awd lstm tensorflow
1.0.0
來自(“正規化和優化LSTM語言模型”)的AWD-LSTM用於TensorFlow。
訓練量量化的量化量化量化的量化量化的量化量化(“還提供了“有效整數僅推斷的神經網絡的量化和培訓”)。
該代碼已進行了tensorflow 1.11.0的實施和測試。和1.13.0。
LayerRNNCell 。 from weight_drop_lstm import WeightDropLSTMCell
lstm_cell = WeightDropLSTMCell(
num_units=CELL_NUM, weight_drop_kr=WEIGHT_DP_KR,
use_vd=True, input_size=INPUT_SIZE)
參數定義如下:
num_units:LSTM層中的單元格數。 [int]
weight_drop_kr:快速權重的步驟數。 [int]
use_vd:如果為true,則在重量下降連接上使用變分輟學,否則使用標準輟學。 [bool]
input_size:如果use_vd=True,則應提供input_size(上一個通道的維度)。 [int]
其餘的關鍵字參數與tf.nn.LSTMCell完全相同。
指出,如果未提供或提供1.0的weiver_drop_kr,則WeightDropLSTMCell被減少為LSTMCell 。
# By simply sess.run in each training step
sess.run(lstm_cell.get_vd_update_op())
# Or use control_dependencies
vd_update_ops = lstm_cell.get_vd_update_op()
with tf.control_dependencies(vd_update_ops):
tf.train.AdamOptimizer(learning_rate).minimize(loss)
您還可以在調用WeightDropLSTMCell時將get_vd_update_op()添加到GraphKeys.UPDATE_OPS 。
指出,如果您使用control_dependencies ,請小心執行順序。
在優化器步驟之前,不應更新差異內核。
AWD-LSTM的主要思想是連接的權重和限制輸入。 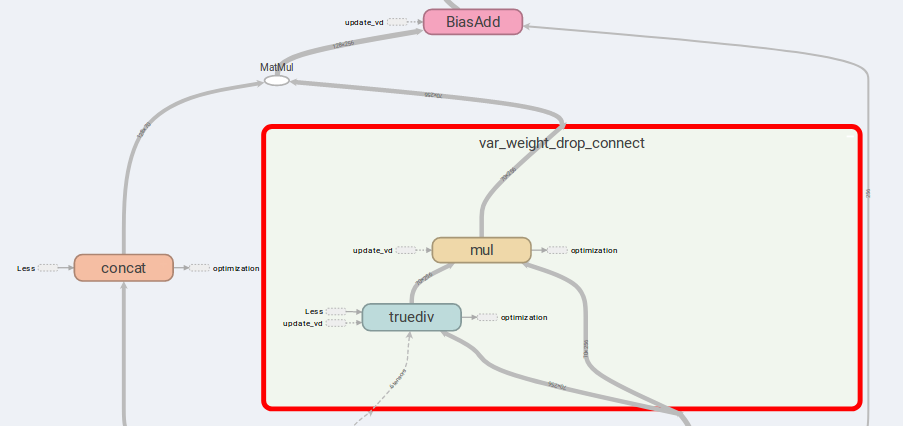
如果is_vd=True ,則將變量用於保存輟學內核。 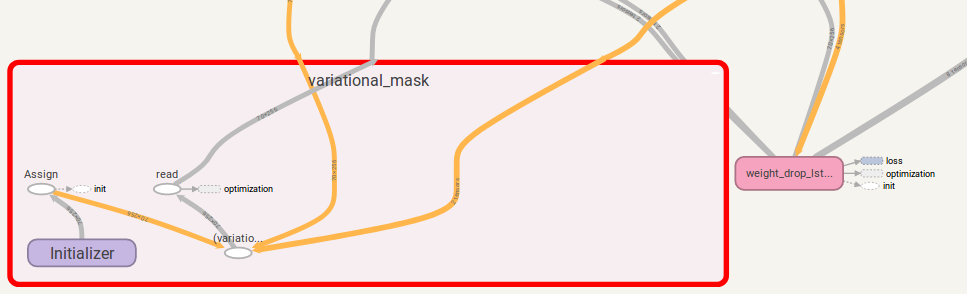
我已經對此實施進行了多對多遞歸任務進行實驗,並且比簡單的LSTMCell進行了更好的結果。
lstm_cell = WeightDropLSTMCell(
num_units=CELL_NUM, weight_drop_kr=WEIGHT_DP_KR,
is_quant=True, is_train=True)
tf.contrib.quantize.create_training_graph(sess.graph, quant_delay=0)
tf.while中出現,而版本高於1.12.0。 我還提供了變異輟學的張量實現,它比TensorFlow中的DropoutWrapper更靈活。
用法類似於使用WeightDropLSTMCell :
from variational_dropout import VariationalDropout
vd = VariationalDropout(input_shape=[5], keep_prob=0.5)
# Directly sess.run() to update
sess.run(vd.get_update_mask_op())
# Or use control_dependencies
with tf.control_dependencies(vd.get_update_mask_op()):
step, results_array = tf.while_loop(
cond=lambda step, _: step < 5,
body=main_loop,
loop_vars=(step, results_array))
"""
This is just a simple example.
Usually, control_dependencies will be placed where optimizer stepping.
"""
您還可以在調用VariationalDropout時將get_update_mask_op()添加到GraphKeys.UPDATE_OPS 。
再一次,如果您使用control_dependencies ,請小心執行順序。
如果您有任何建議,請告訴我。我會很感激!
jia-yau shiau [email protected]的代碼工作。
量化代碼工作建議並從彼得黃[email protected]分叉


