l2p
1.0.0
該代碼庫包含兩種連續學習方法的實現:
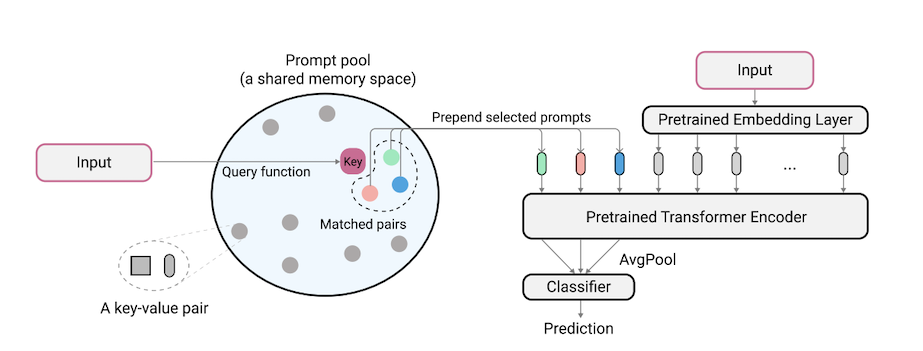
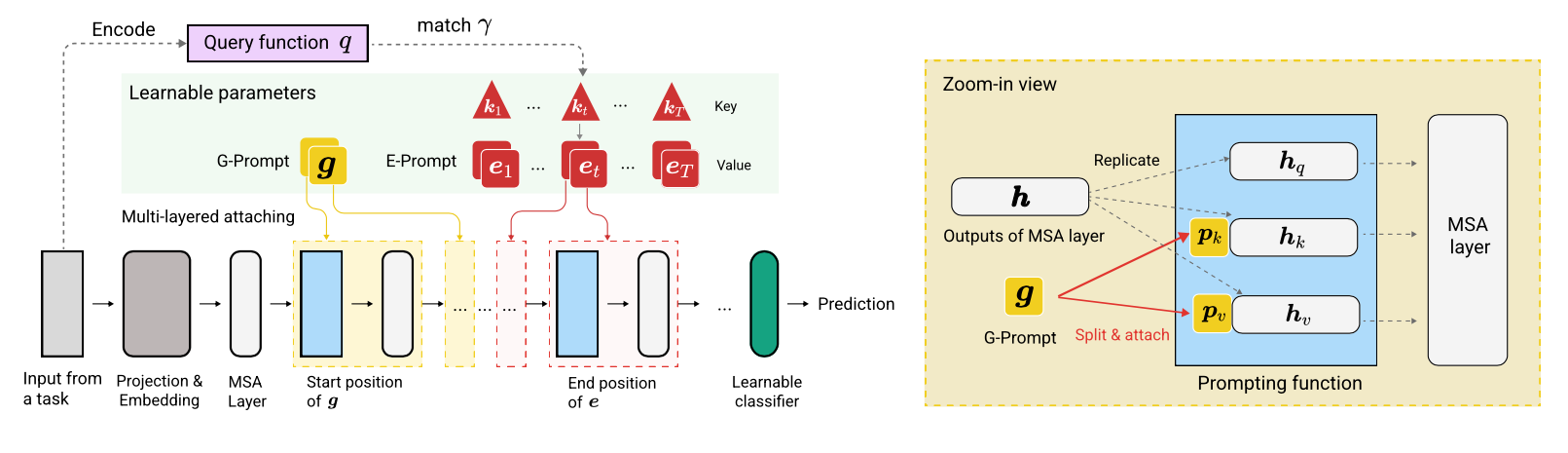
L2P是一種新穎的持續學習技術,它可以動態地促使預訓練的模型在不同的任務轉換下依次學習任務。與基於主流彩排或基於架構的方法不同,L2P既不需要排練緩衝區也不需要測試時間任務標識。 L2P可以推廣到各種持續的學習設置,包括最具挑戰性,最現實的任務不合時宜的環境。 L2P始終優於先前的最新方法。令人驚訝的是,即使沒有排練緩衝液,L2P也可以針對基於排練的方法實現競爭結果。
代碼由Zifeng Wang撰寫。致謝https://github.com/google-research/nested-transformer。
這不是官方支持的Google產品。
通過將200個類別分為10個任務,每個任務20個任務,請參見libml/input_pipeline.py,請參閱Imagenet-R基於Imagenet-R的拆分Imagenet-R基準。我們認為,由於以下原因,分裂的Imagenet-R對持續學習社區至關重要:
Jaeho Lee在L2P-Pytorch和DualPrompt-Pytorch中已將代碼庫在Pytorch中重新完成。
pip install -r requirements.txt
之後,您可能需要根據CUDA驅動程序版本調整JAX版本,以便JAX正確識別您的GPU(有關更多詳細信息,請參見此問題)。
注意:使用最新的JAX版本,該代碼庫已在TPU環境中進行了深入測試。我們目前正在努力進一步驗證GPU環境。
在運行5個數據集和Core50的實驗之前,應進行其他數據集準備步驟如下:
"PATH_TO_CORE50"和"PATH_TO_NOT_MNIST"中的libml/input_pipeline.py在步驟2中的目標路徑本文中使用的VIT-B/16模型可以在此處下載。注意:我們的代碼庫實際上支持各種尺寸的VIT。如果您想嘗試VIT的變化,請隨時更改配置文件中的config.model_name ,遵循模型/vit.py中定義的有效選項。
我們提供配置文件,以在配置中的多個基準測試上訓練和評估L2P和DualPrompt。
在基準數據集上運行L2P:
python main.py --my_config configs/$L2P_CONFIG --workdir=./l2p --my_config.init_checkpoint=<ViT-saved-path/ViT-B_16.npz>
其中$L2P_CONFIG可以是以下內容之一: [cifar100_l2p.py, five_datasets_l2p.py, core50_l2p.py, cifar100_gaussian_l2p.py] 。
