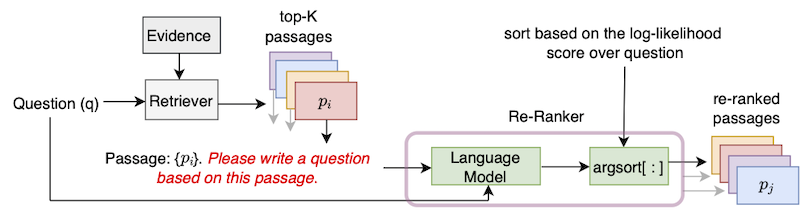
unsupervised passage reranking
1.0.0
该存储库包含在论文“通过零片问题产生的改善段落检索”中引入的UPR(无监督段落)算法的正式实施。
要使用此存储库,需要使用标准的Pytorch安装。我们在需求中提供依赖项.txt文件。
我们建议使用NGC最近的Pytorch容器之一。可以使用命令docker pull nvcr.io/nvidia/pytorch:22.01-py3绘制Docker图像:22.01-PY3。要使用此Docker映像,还需要安装NVIDIA容器工具包。
在Docker容器上,请使用PIP安装安装库transformers和sentencepiece 。
我们遵循DPR公约,并将Wikipedia文章分为100字的长段落。 DPR提供的证据文件可以通过命令下载
python utils / download_data . py - - resource data . wikipedia - split . psgs_w100该证据文件包含用于段落ID,通过文本和段落标题的选项卡分隔字段。
id text title
1 " Aaron Aaron ( or ; " " Ahärôn " " ) is a prophet, high priest, and the brother of Moses in the Abrahamic religions. Knowledge of Aaron, along with his brother Moses, comes exclusiv
ely from religious texts, such as the Bible and Quran. The Hebrew Bible relates that, unlike Moses, who grew up in the Egyptian royal court, Aaron and his elder sister Miriam remained
with their kinsmen in the eastern border-land of Egypt (Goshen). When Moses first confronted the Egyptian king about the Israelites, Aaron served as his brother's spokesman ( " " prophet "
" ) to the Pharaoh. Part of the Law (Torah) that Moses received from " Aaron
2 " God at Sinai granted Aaron the priesthood for himself and his male descendants, and he became the first High Priest of the Israelites. Aaron died before the Israelites crossed
the North Jordan river and he was buried on Mount Hor (Numbers 33:39; Deuteronomy 10:6 says he died and was buried at Moserah). Aaron is also mentioned in the New Testament of the Bib
le. According to the Book of Exodus, Aaron first functioned as Moses' assistant. Because Moses complained that he could not speak well, God appointed Aaron as Moses' " " prophet " " (Exodu
s 4:10-17; 7:1). At the command of Moses, he let " Aaron
... ... ...输入数据格式是JSON。 JSON文件中的每个字典都包含一个问题,一个包含Top-K检索到的数据的列表以及(可选)可能答案的列表。对于每个Top-K段落,我们包括(证据)ID,HAS_ANSWER和(可选的)检索器得分属性。 id属性是Wikipedia证据文件中的段落ID, has_answer表示段落文本是否包含答案跨度。以下是.json文件的模板
[
{
"question" : " .... " ,
"answers" : [ " ... " , " ... " , " ... " ],
"ctxs" : [
{
"id" : " .... " ,
"score" : " ... " ,
"has_answer" : " .... " ,
},
...
]
},
...
]当使用自然问题设置查询时,使用BM25检索段落时的一个示例。
[
{
"question" : " who sings does he love me with reba " ,
"answers" : [ " Linda Davis " ],
"ctxs" : [
{
"id" : 11828871 ,
"score" : 18.3 ,
"has_answer" : false
},
{
"id" : 11828872 ,
"score" : 14.7 ,
"has_answer" : false ,
},
{
"id" : 11828866 ,
"score" : 14.4 ,
"has_answer" : true ,
},
...
]
},
...
