awd lstm tensorflow
1.0.0
AWD-LSTM de ("regularizando y optimización de modelos de lenguaje LSTM") para TensorFlow.
La cuantización del premio para el entrenamiento para la inferencia entera-aritmética solo ("Cuantización y capacitación de redes neuronales para una inferencia eficiente-aritmética de solo aritmética") también se proporciona.
Este código se implementa y se prueba con TensorFlow 1.11.0. y 1.13.0.
LayerRNNCell estándar. from weight_drop_lstm import WeightDropLSTMCell
lstm_cell = WeightDropLSTMCell(
num_units=CELL_NUM, weight_drop_kr=WEIGHT_DP_KR,
use_vd=True, input_size=INPUT_SIZE)
Los argumentos se definen de la siguiente manera:
num_units: el número de celda en la capa LSTM. [INTS]
weight_drop_kr: el número de pasos que avanzan los pesos rápidos. [int]
use_vd: si es verdadero, usando la caída variacional en la conexión de caída de peso, abandono estándar de lo contrario. [bool]
input_size: siuse_vd=True, input_size (dimensión del último canal) se debe proporcionar. [int]
Los argumentos de palabras clave restantes son exactamente los mismos que tf.nn.LSTMCell .
Observó que, si el peso_drop_kr no se proporciona o se proporciona con 1.0, WeightDropLSTMCell se reduce como LSTMCell .
# By simply sess.run in each training step
sess.run(lstm_cell.get_vd_update_op())
# Or use control_dependencies
vd_update_ops = lstm_cell.get_vd_update_op()
with tf.control_dependencies(vd_update_ops):
tf.train.AdamOptimizer(learning_rate).minimize(loss)
También puede agregar get_vd_update_op() a GraphKeys.UPDATE_OPS al llamar WeightDropLSTMCell .
Observó que, si usa control_dependencies , tenga cuidado con el orden de ejecución.
El núcleo de deserción variacional no debe actualizarse antes del paso optimizador.
La idea principal de AWD-LSTM son los pesos de conexión de caída y las entradas concatinadas. 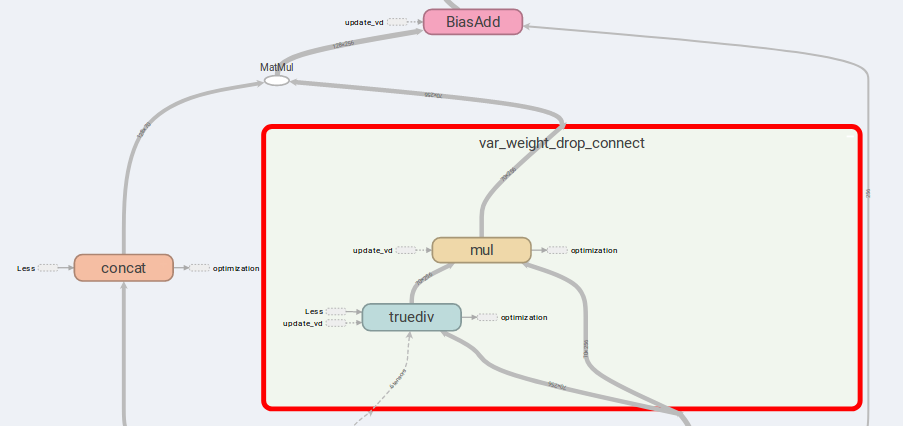
Si is_vd=True , se utilizarán variables para guardar el núcleo de abandono. 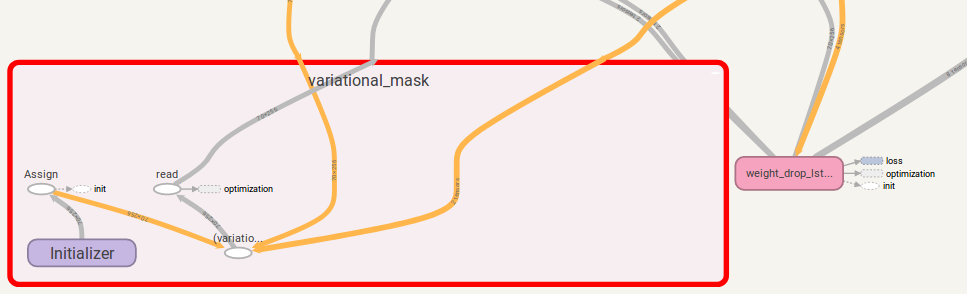
Tengo experimentos de conducta en una tarea recursiva de muchos a muchos esta implementación y lleva a cabo mejores resultados que LSTMCell simple.
lstm_cell = WeightDropLSTMCell(
num_units=CELL_NUM, weight_drop_kr=WEIGHT_DP_KR,
is_quant=True, is_train=True)
tf.contrib.quantize.create_training_graph(sess.graph, quant_delay=0)
tf.while que con una versión superior a 1.12.0 También proporcioné una implementación de tensorflow de deserción variacional, que es más flexible que DropoutWrapper en tensorflow.
El uso es similar al uso de WeightDropLSTMCell :
from variational_dropout import VariationalDropout
vd = VariationalDropout(input_shape=[5], keep_prob=0.5)
# Directly sess.run() to update
sess.run(vd.get_update_mask_op())
# Or use control_dependencies
with tf.control_dependencies(vd.get_update_mask_op()):
step, results_array = tf.while_loop(
cond=lambda step, _: step < 5,
body=main_loop,
loop_vars=(step, results_array))
"""
This is just a simple example.
Usually, control_dependencies will be placed where optimizer stepping.
"""
También puede agregar get_update_mask_op() a GraphKeys.UPDATE_OPS cuando llame VariationalDropout .
Una vez más, si usa control_dependencies , tenga cuidado con el orden de ejecución.
Si tiene alguna sugerencia, hágamelo saber. ¡Estaré bastante agradecido!
Trabajo en código de Jia-Yau Shiau [email protected].
Se recomienda y bifurcado el trabajo del código de cuantificación de Peter Huang [email protected]


