l2p
1.0.0
Cette base de code contient la mise en œuvre de deux méthodes d'apprentissage continu:
L2P est une nouvelle technique d'apprentissage continu qui apprend à provoquer dynamiquement un modèle pré-formé pour apprendre les tâches séquentiellement sous différentes transitions de tâches. Différente des méthodes basées sur la répétition ou basées sur la répétition traditionnelles, L2P ne nécessite ni un tampon de répétition ni une identité de tâche à temps de test. L2P peut être généralisé à divers paramètres d'apprentissage continu, notamment le cadre d'agnostique les plus difficiles et les plus réalistes. L2P surpasse constamment les méthodes antérieures de pointe. Étonnamment, L2P obtient des résultats compétitifs contre les méthodes basées sur la répétition même sans tampon de répétition.
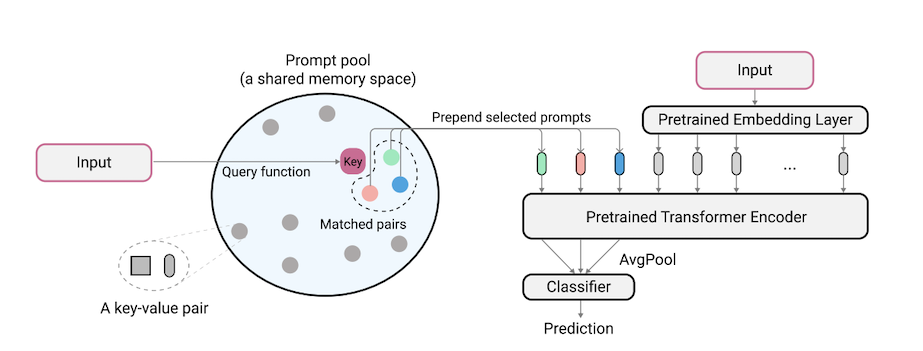
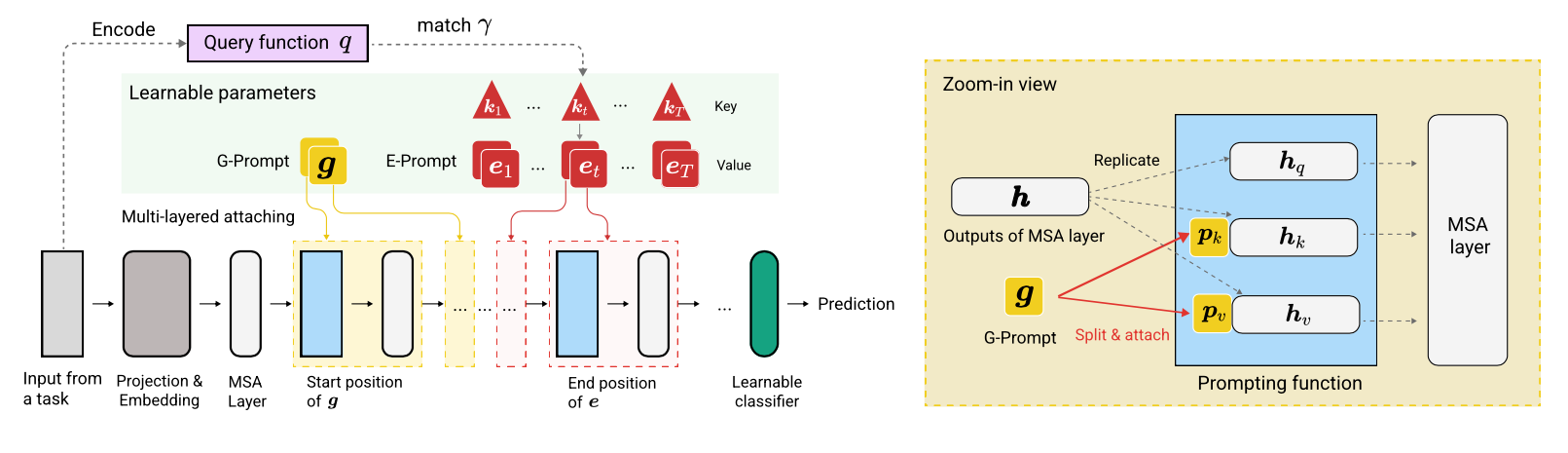
Le code est écrit par Zifeng Wang. Remerciement à https://github.com/google-research/nested-transformrer.
