pytorch openai transformer lm
1.0.0
這是Alec Radford,Karthik Narasimhan,Tim Salimans和Ilya Sutskever提供的Openai論文“通過生成預培訓來提高語言理解的TensorFlow代碼的Pytorch實現”。
該實現包括一個腳本,以加載Pytorch模型中的權重,並由作者通過TensorFlow實現進行訓練。
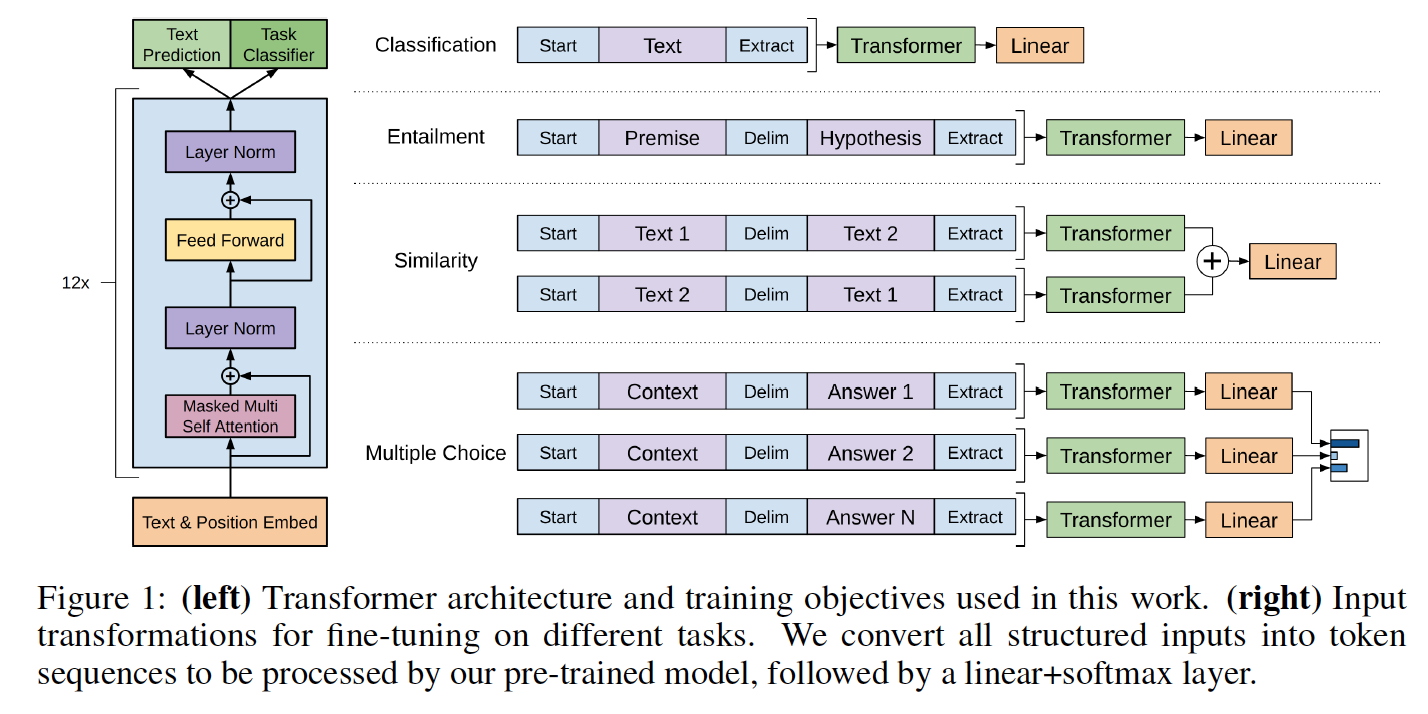
模型類和加載腳本位於model_pytorch.py中。
Pytorch模型中模塊的名稱遵循TensorFlow實現中變量的名稱。此實施試圖盡可能遵循原始代碼,以最大程度地減少差異。
因此,該實現還包括Openai論文中使用的修改後的ADAM優化算法:
要通過導入model_pytorch.py來使用模型IT自我,您只需要:
要在Train.py中運行分類器培訓腳本。您還需要:
您可以通過克隆Alec Radford的存儲庫來下載OpenAI預訓練版本的權重,並將包含預訓練權重的model文件夾放在本倉庫中。
該模型可以用作具有OpenAI預先訓練的權重的變壓器語言模型,如下:
from model_pytorch import TransformerModel , load_openai_pretrained_model , DEFAULT_CONFIG
args = DEFAULT_CONFIG
model = TransformerModel ( args )
load_openai_pretrained_model ( model )該模型生成變壓器的隱藏狀態。您可以在model_pytorch.py中使用LMHead類來添加與編碼器的權重並獲得完整語言模型的解碼器。您還可以在model_pytorch.py中使用ClfHead類在變壓器之上添加分類器,並如OpenAI出版物中所述獲取分類器。 (請參閱__________py的__main__函數中的兩個示例)
要使用變壓器的位置編碼器,應使用utils.py的encode_dataset()函數編碼數據集。請參閱train.py中__main__功能的開頭,以查看如何正確定義詞彙並編碼數據集。
該模型也可以按照Openai論文中詳細介紹的分類器集成。訓練代碼在train.py中包含了關於rocstories的微調任務的一個示例。
可以從關聯的網站下載Rocstories數據集。
與TensorFlow代碼一樣,該代碼實現了Rocstories在論文中報告的cloze測試結果,該結果可以通過運行來複製:
python -m spacy download en
python train.py --dataset rocstories --desc rocstories --submit --analysis --data_dir [path to data here]在Rocstories上為3個時期的Pytorch模型進行填充需要10分鐘才能在單個NVIDIA K-80上運行。
該Pytorch版本的單次運行測試精度為85.84%,而作者報告的張力量代碼為85.8%,而論文報告的最佳單次運行精度為86.5%。
作者實現使用8 GPU,因此可以容納64個樣本的批次,而本實現為單個GPU,因此出於內存原因,在K80上僅限於20個實例。在我們的測試中,將批處理大小從8個樣品增加到20個樣品將測試準確性提高了2.5分。通過使用多GPU設置(尚未嘗試)可以獲得更好的精度。
Rocstories數據集上的先前的SOTA為77.6%(Chaturvedi等人的“隱藏連貫模型”出版在“故事理解中”,用於預測下一步發生的事情“ EMNLP 2017,這也是一張非常好的論文!)


