l2p
1.0.0
Эта кодовая база содержит реализацию двух методов постоянного обучения:
L2P-это новая методика постоянного обучения, которая учится динамически запрашивать предварительно обученную модель для изучения задач последовательно при различных переходах задач. В отличие от основных репетиционных или архитектурных методов, L2P не требует ни репетиционного буфера, ни идентификации задачи времени испытания. L2P может быть обобщен в различных условиях непрерывного обучения, включая наиболее сложные и реалистичные условия, влияющие на задачу. L2P постоянно превосходит предыдущие современные методы. Удивительно, но L2P достигает конкурентных результатов против репетиционных методов даже без репетиционного буфера.
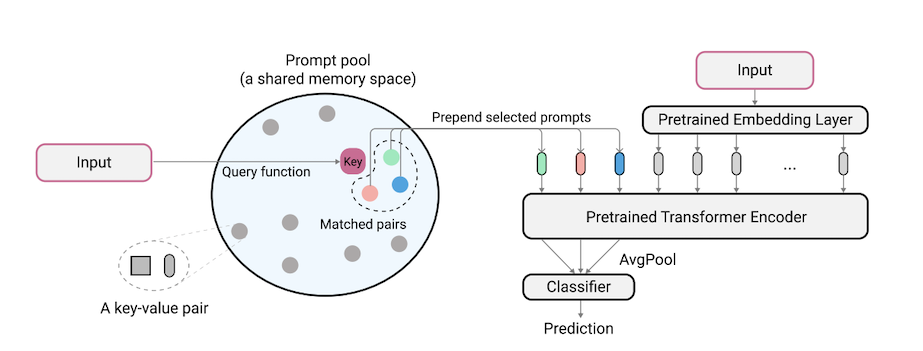
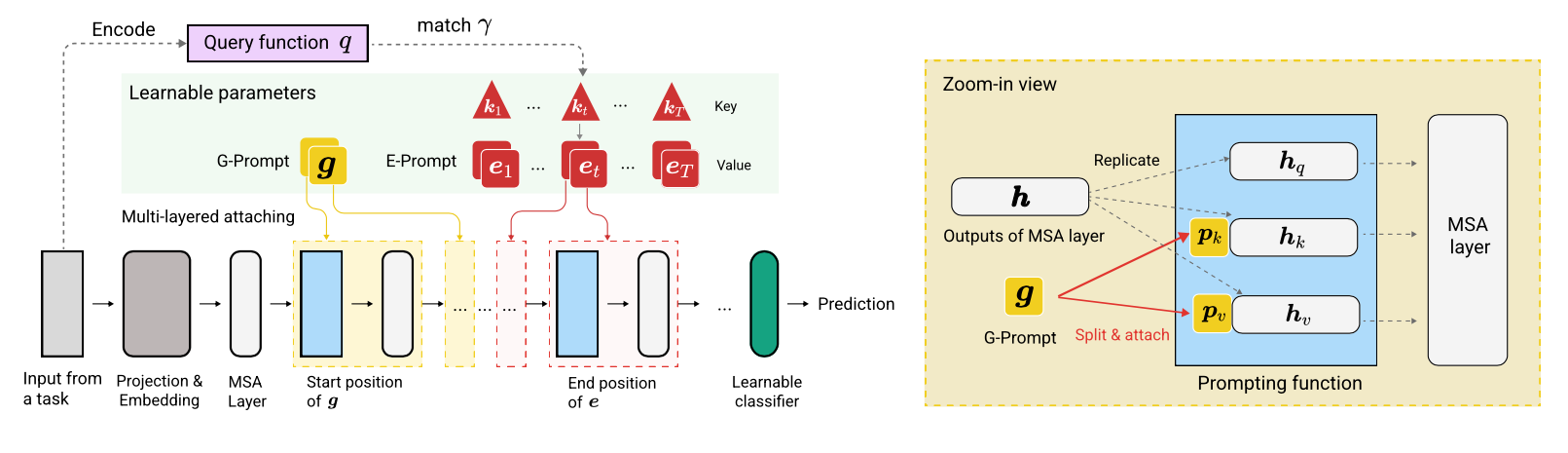
Код написан Zifeng Wang. Подтверждение https://github.com/google-research/nested-transformer.