注意:我們使用8個V100 GPU或4個TPU運行實驗,並在配置文件中指定每個設備批次大小為16。這表明我們使用的總批量大小為128。
要在基準數據集上運行雙啟示:
python main.py --my_config configs/$DUALPROMPT_CONFIG --workdir=./dualprompt --my_config.init_checkpoint=<ViT-saved-path/ViT-B_16.npz>
其中$DUALPROMPT_CONFIG可以是以下內容之一: [imr_dualprompt.py, cifar100_dualprompt.py] 。
我們使用張板可視化結果。例如,如果指定運行L2P的工作目錄是workdir=./cifar100_l2p ,則檢查結果的命令如下:
tensorboard --logdir ./cifar100_l2p
以下是跟踪其相應含義的重要指標:
| 公制 | 描述 |
|---|---|
| 準確_n | 第n個任務的準確性 |
| 忘記 | 平均忘記直到當前任務 |
| AVG_ACC | 平均評估準確性直到當前任務 |
@inproceedings{wang2022learning,
title={Learning to prompt for continual learning},
author={Wang, Zifeng and Zhang, Zizhao and Lee, Chen-Yu and Zhang, Han and Sun, Ruoxi and Ren, Xiaoqi and Su, Guolong and Perot, Vincent and Dy, Jennifer and Pfister, Tomas},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={139--149},
year={2022}
}
@article{wang2022dualprompt,
title={DualPrompt: Complementary Prompting for Rehearsal-free Continual Learning},
author={Wang, Zifeng and Zhang, Zizhao and Ebrahimi, Sayna and Sun, Ruoxi and Zhang, Han and Lee, Chen-Yu and Ren, Xiaoqi and Su, Guolong and Perot, Vincent and Dy, Jennifer and others},
journal={European Conference on Computer Vision},
year={2022}
}


