unsupervised passage reranking
1.0.0
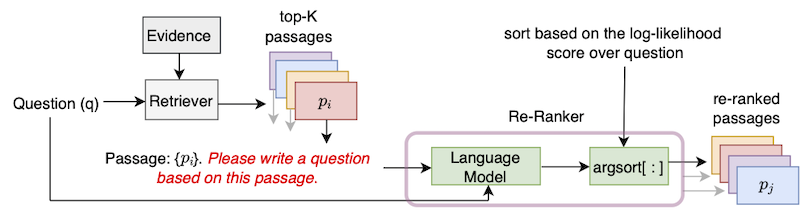
Dieses Repository enthält die offizielle Implementierung des UPR-Algorithmus (unbeaufsichtigter Passage-Raning), der in der Arbeit "Verbesserung der Passage Abruf mit Null-Shot-Fragengenerierung" eingeführt wurde.
Um dieses Repo zu verwenden, ist eine Standardinstallation von Pytorch erforderlich. Wir bieten Abhängigkeiten in der Datei "Anforderungen.txt".
Wir empfehlen, einen der neueren Pytorch -Container von NGC zu verwenden. Ein Docker-Bild kann mit dem Befehl docker pull nvcr.io/nvidia/pytorch:22.01-py3 gezogen werden. Um dieses Docker -Bild zu verwenden, ist auch eine Installation des NVIDIA -Container -Toolkits erforderlich.
Installieren Sie über den Docker -Container die transformers und sentencepiece mit der PIP -Installation.
Wir folgen der DPR-Konvention und segmentieren die Wikipedia-Artikel in 100-Wörter lange Passagen. Die bereitgestellte Evidenzdatei von DVR kann mit dem Befehl heruntergeladen werden
python utils / download_data . py - - resource data . wikipedia - split . psgs_w100Diese Evidenzdatei enthält tabendetriebene Felder für Passage-ID, Passage-Text und Passage-Titel.
id text title
1 " Aaron Aaron ( or ; " " Ahärôn " " ) is a prophet, high priest, and the brother of Moses in the Abrahamic religions. Knowledge of Aaron, along with his brother Moses, comes exclusiv
ely from religious texts, such as the Bible and Quran. The Hebrew Bible relates that, unlike Moses, who grew up in the Egyptian royal court, Aaron and his elder sister Miriam remained
with their kinsmen in the eastern border-land of Egypt (Goshen). When Moses first confronted the Egyptian king about the Israelites, Aaron served as his brother's spokesman ( " " prophet "
" ) to the Pharaoh. Part of the Law (Torah) that Moses received from " Aaron
2 " God at Sinai granted Aaron the priesthood for himself and his male descendants, and he became the first High Priest of the Israelites. Aaron died before the Israelites crossed
the North Jordan river and he was buried on Mount Hor (Numbers 33:39; Deuteronomy 10:6 says he died and was buried at Moserah). Aaron is also mentioned in the New Testament of the Bib
le. According to the Book of Exodus, Aaron first functioned as Moses' assistant. Because Moses complained that he could not speak well, God appointed Aaron as Moses' " " prophet " " (Exodu
s 4:10-17; 7:1). At the command of Moses, he let " Aaron
... ... ... Das Eingabedatenformat ist JSON. Jedes Wörterbuch in der JSON-Datei enthält eine Frage, eine Liste mit Daten der am besten abgerufenen Passagen und einer (optionalen) Liste möglicher Antworten. Für jede Top-K-Passage schließen wir die (Evidence) ID, Has_answer und (optionale) Retriever-Score-Attribute ein. Das id -Attribut ist die Passage -ID aus der Wikipedia -Evidenzdatei, has_answer bezeichnet, ob der Passage -Text die Antwortspanne enthält oder nicht. Im Folgenden finden Sie die Vorlage der .json -Datei
[
{
"question" : " .... " ,
"answers" : [ " ... " , " ... " , " ... " ],
"ctxs" : [
{
"id" : " .... " ,
"score" : " ... " ,
"has_answer" : " .... " ,
},
...
]
},
...