Это не официально поддерживаемый продукт Google.
Специальный эталон ImageNet-R основывается на ImageNet-R, делит 200 классов на 10 задач с 20 классами на задачу, см. Либемл/input_pipeline.py для получения подробной информации. Мы считаем, что Split ImageNet-R имеет большое значение для постоянного обучения сообщества по следующим причинам:
Кодовая база была переосмыслена в Pytorch Jaeho Lee в L2P-Pytorch и DualPrompt-Pytorch.
pip install -r requirements.txt
После этого вам может потребоваться настроить версию JAX в соответствии с вашей версией драйвера CUDA, чтобы JAX правильно идентифицировал ваши графические процессоры (см. В этом выпуске более подробную информацию).
ПРИМЕЧАНИЕ. Кодовая база была протестирована в рамках среды TPU с использованием новейшей версии JAX. В настоящее время мы работаем над дальнейшей проверкой среды GPU.
Перед запуском экспериментов для 5-датазитов и CORE50, дополнительный этап подготовки наборов данных должен проводиться следующим образом:
"PATH_TO_CORE50" и "PATH_TO_NOT_MNIST" в libml/input_pipeline.py на пути назначения на шаге 2 Модель Vit-B/16, используемая в этой статье, может быть загружена здесь. Примечание. Наша кодовая база фактически поддерживает различные размеры VIT. Если вы хотите попробовать вариации VIT, не стесняйтесь изменить config.model_name в файлах конфигурации, следуя действительным параметрам, определенным в моделях/Vit.py.
Мы предоставляем файл конфигурации для обучения и оценки L2P и DualPrompt на нескольких тестах в конфигурации.
Чтобы запустить L2P на наборах данных.
python main.py --my_config configs/$L2P_CONFIG --workdir=./l2p --my_config.init_checkpoint=<ViT-saved-path/ViT-B_16.npz>
где $L2P_CONFIG может быть одним из последствий: [cifar100_l2p.py, five_datasets_l2p.py, core50_l2p.py, cifar100_gaussian_l2p.py] .
Примечание. Мы запускаем наши эксперименты, используя 8 V100 графических процессоров или 4 TPU, и мы указываем размер пакетного устройства 16 в файлах конфигурации. Это указывает на то, что мы используем общий размер партии 128.
Чтобы запустить двойной продукт на наборах данных.
python main.py --my_config configs/$DUALPROMPT_CONFIG --workdir=./dualprompt --my_config.init_checkpoint=<ViT-saved-path/ViT-B_16.npz>
где $DUALPROMPT_CONFIG может быть одним из последствий: [imr_dualprompt.py, cifar100_dualprompt.py] .
Мы используем Tensorboard для визуализации результата. Например, если рабочий каталог, указанный для запуска L2P, IS workdir=./cifar100_l2p , команда для проверки результат заключается в следующем:
tensorboard --logdir ./cifar100_l2p
Вот важные показатели для отслеживания, и их соответствующие значения:
| Показатель | Описание |
|---|---|
| точность_n | Точность задачи n-й |
| забыв | Среднее забывание до текущей задачи |
| avg_acc | Средняя точность оценки вплоть до текущей задачи |
@inproceedings{wang2022learning,
title={Learning to prompt for continual learning},
author={Wang, Zifeng and Zhang, Zizhao and Lee, Chen-Yu and Zhang, Han and Sun, Ruoxi and Ren, Xiaoqi and Su, Guolong and Perot, Vincent and Dy, Jennifer and Pfister, Tomas},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={139--149},
year={2022}
}
@article{wang2022dualprompt,
title={DualPrompt: Complementary Prompting for Rehearsal-free Continual Learning},
author={Wang, Zifeng and Zhang, Zizhao and Ebrahimi, Sayna and Sun, Ruoxi and Zhang, Han and Lee, Chen-Yu and Ren, Xiaoqi and Su, Guolong and Perot, Vincent and Dy, Jennifer and others},
journal={European Conference on Computer Vision},
year={2022}
}


