awd lstm tensorflow
1.0.0
AWD-LSTM de ("regularizando e otimizando os modelos de idiomas LSTM") para o tensorflow.
Também é fornecido quantização de treinamento para inferência inteira-aritmética ("quantização e treinamento de redes neurais para inferência inteira-aritmética eficiente") também é fornecida.
Este código é implementado e testado com o Tensorflow 1.11.0. e 1.13.0.
LayerRNNCell padrão. from weight_drop_lstm import WeightDropLSTMCell
lstm_cell = WeightDropLSTMCell(
num_units=CELL_NUM, weight_drop_kr=WEIGHT_DP_KR,
use_vd=True, input_size=INPUT_SIZE)
Os argumentos são definidos da seguinte maneira:
num_units: o número de células na camada LSTM. [INTS]
weight_drop_kr: o número de etapas que os pesos rápidos avançam. [int]
use_vd: se true, usando o abandono variacional na conexão com queda de peso, o abandono padrão de outra forma. [Bool]
input_size: seuse_vd=True, input_size (dimensão do último canal) deve ser fornecido. [int]
Os argumentos de palavra -chave restantes são exatamente os mesmos que tf.nn.LSTMCell .
Observou que, se o peso_drop_kr não for fornecido ou fornecido com 1.0, WeightDropLSTMCell será reduzido como LSTMCell .
# By simply sess.run in each training step
sess.run(lstm_cell.get_vd_update_op())
# Or use control_dependencies
vd_update_ops = lstm_cell.get_vd_update_op()
with tf.control_dependencies(vd_update_ops):
tf.train.AdamOptimizer(learning_rate).minimize(loss)
Você também pode adicionar get_vd_update_op() ao GraphKeys.UPDATE_OPS ao chamar WeightDropLSTMCell .
Observou que, se você usar control_dependencies , tenha cuidado com a ordem de execução.
O kernel de abandono variacional não deve ser atualizado antes da etapa do otimizador.
A principal idéia do AWD-LSTM são os pesos de conexão de queda e entradas concatizadas. 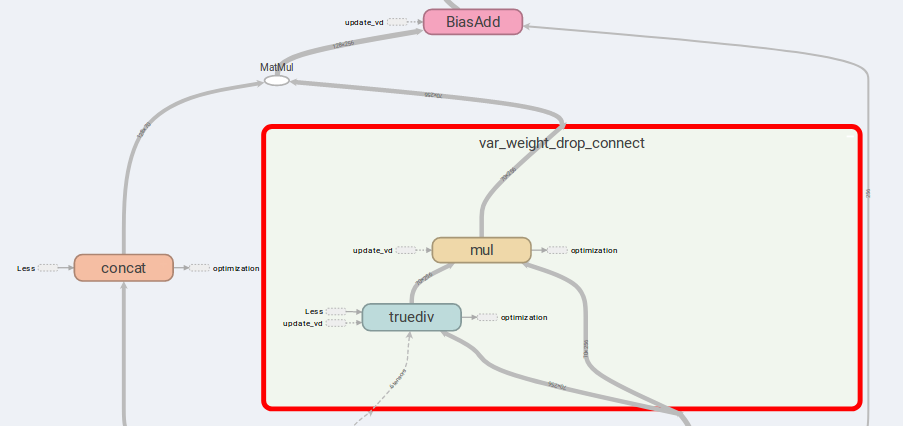
Se is_vd=True , as variáveis serão usadas para salvar o kernel de abandono. 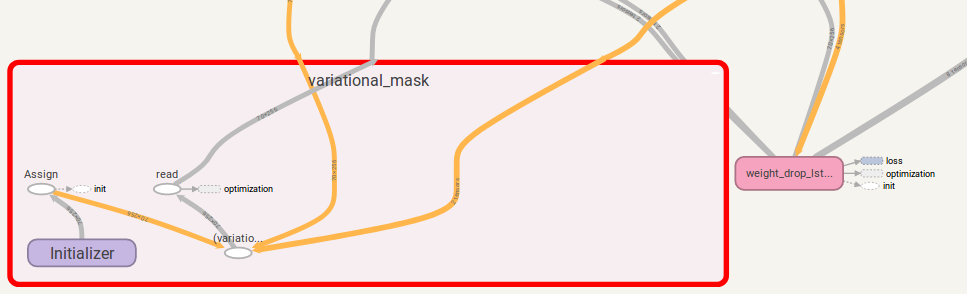
Eu conduzi experimentos em uma tarefa recursiva de muitos para muitos nesta implementação e realiza resultados melhores do que o simples LSTMCell .
lstm_cell = WeightDropLSTMCell(
num_units=CELL_NUM, weight_drop_kr=WEIGHT_DP_KR,
is_quant=True, is_train=True)
tf.contrib.quantize.create_training_graph(sess.graph, quant_delay=0)
tf.while com a versão superior a 1.12.0 Também forneci uma implementação do TensorFlow do abandono variacional, que é mais flexível que DropoutWrapper no TensorFlow.
O uso é semelhante ao uso de WeightDropLSTMCell :
from variational_dropout import VariationalDropout
vd = VariationalDropout(input_shape=[5], keep_prob=0.5)
# Directly sess.run() to update
sess.run(vd.get_update_mask_op())
# Or use control_dependencies
with tf.control_dependencies(vd.get_update_mask_op()):
step, results_array = tf.while_loop(
cond=lambda step, _: step < 5,
body=main_loop,
loop_vars=(step, results_array))
"""
This is just a simple example.
Usually, control_dependencies will be placed where optimizer stepping.
"""
Você também pode adicionar get_update_mask_op() ao GraphKeys.UPDATE_OPS ao chamar VariationalDropout .
Mais uma vez, se você usar control_dependencies , tenha cuidado com a ordem de execução.
Se você tiver alguma sugestão, por favor me avise. Ficarei muito grato!
Trabalho de código de jia-yau shiau [email protected].
O trabalho do código de quantização é recomendado e bifurcado de Peter Huang [email protected]