]我们提供了前1000个检索的段落,以供媒体Questions-Open(NQ),Triviaqa,squad-open,webQeestions(WebQ)和EntityQuestions(EQ)(EQ)数据集(EQ)数据集(EQ)数据集(EQ)数据集:BM25,MSS,MSS,Contriever,DPR和MSS-DPR。请使用以下命令下载这些数据集
python utils / download_data . py
- - resource { key from download_data . py 's RESOURCES_MAP}
[ optional - - output_dir { your location }]例如,要下载所有TOP-K数据,请使用--resource data 。要下载特定的检索员的TOP-K数据,例如BM25,请使用--resource data.retriever-outputs.bm25 。
要将检索到的段落与UPR重新排列,请使用以下命令,其中需要指示证据文件和TOP-K检索到的top-K的路径。
DISTRIBUTED_ARGS= " -m torch.distributed.launch --nproc_per_node 8 --nnodes 1 --node_rank 0 --master_addr localhost --master_port 6000 "
python ${DISTRIBUTED_ARGS} upr.py
--num-workers 2
--log-interval 1
--topk-passages 1000
--hf-model-name " bigscience/T0_3B "
--use-gpu
--use-bf16
--report-topk-accuracies 1 5 20 100
--evidence-data-path " wikipedia-split/psgs_w100.tsv "
--retriever-topk-passages-path " bm25/nq-dev.json " --use-bf16选项可在Ampere GPU上(例如A100或A6000)上节省速度和内存。但是,在使用V100 GPU时,应删除此参数。
我们在目录“示例”下提供了一个示例脚本“ upr-demo.sh”。要使用此脚本,请相应地修改数据和输入 /输出文件路径。
在UPR中使用T0-3B语言模型时,我们在数据集的测试集上提供评估得分。
| 猎犬(+重新排名) | 小队开场 | Triviaqa | 自然问题 - 开放 | 网络问题 | 实体问题 |
|---|---|---|---|---|---|
| MSS | 51.3 | 67.2 | 60.0 | 49.2 | 51.2 |
| MSS + UPR | 75.7 | 81.3 | 77.3 | 71.8 | 71.3 |
| BM25 | 71.1 | 76.4 | 62.9 | 62.4 | 71.2 |
| BM25 + UPR | 83.6 | 83.0 | 78.6 | 72.9 | 79.3 |
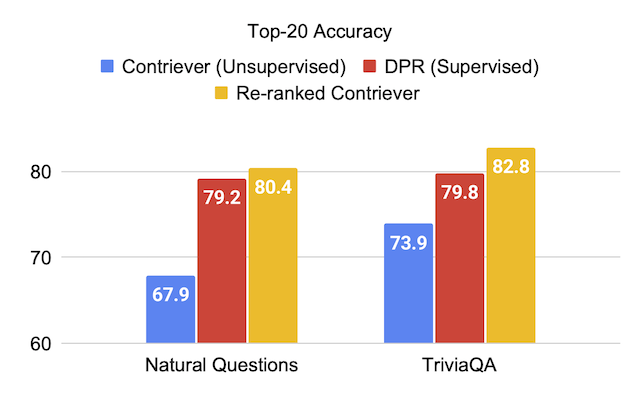
| 反对 | 63.4 | 73.9 | 67.9 | 65.7 | 63.0 |
| CRONTIEVER + UPR | 81.3 | 82.8 | 80.4 | 75.7 | 76.0 |
| 猎犬(+重新排名) | 小队开场 | Triviaqa | 自然问题 - 开放 | 网络问题 | 实体问题 |
|---|---|---|---|---|---|
| dpr | 59.4 | 79.8 | 79.2 | 74.6 | 51.1 |
| DPR + UPR | 80.7 | 84.3 | 83.4 | 76.5 | 65.4 |
| MSS-DPR | 73.1 | 81.9 | 81.4 | 76.9 | 60.6 |
| MSS-DPR + UPR | 85.2 | 84.8 | 83.9 | 77.2 | 73.9 |
我们将从BM25和MSS猎犬自然问题开发的每一个中检索到的前1000个段落的结合。该数据文件可以下载为:
python utils/download_data.py --resource data.retriever-outputs.mss-bm25-union.nq-dev对于这些消融实验,我们通过参数--topk-passages 2000 ,因为该文件包含两组前1000段的联合。
| 语言模型 | 猎犬 | top-1 | 前五名 | 前20名 | 前100名 |
|---|---|---|---|---|---|
| - | BM25 | 22.3 | 43.8 | 62.3 | 76.0 |
| - | MSS | 17.7 | 38.6 | 57.4 | 72.4 |
| T5(3b) | BM25 + MSS | 22.0 | 50.5 | 71.4 | 84.0 |
| gpt-neo(2.7b) | BM25 + MSS | 27.2 | 55.0 | 73.9 | 84.2 |
| GPT-J(6b) | BM25 + MSS | 29.8 | 59.5 | 76.8 | 85.6 |
| T5-LM-ADAPT(250m) | BM25 + MSS | 23.9 | 51.4 | 70.7 | 83.1 |
| T5-LM-ADAPT(800m) | BM25 + MSS | 29.1 | 57.5 | 75.1 | 84.8 |
| T5-LM-ADAPT(3B) | BM25 + MSS | 29.7 | 59.9 | 76.9 | 85.6 |
| T5-LM-ADAPT(11B) | BM25 + MSS | 32.1 | 62.3 | 78.5 | 85.8 |
| T0-3B | BM25 + MSS | 36.7 | 64.9 | 79.1 | 86.1 |
| T0-11b | BM25 + MSS | 37.4 | 64.9 | 79.1 | 86.0 |
可以通过使用脚本gpt/upr_gpt.py在UPR中运行GPT模型。该脚本具有与upr.py脚本相似的选项,但是我们需要将--use-fp16作为参数而不是--use-bf16 。 --hf-model-name的论点可以是EleutherAI/gpt-neo-2.7B或EleutherAI/gpt-j-6B 。
请参阅目录Open-Domain-QA,以获取有关培训和推理预先训练检查点的详细信息。
对于代码库中的任何错误或错误,请打开新问题,或向Devendra Singh Sachan([email protected])发送电子邮件。
如果您发现此代码或数据有用,请考虑将我们的论文视为:
@article{sachan2022improving,
title = " Improving Passage Retrieval with Zero-Shot Question Generation " ,
author = " Sachan, Devendra Singh and Lewis, Mike and Joshi, Mandar and Aghajanyan, Armen and Yih, Wen-tau and Pineau, Joelle and Zettlemoyer, Luke " ,
booktitle = " Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing " ,
publisher = " Association for Computational Linguistics " ,
url = " https://arxiv.org/abs/2204.07496 " ,
year = " 2022 "
}

