l2p
1.0.0
このコードベースには、2つの継続的な学習方法の実装が含まれています。
L2Pは、事前に訓練されたモデルが異なるタスク移行の下で順次タスクを学習するように動的に促すことを学ぶ新しい継続的な学習手法です。主流のリハーサルベースまたはアーキテクチャベースの方法とは異なり、L2Pはリハーサルバッファーもテスト時間タスクのIDも必要ありません。 L2Pは、最も挑戦的で現実的なタスクに依存しない設定を含む、さまざまな継続的な学習設定に一般化できます。 L2Pは、以前の最先端の方法よりも一貫して優れています。驚くべきことに、L2Pは、リハーサルバッファーがなくても、リハーサルベースの方法に対して競争結果を達成します。
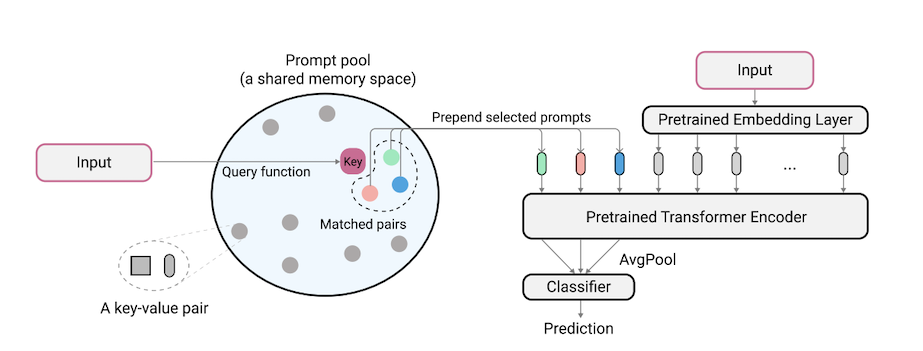
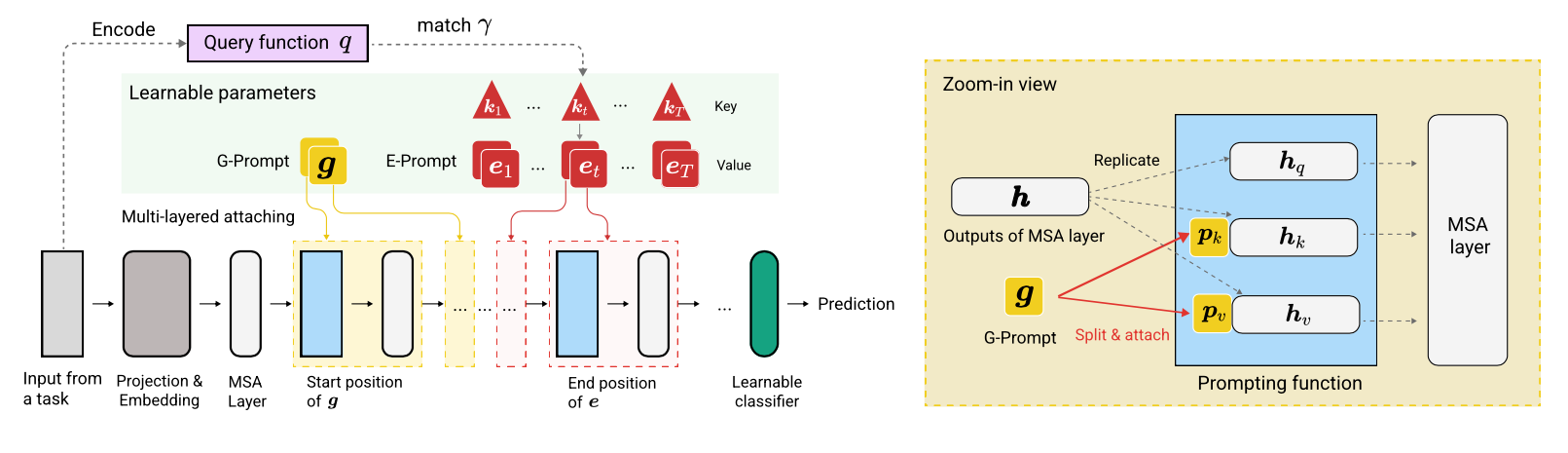
コードはZifeng Wangによって書かれています。 https://github.com/google-research/nested-transformerの謝辞。
これは、公式にサポートされているGoogle製品ではありません。
分割Imagenet-Rベンチマークは、200クラスをタスクあたり20クラスの10のタスクに分割することにより、Imagenet-Rに基づいて構築されています。詳細については、libml/input_pipeline.pyを参照してください。分割されたImagenet-Rは、継続的な学習コミュニティにとって非常に重要であると考えています。
コードベースは、L2P-PytorchとDualPrompt-PytorchのJaeho LeeによってPytorchで再実装されています。
pip install -r requirements.txt
この後、JAXがGPUを正しく識別できるように、CUDAドライバーバージョンに従ってJAXバージョンを調整する必要がある場合があります(詳細については、この問題を参照)。
注:CodeBaseは、最新のJAXバージョンを使用してTPU環境で介してテストされています。現在、GPU環境のさらに検証に取り組んでいます。
5ダタセットとCore50の実験を実行する前に、追加のデータセット準備ステップを次のように実施する必要があります。
"PATH_TO_CORE50"と"PATH_TO_NOT_MNIST"をLIBML/input_pipeline.pyステップ2の宛先パスで交換しますこのペーパーで使用されているVIT-B/16モデルは、こちらでダウンロードできます。注:私たちのコードベースは、実際にはさまざまなサイズのVITをサポートしています。 VITSのバリエーションを試してみたい場合は、モデル/vit.pyで定義されている有効なオプションに従って、 config.model_name configファイルで変更してください。
構成ファイルを提供して、構成内の複数のベンチマークでL2PとDualPromptをトレーニングおよび評価します。
ベンチマークデータセットでL2Pを実行するには:
python main.py --my_config configs/$L2P_CONFIG --workdir=./l2p --my_config.init_checkpoint=<ViT-saved-path/ViT-B_16.npz>
$L2P_CONFIG次の1つになることができます: [cifar100_l2p.py, five_datasets_l2p.py, core50_l2p.py, cifar100_gaussian_l2p.py] 。
注:8つのV100 GPUまたは4つのTPUを使用して実験を実行し、構成ファイルで16のデバイスバッチサイズを指定します。これは、128の合計バッチサイズを使用していることを示しています。
ベンチマークデータセットでDualPromptを実行するには:
python main.py --my_config configs/$DUALPROMPT_CONFIG --workdir=./dualprompt --my_config.init_checkpoint=<ViT-saved-path/ViT-B_16.npz>
ここで、 $DUALPROMPT_CONFIG次の1つになります: [imr_dualprompt.py, cifar100_dualprompt.py] 。
テンソルボードを使用して結果を視覚化します。たとえば、L2Pを実行するように指定された作業ディレクトリがworkdir=./cifar100_l2pである場合、結果を確認するコマンドは次のとおりです。
tensorboard --logdir ./cifar100_l2p
ここに、追跡するための重要な指標と、それらの対応する意味は次のとおりです。
| メトリック | 説明 |
|---|---|
| 精度_n | n番目のタスクの精度 |
| 忘れる | 現在のタスクまで平均忘れられます |
| avg_acc | 現在のタスクまでの平均評価精度 |
@inproceedings{wang2022learning,
title={Learning to prompt for continual learning},
author={Wang, Zifeng and Zhang, Zizhao and Lee, Chen-Yu and Zhang, Han and Sun, Ruoxi and Ren, Xiaoqi and Su, Guolong and Perot, Vincent and Dy, Jennifer and Pfister, Tomas},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={139--149},
year={2022}
}
@article{wang2022dualprompt,
title={DualPrompt: Complementary Prompting for Rehearsal-free Continual Learning},
author={Wang, Zifeng and Zhang, Zizhao and Ebrahimi, Sayna and Sun, Ruoxi and Zhang, Han and Lee, Chen-Yu and Ren, Xiaoqi and Su, Guolong and Perot, Vincent and Dy, Jennifer and others},
journal={European Conference on Computer Vision},
year={2022}
}


