Voice Privacy Challenge 2020
1.0.0
Veuillez visiter le site Web Challenge pour plus d'informations sur le défi.
git clone --recurse-submodules https://github.com/Voice-Privacy-Challenge/Voice-Privacy-Challenge-2020.gitLa recette utilise les modèles d'anonymisation pré-formés. Pour exécuter le système de base avec évaluation:
cd baseline./run.sh . Dans run.sh, pour télécharger des modèles et des données, l'utilisateur sera demandé le mot de passe qui est fourni lors de l'enregistrement du défi. Pour plus de détails sur la ligne de base et les données, veuillez consulter le plan d'évaluation du défi VoicePrivacy 2020
Pour les dernières mises à jour dans les scripts de référence et d'évaluation, veuillez visiter la page des nouvelles et des mises à jour
La date limite pour soumettre des résultats s'est écoulée. Pour accéder aux modèles de référence et aux données de développement / évaluation, veuillez envoyer un e-mail à [email protected] avec «VoicePrivacy-2020» comme ligne d'objet. Le corps du courrier doit inclure: (i) le nom de la personne de contact; (ii) pays; (iii) Statut (académique / non académique).
L'ensemble de données pour le système d'anonymisation TRING se compose de sous-ensembles des corpus suivants *:
* Seuls les sous-ensembles spécifiés de ces corpus peuvent être utilisés pour la formation.
Il s'agit de la ligne de base principale (par défaut).
Le système de base utilise plusieurs modèles indépendants:
1_asr_am ) - Formé sur LibRispeeCH-Train-Clean-100 et LibrisPeElep-Train-other-5002_xvect_extr ) - Formé sur Voxceleb 1 & 2.3_ss_am ) - formé sur Libritts-Tain-Clean-100.4_nsf ) - formé sur Libritts-Train-Clean-100. 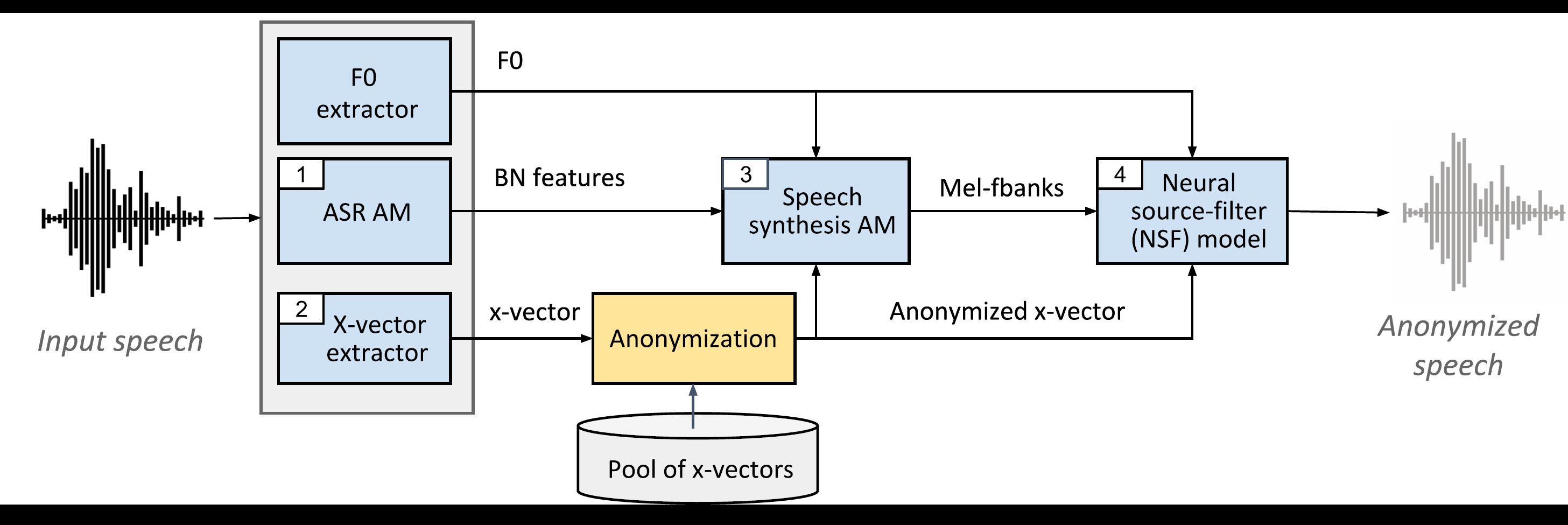
Tous les modèles pré-entraînés sont fournis dans cette ligne de base (téléchargé par ./baseline/local/download_models.sh)
Il s'agit d'une base de référence supplémentaire.
Courir: ./run.sh --mcadams true
Il ne nécessite aucune donnée de formation et est basé sur des techniques de traitement de signal simples en utilisant le coefficient McAdams.
Le fichier de résultat avec toutes les métriques et tous les ensembles de données à soumission sera généré dans: ./baseline/exp/results- date - time /results.txt
Veuillez consulter
Pour les ensembles de données d'évaluation et de développement.
Contact: [email protected]
This work was supported in part by the French National Research Agency under projects HARPOCRATES (ANR-19-DATA-0008) and DEEP-PRIVACY (ANR-18- CE23-0018), by the European Union's Horizon 2020 Research and Innovation Program under Grant Agreement No. 825081 COMPRISE (https://www.compriseh2020.eu/), and jointly by the French National Research Agency and the Japan Science and Technology Agency under project VoicePersonae.
Copyright (C) 2020
Ce programme est un logiciel gratuit: vous pouvez le redistribuer et / ou le modifier en vertu des termes de la licence publique générale GNU publiée par la Free Software Foundation, soit la version 3 de la licence, ou (à votre option) toute version ultérieure.
Ce programme est distribué dans l'espoir qu'il sera utile, mais sans aucune garantie; Sans même la garantie implicite de qualité marchande ou d'adéquation à un usage particulier. Voir la licence publique générale GNU pour plus de détails.
Vous devriez avoir reçu une copie de la licence publique générale GNU avec ce programme. Sinon, voir https://www.gnu.org/licenses/.
@inproceedings{tomashenko2020introducing,
author={N. Tomashenko and Brij Mohan Lal Srivastava and Xin Wang and Emmanuel Vincent and Andreas Nautsch and Junichi Yamagishi and Nicholas Evans and Jose Patino and Jean-François Bonastre and Paul-Gauthier Noé and Massimiliano Todisco},
title={{Introducing the VoicePrivacy Initiative}},
year=2020,
booktitle={Proc. Interspeech 2020},
pages={1693--1697},
doi={10.21437/Interspeech.2020-1333},
url={http://dx.doi.org/10.21437/Interspeech.2020-1333}
}
@article{tomashenko2022voiceprivacy,
title={The VoicePrivacy 2020 Challenge: Results and findings},
author={Tomashenko, Natalia and Wang, Xin and Vincent, Emmanuel and Patino, Jose and Srivastava, Brij Mohan Lal and No{'e}, Paul-Gauthier and Nautsch, Andreas and Evans, Nicholas and Yamagishi, Junichi and O’Brien, Benjamin and others},
journal={Computer Speech & Language},
volume={74},
pages={101362},
year={2022},
publisher={Elsevier},
url={https://doi.org/10.1016/j.csl.2022.101362}
}
article{tomashenkovoiceprivacy,
title={The {VoicePrivacy} 2020 {Challenge} Evaluation Plan},
author={Tomashenko, Natalia and Srivastava, Brij Mohan Lal and Wang, Xin and Vincent, Emmanuel and Nautsch, Andreas and Yamagishi, Junichi and Evans, Nicholas and Patino, Jose and Bonastre, Jean-Fran{c{c}}ois and No{'e}, Paul-Gauthier and Todisco, Massimiliano},
url={https://www.voiceprivacychallenge.org/docs/VoicePrivacy_2020_Eval_Plan_v1_3.pdf},
year={2020}
}
Pour l'analyse post-évaluation, de nouvelles mesures d'anonymisation ont été intégrées à l'évaluation de base:


