pytorch openai transformer lm
1.0.0
これは、Alec Radford、Karthik Narasimhan、Tim Salimans、Ilya SutskeverによるOpenaiの論文「生成前トレーニングによる言語理解の向上」で提供されたTensorflowコードのPytorch実装です。
この実装は、Tensorflow実装を使用して著者によって事前に訓練された重みをPytorchモデルにロードするスクリプトで構成されています。
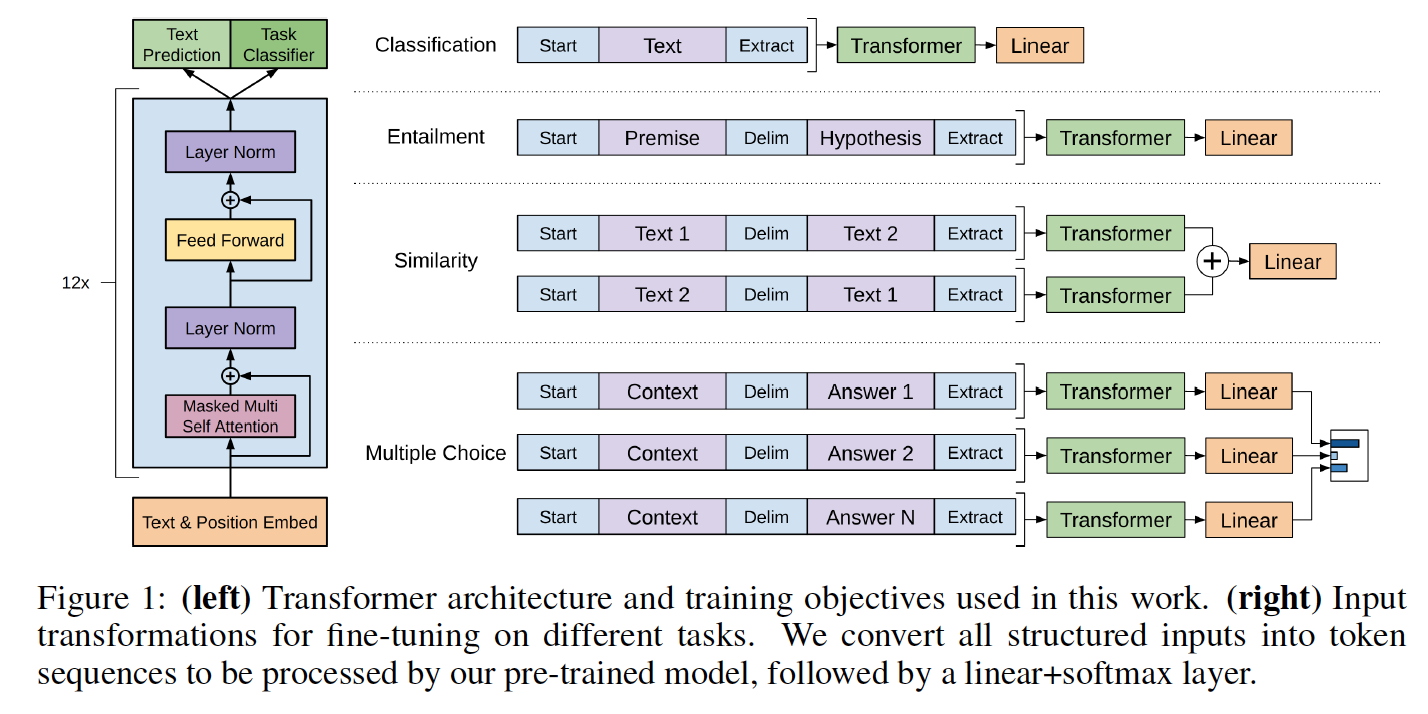
モデルクラスとロードスクリプトは、model_pytorch.pyにあります。
Pytorchモデルのモジュールの名前は、Tensorflow実装の変数の名前に従います。この実装は、矛盾を最小限に抑えるために、可能な限り密接に元のコードに従うことを試みます。
したがって、この実装は、Openaiの論文で使用されている修正されたAdam Optimization Algorithmも構成します。
Model_pytorch.pyをインポートしてモデルIT-Selfを使用するには、次のことが必要です。
Train.pyで分類子トレーニングスクリプトを実行するには、さらに必要になります。
Alec Radfordのリポジトリをクローニングし、現在のリポジトリに事前に訓練された重みを含むmodelフォルダーを配置することにより、Openaiの事前訓練バージョンの重量をダウンロードできます。
このモデルは、次のようにOpenAIの事前に訓練された重みを使用して、トランス語モデルとして使用できます。
from model_pytorch import TransformerModel , load_openai_pretrained_model , DEFAULT_CONFIG
args = DEFAULT_CONFIG
model = TransformerModel ( args )
load_openai_pretrained_model ( model )このモデルは、変圧器の隠された状態を生成します。 Model_pytorch.pyのLMHeadクラスを使用して、エンコーダの重みで結ばれたデコーダーを追加して、フル言語モデルを取得できます。 Model_pytorch.pyのClfHeadクラスを使用して、変圧器の上に分類子を追加し、Openaiの出版物で説明されているように分類器を取得することもできます。 (train.pyの__main__関数の両方の例を参照)
トランスの位置エンコーダーを使用するには、utils.pyのencode_dataset()関数を使用してデータセットをエンコードする必要があります。 Train.pyの__main__関数の先頭を参照して、語彙を適切に定義し、データセットをエンコードする方法を確認してください。
このモデルは、Openaiの論文で詳述されているように、分類器に統合することもできます。 Rocstories Clozeタスクの微調整の例は、train.pyのトレーニングコードに含まれています
Rocstoriesデータセットは、関連するWebサイトからダウンロードできます。
Tensorflowコードと同様に、このコードは、実行することで再現できる論文で報告されたRocstories Crozeテスト結果を実装します。
python -m spacy download en
python train.py --dataset rocstories --desc rocstories --submit --analysis --data_dir [path to data here]Rocstoriesの3つのエポックのPytorchモデルを微調整すると、単一のNvidia K-80で実行されるのに10分かかります。
このPytorchバージョンのシングルランテストの精度は85.84%ですが、著者はTensorflowコード85.8%の中央値を報告し、ペーパーは86.5%の最高のシングルラン精度を報告しています。
著者の実装では8つのGPUを使用するため、現在の実装は単一のGPUであり、その結果、メモリの理由でK80で20インスタンスに制限されている間、64のサンプルのバッチを付与できます。テストでは、バッチサイズを8から20のサンプルに増やすと、テストの精度が2.5ポイント増加しました。マルチGPU設定を使用して、より良い精度を取得できます(まだ試されていません)。
Rocstories Datasetの以前のSotaは77.6%です(Chaturvedi et al。の「Hidden Coherence Model」は、「次に何が起こるかを予測するためのストーリー理解」に掲載されています。


