pytorch openai transformer lm
1.0.0
Esta é uma implementação de Pytorch do código Tensorflow fornecido com o artigo do OpenAI "Melhorando o entendimento da linguagem por pré-treinamento generativo", de Alec Radford, Karthik Narasimhan, Tim Salimans e Ilya Sutskever.
Essa implementação compreende um script para carregar no modelo Pytorch, os pesos pré-treinados pelos autores com a implementação do TensorFlow.
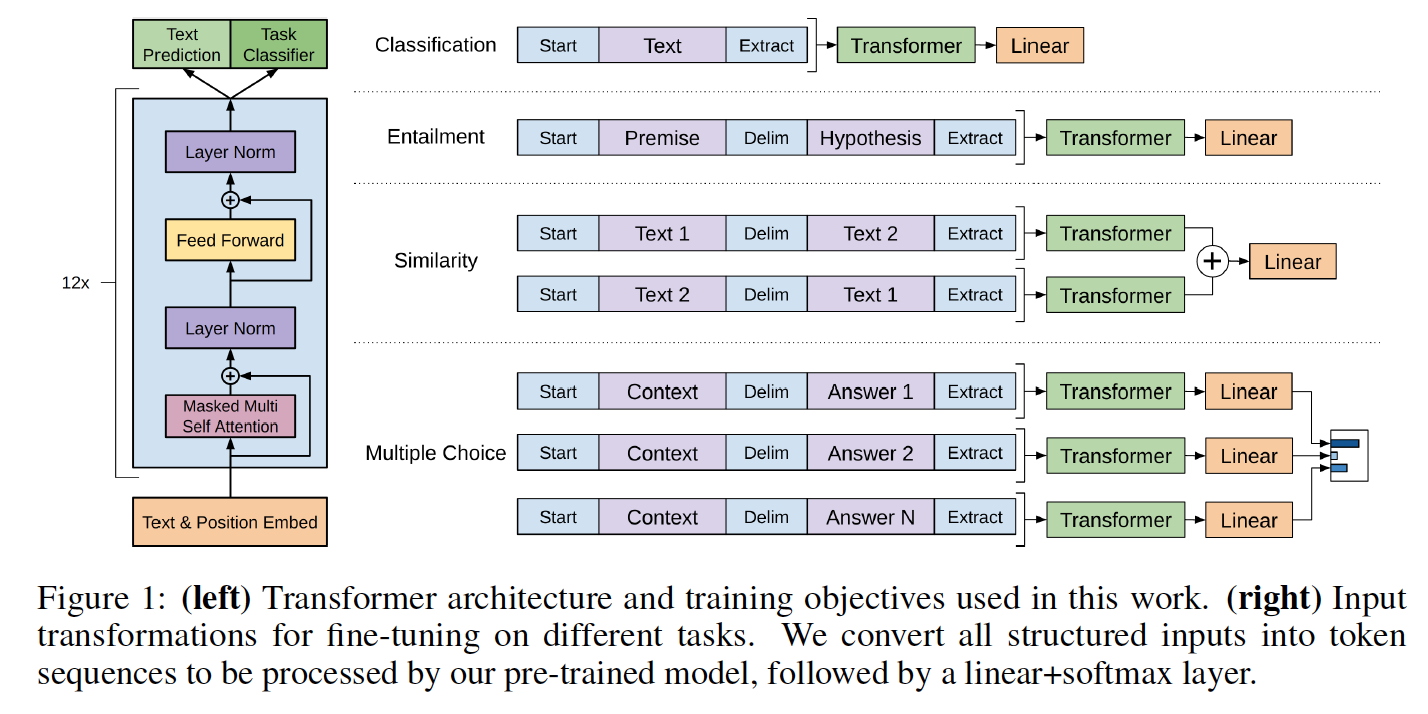
As classes de modelo e o script de carregamento estão localizados em model_pytorch.py.
Os nomes dos módulos no modelo Pytorch seguem os nomes da variável na implementação do tensorflow. Essa implementação tenta seguir o código original o mais próximo possível para minimizar as discrepâncias.
Essa implementação, portanto, também compreende um algoritmo de otimização de Adam modificado, conforme usado no artigo do OpenAI com:
Para usar o modelo de IT-Self Importando Model_Pytorch.py, você só precisa:
Para executar o script de treinamento do classificador em Train.py, você precisará além:
Você pode baixar os pesos da versão pré-treinada do OpenAI, clonando o repositório de Alec Radford e colocando a pasta model que contém os pesos pré-treinados no presente repositório.
O modelo pode ser usado como um modelo de linguagem de transformador com os pesos pré-treinados da OpenAI da seguinte forma:
from model_pytorch import TransformerModel , load_openai_pretrained_model , DEFAULT_CONFIG
args = DEFAULT_CONFIG
model = TransformerModel ( args )
load_openai_pretrained_model ( model ) Este modelo gera estados ocultos do transformador. Você pode usar a classe LMHead em model_pytorch.py para adicionar um decodificador amarrado com os pesos do codificador e obter um modelo de idioma completo. Você também pode usar a classe ClfHead em model_pytorch.py para adicionar um classificador na parte superior do transformador e obter um classificador conforme descrito na publicação do OpenAI. (Veja um exemplo de ambos na função __main__ do trem.py)
Para usar o codificador posicional do transformador, você deve codificar seu conjunto de dados usando a função encode_dataset() de utils.py. Consulte o início da função __main__ no Train.py para ver como definir corretamente o vocabulário e codificar seu conjunto de dados.
Esse modelo também pode ser integrado em um classificador, conforme detalhado no artigo do OpenAI. Um exemplo de ajuste fino na tarefa RocStories Cloze está incluído no código de treinamento em trem.py
O conjunto de dados RocStories pode ser baixado no site associado.
Assim como no código do tensorflow, este código implementa o resultado do teste de claze do RocStories relatado no artigo que pode ser reproduzido pela execução:
python -m spacy download en
python train.py --dataset rocstories --desc rocstories --submit --analysis --data_dir [path to data here]O Finetuning the Pytorch Model para 3 épocas no RocSories leva 10 minutos para ser executado em um único NVIDIA K-80.
A precisão do teste de execução única desta versão Pytorch é de 85,84%, enquanto os autores relatam uma precisão mediana com o código do tensorflow de 85,8%e o artigo relata uma melhor precisão de execução de 86,5%.
As implementações dos autores usam 8 GPU e, portanto, podem acomodar um lote de 64 amostras, enquanto a atual implementação é uma GPU única e, consequentemente, é limitado a 20 instâncias em um K80 por razões de memória. Em nosso teste, aumentar o tamanho do lote de 8 para 20 amostras aumentou a precisão do teste em 2,5 pontos. Uma melhor precisão pode ser obtida usando uma configuração multi-GPU (ainda não tentada).
O conjunto anterior do conjunto de dados do RocStories é de 77,6% ("Modelo de coerência oculta" de Chaturvedi et al. Publicado em "Compreensão da história para prever o que acontece a seguir" EMNLP 2017, que também é um artigo muito bom!)