]Ein Beispiel, wenn Passagen unter Verwendung von BM25 abgerufen werden, wenn Abfragen mit natürlichen Fragen dev gesetzt werden.
[
{
"question" : " who sings does he love me with reba " ,
"answers" : [ " Linda Davis " ],
"ctxs" : [
{
"id" : 11828871 ,
"score" : 18.3 ,
"has_answer" : false
},
{
"id" : 11828872 ,
"score" : 14.7 ,
"has_answer" : false ,
},
{
"id" : 11828866 ,
"score" : 14.4 ,
"has_answer" : true ,
},
...
]
},
...
]Wir bieten die Top-1000-Abgerufenen Passagen für die Dev/Test-Splits von NaturalQuestions-Open (NQ), Triviaqa, Squad-Open, WebQuestions (WebQ) und EntityQuestions (EQ) Datensätzen, die 5 Retrievers abdecken: BM25, MSS, Contriever, DPR und MSS-DPR. Bitte verwenden Sie den folgenden Befehl, um diese Datensätze herunterzuladen
python utils / download_data . py
- - resource { key from download_data . py 's RESOURCES_MAP}
[ optional - - output_dir { your location }] --resource data Sie zum Beispiel, um alle Top-K-Daten herunterzuladen. Verwenden Sie die Top-K-Daten eines bestimmten Retrievers, z --resource data.retriever-outputs.bm25
Um die abgerufenen Passagen mit UPR erneut zu beziehen, verwenden Sie den folgenden Befehl, bei dem die Wege der Evidenzdatei und der Top-K-abgerufenen Passage-Datei angezeigt werden müssen.
DISTRIBUTED_ARGS= " -m torch.distributed.launch --nproc_per_node 8 --nnodes 1 --node_rank 0 --master_addr localhost --master_port 6000 "
python ${DISTRIBUTED_ARGS} upr.py
--num-workers 2
--log-interval 1
--topk-passages 1000
--hf-model-name " bigscience/T0_3B "
--use-gpu
--use-bf16
--report-topk-accuracies 1 5 20 100
--evidence-data-path " wikipedia-split/psgs_w100.tsv "
--retriever-topk-passages-path " bm25/nq-dev.json " --use-bf16 -Option bietet Geschwindigkeit und Speichereinsparungen bei Ampere-GPUs wie A100 oder A6000. Bei der Arbeit mit V100 GPUs sollte dieses Argument jedoch entfernt werden.
Wir haben unter dem Verzeichnis "Beispiele" ein Beispiel-Skript "upr-demo.sh" bereitgestellt. Um dieses Skript zu verwenden, ändern Sie bitte die Daten- und Eingabe- / Ausgabedateipfade entsprechend.
Wir stellen die Bewertungsbewertungen für die Testsätze von Datensätzen an, wenn wir das T0-3B-Sprachmodell in UPR verwenden.
| Retriever (+Re-Ranker) | Squad-Open | Triviaqa | Natürliche Fragen | Webfragen | Entitätsfragen |
|---|---|---|---|---|---|
| MSS | 51.3 | 67,2 | 60.0 | 49,2 | 51.2 |
| MSS + UPR | 75.7 | 81.3 | 77,3 | 71,8 | 71.3 |
| BM25 | 71.1 | 76,4 | 62.9 | 62.4 | 71.2 |
| BM25 + upr | 83.6 | 83.0 | 78,6 | 72.9 | 79,3 |
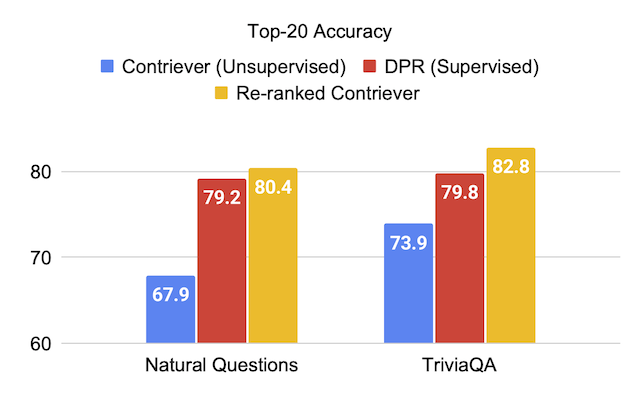
| Gegenstand | 63.4 | 73,9 | 67,9 | 65.7 | 63.0 |
| Contriever + upr | 81.3 | 82.8 | 80.4 | 75.7 | 76.0 |