Ce n'est pas un produit Google officiellement pris en charge.
Le benchmark Split ImageNet-R est construit sur ImageNet-R en divisant les 200 classes en 10 tâches avec 20 classes par tâche, voir libml / input_pipeline.py pour plus de détails. Nous pensons que le Split Imagenet-R est d'une grande importance pour la communauté d'apprentissage continue, pour les raisons suivantes:
La base de code a été réimplémentée en pytorch par Jaeho Lee en L2P-Pytorch et DualPrompt-Pytorch.
pip install -r requirements.txt
Après cela, vous devrez peut-être ajuster votre version JAX en fonction de votre version CUDA Driver afin que JAX identifie correctement vos GPU (voir ce problème pour plus de détails).
Remarque: La base de code a été très testée sous l'environnement TPU en utilisant la nouvelle version JAX. Nous travaillons actuellement sur la vérification davantage de l'environnement GPU.
Avant d'exécuter des expériences pour 5 données et Core50, l'étape de préparation de données supplémentaire doit être effectuée comme suit:
"PATH_TO_CORE50" et "PATH_TO_NOT_MNIST" dans libml / input_pipeline.py par les chemins de destination à l'étape 2 Le modèle Vit-B / 16 utilisé dans cet article peut être téléchargé ici. Remarque: Notre base de code prend en charge différentes tailles de vites. Si vous souhaitez essayer des variations de VITS, n'hésitez pas à modifier la config.model_name dans les fichiers de configuration, en suivant les options valides définies dans modèles / vit.py.
Nous fournissons le fichier de configuration pour former et évaluer L2P et DualPrompt sur plusieurs repères dans les configurations.
Pour exécuter L2P sur des ensembles de données de référence:
python main.py --my_config configs/$L2P_CONFIG --workdir=./l2p --my_config.init_checkpoint=<ViT-saved-path/ViT-B_16.npz>
où $L2P_CONFIG peut être l'un des suivants: [cifar100_l2p.py, five_datasets_l2p.py, core50_l2p.py, cifar100_gaussian_l2p.py] .
Remarque: Nous exécutons nos expériences à l'aide de 8 GPU V100 ou 4 TPU, et nous spécifions une taille de lot par périphérique de 16 dans les fichiers de configuration. Cela indique que nous utilisons une taille totale de lots de 128.
Pour exécuter DualProrompt sur des ensembles de données de référence:
python main.py --my_config configs/$DUALPROMPT_CONFIG --workdir=./dualprompt --my_config.init_checkpoint=<ViT-saved-path/ViT-B_16.npz>
où $DUALPROMPT_CONFIG peut être l'un des suivants: [imr_dualprompt.py, cifar100_dualprompt.py] .
Nous utilisons Tensorboard pour visualiser le résultat. Par exemple, si le répertoire de travail spécifié pour exécuter L2P est workdir=./cifar100_l2p , la commande pour vérifier le résultat est la suivante:
tensorboard --logdir ./cifar100_l2p
Voici les mesures importantes à suivre et leurs significations correspondantes:
| Métrique | Description |
|---|---|
| précision_n | Précision de la tâche du N-TH |
| oubli | Oublier moyen jusqu'à la tâche actuelle |
| avg_acc | Précision d'évaluation moyenne jusqu'à la tâche actuelle |
@inproceedings{wang2022learning,
title={Learning to prompt for continual learning},
author={Wang, Zifeng and Zhang, Zizhao and Lee, Chen-Yu and Zhang, Han and Sun, Ruoxi and Ren, Xiaoqi and Su, Guolong and Perot, Vincent and Dy, Jennifer and Pfister, Tomas},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={139--149},
year={2022}
}
@article{wang2022dualprompt,
title={DualPrompt: Complementary Prompting for Rehearsal-free Continual Learning},
author={Wang, Zifeng and Zhang, Zizhao and Ebrahimi, Sayna and Sun, Ruoxi and Zhang, Han and Lee, Chen-Yu and Ren, Xiaoqi and Su, Guolong and Perot, Vincent and Dy, Jennifer and others},
journal={European Conference on Computer Vision},
year={2022}
}


