pytorch openai transformer lm
1.0.0
Il s'agit d'une implémentation Pytorch du code TensorFlow fourni avec l'article d'OpenAI "Améliorer la compréhension du langage par la pré-formation générative" par Alec Radford, Karthik Narasimhan, Tim Salimans et Ilya Sutskever.
Cette implémentation comprend un script à charger dans le modèle Pytorch Les poids pré-formés par les auteurs avec l'implémentation TensorFlow.
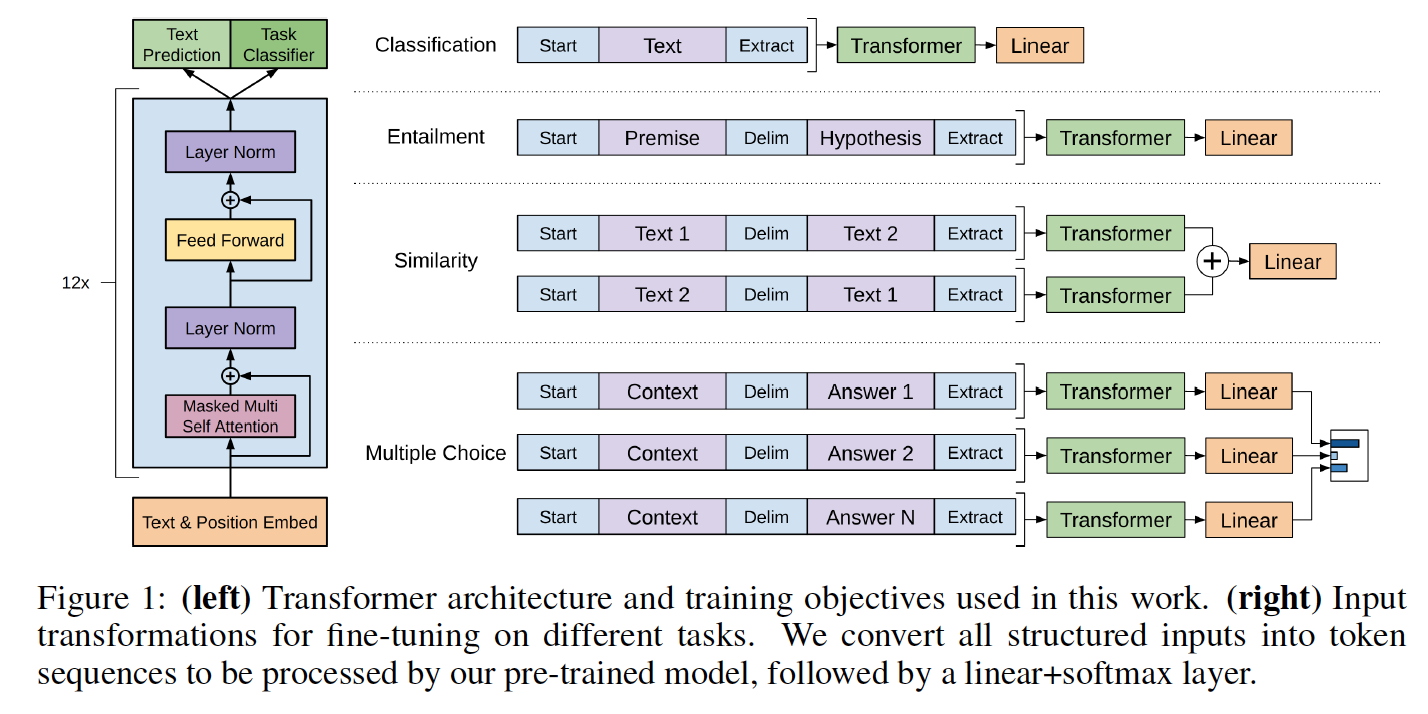
Les classes de modèles et le script de chargement sont situés dans modèle_pytorch.py.
Les noms des modules du modèle Pytorch suivent les noms de la variable dans l'implémentation TensorFlow. Cette implémentation essaie de suivre le code d'origine aussi étroitement que possible pour minimiser les écarts.
Cette implémentation comprend également un algorithme d'optimisation ADAM modifié comme utilisé dans le papier d'Openai avec:
Pour utiliser le modèle It-self en important Model_pytorch.py, vous avez juste besoin:
Pour exécuter le script d'entraînement du classificateur dans Train.py, vous aurez besoin en plus:
Vous pouvez télécharger les poids de la version pré-formée OpenAI en cloning Alec Radford et en plaçant le dossier model contenant les poids pré-formés dans le répo actuel.
Le modèle peut être utilisé comme modèle de langue transformateur avec les poids pré-formés d'OpenAI comme suit:
from model_pytorch import TransformerModel , load_openai_pretrained_model , DEFAULT_CONFIG
args = DEFAULT_CONFIG
model = TransformerModel ( args )
load_openai_pretrained_model ( model ) Ce modèle génère des états cachés du transformateur. Vous pouvez utiliser la classe LMHead dans Model_pytorch.py pour ajouter un décodeur lié aux poids de l'encodeur et obtenir un modèle de langue complet. Vous pouvez également utiliser la classe ClfHead dans modèle_pytorch.py pour ajouter un classificateur au-dessus du transformateur et obtenir un classificateur comme décrit dans la publication d'Openai. (Voir un exemple des deux dans la fonction __main__ de Train.py)
Pour utiliser le codeur de position du transformateur, vous devez coder votre ensemble de données à l'aide de la fonction encode_dataset() de utils.py. Veuillez vous référer au début de la fonction __main__ dans Train.py pour voir comment définir correctement le vocabulaire et coder votre ensemble de données.
Ce modèle peut également être intégré dans un classificateur comme détaillé dans le papier d'Openai. Un exemple de réglage fin sur la tâche Rocstories Cloze est inclus avec le code de formation dans Train.py
L'ensemble de données Rocstories peut être téléchargé à partir du site Web associé.
Comme pour le code TensorFlow, ce code implémente le résultat du test de cloche Rocstories signalé dans l'article qui peut être reproduit par l'exécution:
python -m spacy download en
python train.py --dataset rocstories --desc rocstories --submit --analysis --data_dir [path to data here]Finetuning Le modèle Pytorch pour 3 époques sur Rocstories met 10 minutes à fonctionner sur un seul NVIDIA K-80.
La précision de test à un seul exécution de cette version Pytorch est de 85,84%, tandis que les auteurs rapportent une précision médiane avec le code TensorFlow de 85,8% et l'article rapporte une meilleure précision à un seul exécution de 86,5%.
Les implémentations des auteurs utilisent 8 GPU et peuvent ainsi accueillir un lot de 64 échantillons tandis que la présente implémentation est un GPU unique et est en conséquence limitée à 20 instances sur un K80 pour des raisons de mémoire. Dans notre test, l'augmentation de la taille du lot de 8 à 20 échantillons a augmenté la précision du test de 2,5 points. Une meilleure précision peut être obtenue en utilisant un paramètre multi-GPU (non encore essayé).
L'ensemble de données SOTA sur le Rocstories précédent est de 77,6% ("modèle de cohérence caché" de Chaturvedi et al. Publié dans "Story Comprehension pour prédire ce qui se passe ensuite" EMNLP 2017, qui est également un très beau article!)