| Retriever (+Re-Ranker) | Squad-Open | Triviaqa | Natürliche Fragen | Webfragen | Entitätsfragen |
|---|---|---|---|---|---|
| DPR | 59.4 | 79,8 | 79,2 | 74,6 | 51.1 |
| DPR + UPR | 80.7 | 84.3 | 83.4 | 76,5 | 65.4 |
| MSS-DPR | 73.1 | 81.9 | 81.4 | 76,9 | 60.6 |
| MSS-DPR + UPR | 85.2 | 84,8 | 83.9 | 77,2 | 73,9 |
Wir haben die Vereinigung von Top-1000-Passagen erneut an den BM25- und MSS Retrievers natürlichen Fragen-Open-Entwicklungs-Set wiederholt. Diese Datendatei kann heruntergeladen werden als:
python utils/download_data.py --resource data.retriever-outputs.mss-bm25-union.nq-dev Für diese Ablationsexperimente bestehen wir das Argument --topk-passages 2000 , da diese Datei die Vereinigung von zwei Sätzen von Top 1000-Passagen enthält.
| Sprachmodell | Retriever | Top-1 | Top-5 | Top-20 | Top-100 |
|---|---|---|---|---|---|
| - - | BM25 | 22.3 | 43,8 | 62.3 | 76.0 |
| - - | MSS | 17.7 | 38.6 | 57,4 | 72.4 |
| T5 (3B) | BM25 + MSS | 22.0 | 50,5 | 71,4 | 84.0 |
| Gpt-neo (2,7b) | BM25 + MSS | 27.2 | 55.0 | 73,9 | 84.2 |
| GPT-J (6b) | BM25 + MSS | 29.8 | 59,5 | 76,8 | 85.6 |
| T5-LM-Adapt (250 m) | BM25 + MSS | 23.9 | 51.4 | 70.7 | 83.1 |
| 800 m (T5-LM-Adapt) | BM25 + MSS | 29.1 | 57,5 | 75.1 | 84,8 |
| T5-lm-adapt (3b) | BM25 + MSS | 29.7 | 59,9 | 76,9 | 85.6 |
| T5-LM-Adapt (11b) | BM25 + MSS | 32.1 | 62.3 | 78,5 | 85,8 |
| T0-3B | BM25 + MSS | 36.7 | 64.9 | 79.1 | 86.1 |
| T0-11B | BM25 + MSS | 37,4 | 64.9 | 79.1 | 86.0 |
Die GPT -Modelle können in UPR mit dem Skript gpt/upr_gpt.py ausgeführt werden. Dieses Skript hat ähnliche Optionen wie das von upr.py -Skript, aber wir müssen --use-fp16 als Argument anstelle von --use-bf16 übergeben. Das Argument von --hf-model-name kann entweder EleutherAI/gpt-neo-2.7B oder EleutherAI/gpt-j-6B sein.
Weitere Informationen finden Sie im Verzeichnis Open-Domain-QA, um Schulungen und Schlussfolgerungen mit den vorgeborenen Kontrollpunkten durchzuführen.
Für Fehler oder Fehler in der Codebasis öffnen Sie bitte entweder ein neues Problem oder senden Sie eine E -Mail an Devendra Singh Sachan ([email protected]).
Wenn Sie diesen Code oder diese Daten nützlich finden, sollten Sie in unserem Papier als:
@article{sachan2022improving,
title = " Improving Passage Retrieval with Zero-Shot Question Generation " ,
author = " Sachan, Devendra Singh and Lewis, Mike and Joshi, Mandar and Aghajanyan, Armen and Yih, Wen-tau and Pineau, Joelle and Zettlemoyer, Luke " ,
booktitle = " Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing " ,
publisher = " Association for Computational Linguistics " ,
url = " https://arxiv.org/abs/2204.07496 " ,
year = " 2022 "
}

