 13 --emb-dim 300 --hidden-dims 1400
--epochs 40 --batch-size 256 --dropout 0.65 # Test perplexity 152.64 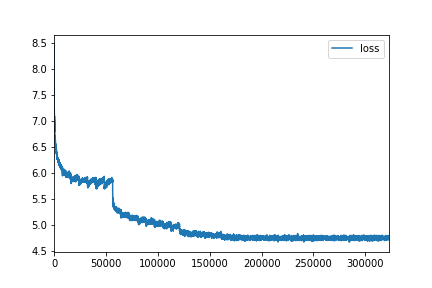
لإنشاء نص ، استخدم:
./main.py generate --checkpoint path/to/saved/model يتم استبدال الرمز المميز <eos> بخط جديد ، ويتم طباعة الباقي كما هو.
حجج الجيل الأخرى هي:
--temperature 0.9 # Temperature to manipulate distribution.
--start # Provide an optional start of the generated text (can be longer than order)
--no-unk # Do not generate unks, especially useful for low --temperature.
--no-sos # Do not print <sos> tokensانظر بعض النص الذي تم إنشاؤه في cender.txt.
لتصور التضمينات المدربة للنموذج ، استخدم:
./main.py plot --checkpoint path/to/saved/modelهذا يناسب قطعة مؤامرة ثنائية الأبعاد مع تلوين مجموعة K-Means من 1000 كلمة شائعة في مجموعة البيانات. يتطلب خوخه للتخطيط والتعلم scikit من أجل t-sne و K-means.
انظر مثال HTML هنا. (لا يؤدي Github إلى تقديم ملفات HTML. لتقديم هذا الرابط أو تنزيله أو فتحه أو استخدامه.)
python>=3.6
torch==0.3.0.post4
numpy
tqdm


