Voice Privacy Challenge 2020
1.0.0
請訪問挑戰網站以獲取有關挑戰的更多信息。
git clone --recurse-submodules https://github.com/Voice-Privacy-Challenge/Voice-Privacy-Challenge-2020.git該食譜使用預先訓練的匿名模型。通過評估運行基線系統:
cd baseline./run.sh 。在run.sh中,要下載模型和數據,將請求用戶在挑戰註冊過程中提供的密碼。 有關基準和數據的更多詳細信息,請參閱《語音私人2020挑戰評估計劃》
有關基線和評估腳本中的最新更新,請訪問新聞和更新頁面
提交結果的截止日期已經過去。要訪問基線模型和開發/評估數據,請發送電子郵件至有機貨幣@lists.voiceprivacychallenge.org,並以“ VoicePrivacy-2020”為主題行。郵件主體應包括:(i)聯繫人的名稱; (ii)國家; (iii)狀態(學術/非學術)。
匿名系統的數據集由以下corpora*組成。
*只有這些語料庫的指定子集可用於培訓。
這是主要(默認)基線。
基線系統使用多種獨立模型:
1_asr_am ) - 在Librispeech-Train-Clean-100和LibrisPeech-Train-500上接受訓練2_xvect_extr ) - 在Voxceleb 1和2上訓練。3_ss_am ) - 在庫里特 - 培訓 - 列為-100上訓練。4_nsf ) - 在庫里特 - 培訓-Clean-100上訓練。 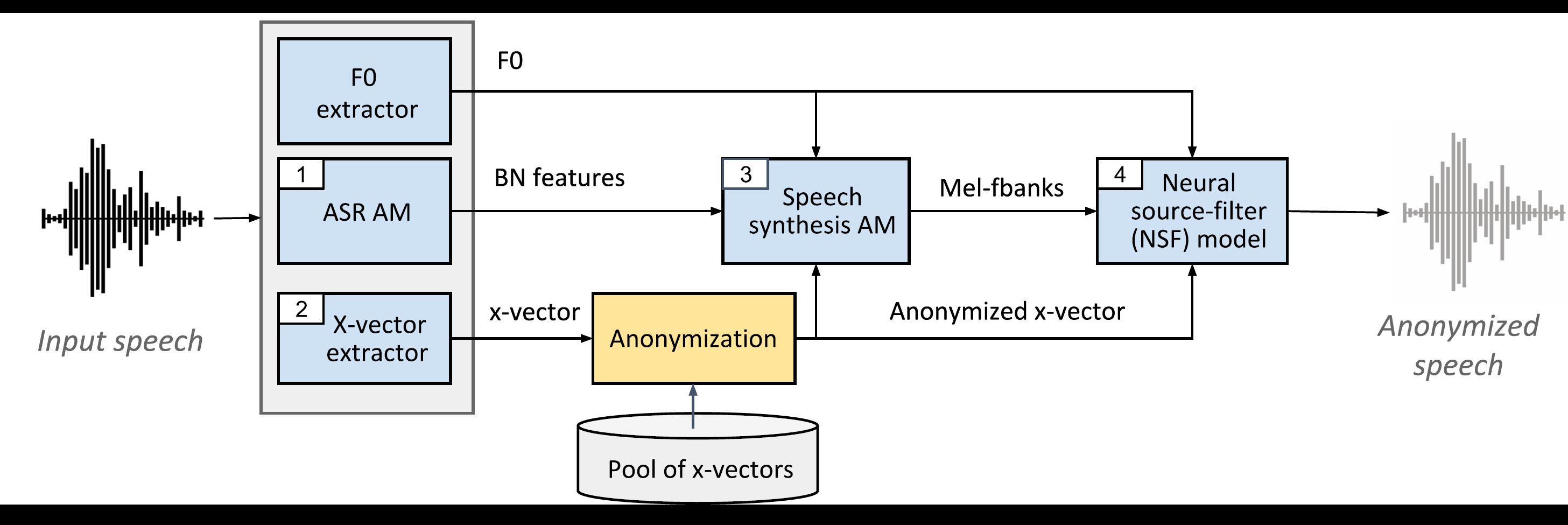
所有預驗證的模型均作為本基線的一部分提供(由./baseline/local/download_models.sh下載)
這是一個額外的基線。
運行: ./run.sh --mcadams true
它不需要任何培訓數據,並且基於使用McAdams係數的簡單信號處理技術。
帶有所有指標和所有提交數據集的結果文件將在:./baseline/exp/results- date time /results.txt中生成:
請看看
用於評估和開發數據集。
This work was supported in part by the French National Research Agency under projects HARPOCRATES (ANR-19-DATA-0008) and DEEP-PRIVACY (ANR-18- CE23-0018), by the European Union's Horizon 2020 Research and Innovation Program under Grant Agreement No. 825081 COMPRISE (https://www.compriseh2020.eu/), and jointly by the French National Research Agency and the Japan Science and Technology Agency under Project VoicePersonae。
版權(C)2020
該程序是免費的軟件:您可以根據自由軟件基金會發布的GNU通用公共許可證的條款對其進行重新分配和/或修改它,該版本是該許可證的版本3,或(按您的選項)任何以後的版本。
該程序的分佈是希望它將有用的,但沒有任何保修;即使沒有對特定目的的適銷性或適合性的隱含保證。有關更多詳細信息,請參見GNU通用公共許可證。
您應該已經收到了GNU通用公共許可證的副本以及此計劃。如果沒有,請參見https://www.gnu.org/licenses/。
@inproceedings{tomashenko2020introducing,
author={N. Tomashenko and Brij Mohan Lal Srivastava and Xin Wang and Emmanuel Vincent and Andreas Nautsch and Junichi Yamagishi and Nicholas Evans and Jose Patino and Jean-François Bonastre and Paul-Gauthier Noé and Massimiliano Todisco},
title={{Introducing the VoicePrivacy Initiative}},
year=2020,
booktitle={Proc. Interspeech 2020},
pages={1693--1697},
doi={10.21437/Interspeech.2020-1333},
url={http://dx.doi.org/10.21437/Interspeech.2020-1333}
}
@article{tomashenko2022voiceprivacy,
title={The VoicePrivacy 2020 Challenge: Results and findings},
author={Tomashenko, Natalia and Wang, Xin and Vincent, Emmanuel and Patino, Jose and Srivastava, Brij Mohan Lal and No{'e}, Paul-Gauthier and Nautsch, Andreas and Evans, Nicholas and Yamagishi, Junichi and O’Brien, Benjamin and others},
journal={Computer Speech & Language},
volume={74},
pages={101362},
year={2022},
publisher={Elsevier},
url={https://doi.org/10.1016/j.csl.2022.101362}
}
article{tomashenkovoiceprivacy,
title={The {VoicePrivacy} 2020 {Challenge} Evaluation Plan},
author={Tomashenko, Natalia and Srivastava, Brij Mohan Lal and Wang, Xin and Vincent, Emmanuel and Nautsch, Andreas and Yamagishi, Junichi and Evans, Nicholas and Patino, Jose and Bonastre, Jean-Fran{c{c}}ois and No{'e}, Paul-Gauthier and Todisco, Massimiliano},
url={https://www.voiceprivacychallenge.org/docs/VoicePrivacy_2020_Eval_Plan_v1_3.pdf},
year={2020}
}
對於評估後分析,新穎的匿名指標已集成到基線評估:


