Voice Privacy Challenge 2020
1.0.0
请访问挑战网站以获取有关挑战的更多信息。
git clone --recurse-submodules https://github.com/Voice-Privacy-Challenge/Voice-Privacy-Challenge-2020.git该食谱使用预先训练的匿名模型。通过评估运行基线系统:
cd baseline./run.sh 。在run.sh中,要下载模型和数据,将请求用户在挑战注册过程中提供的密码。 有关基准和数据的更多详细信息,请参阅《语音私人2020挑战评估计划》
有关基线和评估脚本中的最新更新,请访问新闻和更新页面
提交结果的截止日期已经过去。要访问基线模型和开发/评估数据,请发送电子邮件至有机货币@lists.voiceprivacychallenge.org,并以“ VoicePrivacy-2020”为主题行。邮件主体应包括:(i)联系人的名称; (ii)国家; (iii)状态(学术/非学术)。
匿名系统的数据集由以下corpora*组成。
*只有这些语料库的指定子集可用于培训。
这是主要(默认)基线。
基线系统使用多种独立模型:
1_asr_am ) - 在Librispeech-Train-Clean-100和LibrisPeech-Train-500上接受训练2_xvect_extr ) - 在Voxceleb 1和2上训练。3_ss_am ) - 在库里特 - 培训 - 列为-100上训练。4_nsf ) - 在库里特 - 培训-Clean-100上训练。 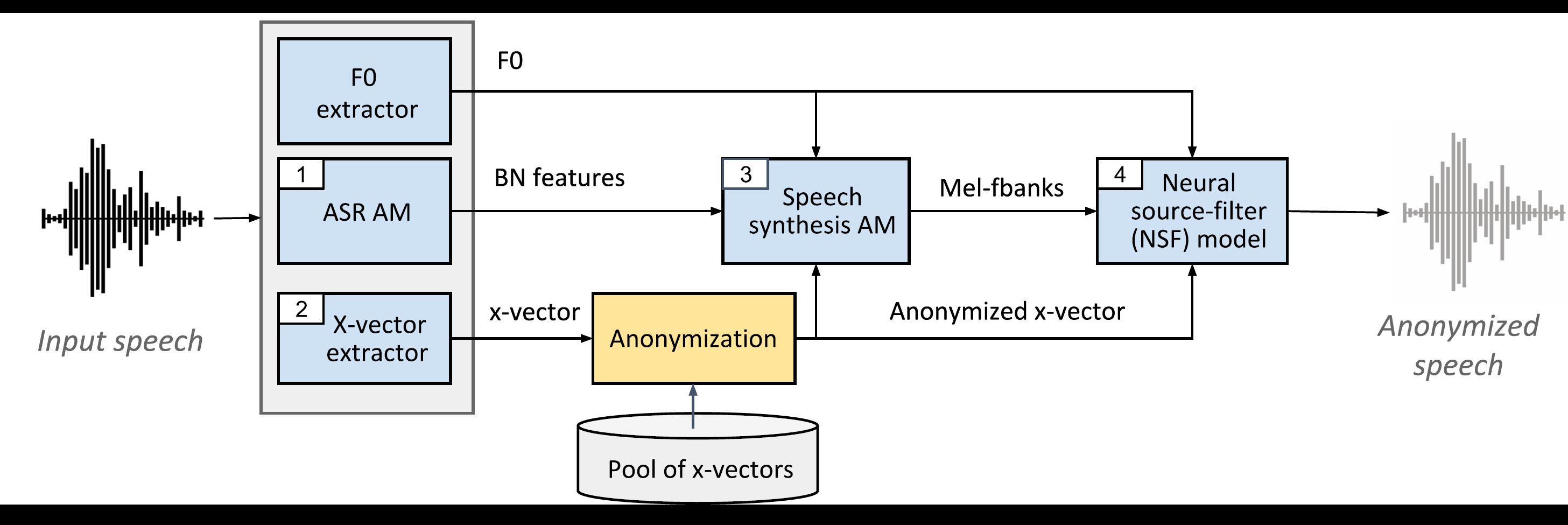
所有预验证的模型均作为本基线的一部分提供(由./baseline/local/download_models.sh下载)
这是一个额外的基线。
运行: ./run.sh --mcadams true
它不需要任何培训数据,并且基于使用McAdams系数的简单信号处理技术。
带有所有指标和所有提交数据集的结果文件将在:./baseline/exp/results- date time /results.txt中生成:
请看看
用于评估和开发数据集。
This work was supported in part by the French National Research Agency under projects HARPOCRATES (ANR-19-DATA-0008) and DEEP-PRIVACY (ANR-18- CE23-0018), by the European Union's Horizon 2020 Research and Innovation Program under Grant Agreement No. 825081 COMPRISE (https://www.compriseh2020.eu/), and jointly by the French National Research Agency and the Japan Science and Technology Agency under Project VoicePersonae。
版权(C)2020
该程序是免费的软件:您可以根据自由软件基金会发布的GNU通用公共许可证的条款对其进行重新分配和/或修改它,该版本是该许可证的版本3,或(按您的选项)任何以后的版本。
该程序的分布是希望它将有用的,但没有任何保修;即使没有对特定目的的适销性或适合性的隐含保证。有关更多详细信息,请参见GNU通用公共许可证。
您应该已经收到了GNU通用公共许可证的副本以及此计划。如果没有,请参见https://www.gnu.org/licenses/。
@inproceedings{tomashenko2020introducing,
author={N. Tomashenko and Brij Mohan Lal Srivastava and Xin Wang and Emmanuel Vincent and Andreas Nautsch and Junichi Yamagishi and Nicholas Evans and Jose Patino and Jean-François Bonastre and Paul-Gauthier Noé and Massimiliano Todisco},
title={{Introducing the VoicePrivacy Initiative}},
year=2020,
booktitle={Proc. Interspeech 2020},
pages={1693--1697},
doi={10.21437/Interspeech.2020-1333},
url={http://dx.doi.org/10.21437/Interspeech.2020-1333}
}
@article{tomashenko2022voiceprivacy,
title={The VoicePrivacy 2020 Challenge: Results and findings},
author={Tomashenko, Natalia and Wang, Xin and Vincent, Emmanuel and Patino, Jose and Srivastava, Brij Mohan Lal and No{'e}, Paul-Gauthier and Nautsch, Andreas and Evans, Nicholas and Yamagishi, Junichi and O’Brien, Benjamin and others},
journal={Computer Speech & Language},
volume={74},
pages={101362},
year={2022},
publisher={Elsevier},
url={https://doi.org/10.1016/j.csl.2022.101362}
}
article{tomashenkovoiceprivacy,
title={The {VoicePrivacy} 2020 {Challenge} Evaluation Plan},
author={Tomashenko, Natalia and Srivastava, Brij Mohan Lal and Wang, Xin and Vincent, Emmanuel and Nautsch, Andreas and Yamagishi, Junichi and Evans, Nicholas and Patino, Jose and Bonastre, Jean-Fran{c{c}}ois and No{'e}, Paul-Gauthier and Todisco, Massimiliano},
url={https://www.voiceprivacychallenge.org/docs/VoicePrivacy_2020_Eval_Plan_v1_3.pdf},
year={2020}
}
对于评估后分析,新颖的匿名指标已集成到基线评估:


