unsupervised passage reranking
1.0.0
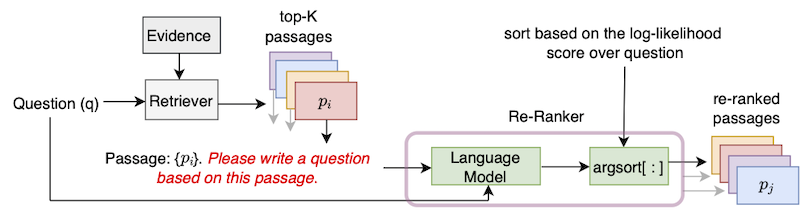
이 저장소에는 논문 "제로 샷 질문 생성을 가진 통로 검색 개선"에 도입 된 UPR (비 감독 통과 재 승적) 알고리즘의 공식 구현이 포함되어 있습니다.
이 저장소를 사용하려면 Pytorch의 표준 설치가 필요합니다. 요구 사항 .txt 파일에 종속성을 제공합니다.
NGC의 최근 Pytorch 컨테이너 중 하나를 사용하는 것이 좋습니다. Docker 이미지는 docker pull nvcr.io/nvidia/pytorch:22.01-py3 명령으로 가져올 수 있습니다. 이 Docker 이미지를 사용하려면 NVIDIA 컨테이너 툴킷의 설치도 필요합니다.
Docker 컨테이너 위에는 PIP 설치를 사용하여 라이브러리 transformers 및 sentencepiece 설치하십시오.
우리는 DPR 컨벤션을 따르고 Wikipedia 기사를 100 단어 긴 구절로 분류합니다. DPR의 제공된 증거 파일은 명령으로 다운로드 할 수 있습니다.
python utils / download_data . py - - resource data . wikipedia - split . psgs_w100이 증거 파일에는 Passage ID, Passage Text 및 Passage Title에 대한 탭 구분 된 필드가 포함되어 있습니다.
id text title
1 " Aaron Aaron ( or ; " " Ahärôn " " ) is a prophet, high priest, and the brother of Moses in the Abrahamic religions. Knowledge of Aaron, along with his brother Moses, comes exclusiv
ely from religious texts, such as the Bible and Quran. The Hebrew Bible relates that, unlike Moses, who grew up in the Egyptian royal court, Aaron and his elder sister Miriam remained
with their kinsmen in the eastern border-land of Egypt (Goshen). When Moses first confronted the Egyptian king about the Israelites, Aaron served as his brother's spokesman ( " " prophet "
" ) to the Pharaoh. Part of the Law (Torah) that Moses received from " Aaron
2 " God at Sinai granted Aaron the priesthood for himself and his male descendants, and he became the first High Priest of the Israelites. Aaron died before the Israelites crossed
the North Jordan river and he was buried on Mount Hor (Numbers 33:39; Deuteronomy 10:6 says he died and was buried at Moserah). Aaron is also mentioned in the New Testament of the Bib
le. According to the Book of Exodus, Aaron first functioned as Moses' assistant. Because Moses complained that he could not speak well, God appointed Aaron as Moses' " " prophet " " (Exodu
s 4:10-17; 7:1). At the command of Moses, he let " Aaron
... ... ... 입력 데이터 형식은 JSON입니다. JSON 파일의 각 사전에는 하나의 질문, Top-K 검색 구절의 데이터가 포함 된 목록, (선택 사항) 가능한 답변 목록이 포함되어 있습니다. 각 Top-K 구절에 대해 (증거) ID, HAS_ANSWER 및 (선택 사항) 리트리버 점수 속성을 포함합니다. id 속성은 Wikipedia 증거 파일의 Passage ID입니다. has_answer Passage 텍스트에 답변을 포함하는지 여부를 나타냅니다. 다음은 .json 파일의 템플릿입니다
[
{
"question" : " .... " ,
"answers" : [ " ... " , " ... " , " ... " ],
"ctxs" : [
{
"id" : " .... " ,
"score" : " ... " ,
"has_answer" : " .... " ,
},
...
]
},
...
]자연스럽게 질문을 사용하는 쿼리를 사용하면 BM25를 사용하여 구절을 검색 할 때의 예입니다.
[
{
"question" : " who sings does he love me with reba " ,
"answers" : [ " Linda Davis " ],
"ctxs" : [
{
"id" : 11828871 ,
"score" : 18.3 ,
"has_answer" : false
},
{
"id" : 11828872 ,
"score" : 14.7 ,
"has_answer" : false ,
},
{
"id" : 11828866 ,
"score" : 14.4 ,
"has_answer" : true ,
},
...
]
},
...
]우리는 자연 퀘스트-오픈 (NQ), Triviaqa, 분대, 웹 퀘스트 (Webquestions) 및 EntityQuestions (EQ) 데이터 세트 (BM25, MSS, Contriever, DPR 및 MSS-DPR을 다루는 Dev/Test Splits of Naturalquestions-Open), Triviaqa, Squad-Open (Webquestions) 및 EntityQuestions (EQ) 데이터 세트에 대한 상위 1000 개의 복수 구절을 제공합니다. 다음 명령을 사용 하여이 데이터 세트를 다운로드하십시오
python utils / download_data . py
- - resource { key from download_data . py 's RESOURCES_MAP}
[ optional - - output_dir { your location }] 예를 들어, 모든 Top-K 데이터를 다운로드하려면 --resource data 사용하십시오. 특정 Retriever의 Top-K 데이터를 다운로드하려면 BM25와 같은 --resource data.retriever-outputs.bm25 사용하십시오.
UPR로 검색된 구절을 재평가하려면 증거 파일 및 Top-K 검색된 통로 파일의 경로가 표시되어야하는 다음 명령을 사용하십시오.
DISTRIBUTED_ARGS= " -m torch.distributed.launch --nproc_per_node 8 --nnodes 1 --node_rank 0 --master_addr localhost --master_port 6000 "
python ${DISTRIBUTED_ARGS} upr.py
--num-workers 2
--log-interval 1
--topk-passages 1000
--hf-model-name " bigscience/T0_3B "
--use-gpu
--use-bf16
--report-topk-accuracies 1 5 20 100
--evidence-data-path " wikipedia-split/psgs_w100.tsv "
--retriever-topk-passages-path " bm25/nq-dev.json " --use-bf16 옵션은 A100 또는 A6000과 같은 Ampere GPU의 속도 업 및 메모리 절약을 제공합니다. 그러나 V100 GPU로 작업 할 때는이 인수를 제거해야합니다.
디렉토리 "예제"아래의 예제 스크립트 "upr-demo.sh"를 제공했습니다. 이 스크립트를 사용하려면 데이터 및 입력 / 출력 파일 경로를 수정하십시오.
UPR에서 T0-3B 언어 모델을 사용할 때 데이터 세트의 테스트 세트에 대한 평가 점수를 제공합니다.
| 리트리버 (+ranker) | 분대 개방 | Triviaqa | 자연스러운 질문이 열립니다 | 웹 질문 | 엔티티 질문 |
|---|---|---|---|---|---|
| MSS | 51.3 | 67.2 | 60.0 | 49.2 | 51.2 |
| MSS + UPR | 75.7 | 81.3 | 77.3 | 71.8 | 71.3 |
| BM25 | 71.1 | 76.4 | 62.9 | 62.4 | 71.2 |
| BM25 + UPR | 83.6 | 83.0 | 78.6 | 72.9 | 79.3 |
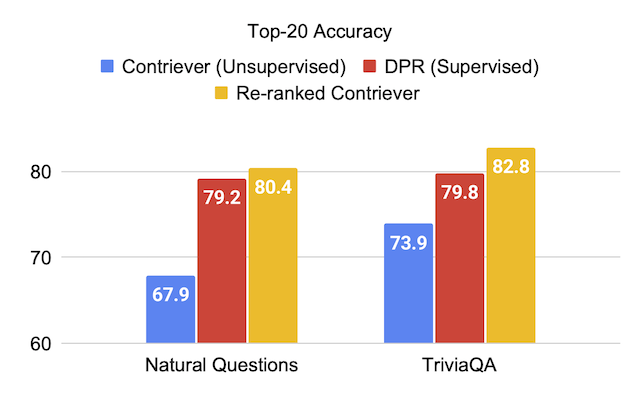
| 반대자 | 63.4 | 73.9 | 67.9 | 65.7 | 63.0 |
| Contriever + UPR | 81.3 | 82.8 | 80.4 | 75.7 | 76.0 |
| 리트리버 (+ranker) | 분대 개방 | Triviaqa | 자연스러운 질문이 열립니다 | 웹 질문 | 엔티티 질문 |
|---|---|---|---|---|---|
| DPR | 59.4 | 79.8 | 79.2 | 74.6 | 51.1 |
| DPR + UPR | 80.7 | 84.3 | 83.4 | 76.5 | 65.4 |
| MSS-DPR | 73.1 | 81.9 | 81.4 | 76.9 | 60.6 |
| MSS-DPR + UPR | 85.2 | 84.8 | 83.9 | 77.2 | 73.9 |
우리는 BM25 및 MSS 리트리버 각각에서 검색된 상위 1000 개의 구절의 연합을 재평가합니다. 이 데이터 파일은 다음과 같이 다운로드 할 수 있습니다.
python utils/download_data.py --resource data.retriever-outputs.mss-bm25-union.nq-dev 이러한 절제 실험을 위해, 우리는이 파일에 상단 1000 구절의 두 세트의 결합이 포함되어 있기 때문에 --topk-passages 2000 을 전달합니다.
| 언어 모델 | 리트리버 | 1 위 | 상위 5 | 20 위 | 10 대 |
|---|---|---|---|---|---|
| - | BM25 | 22.3 | 43.8 | 62.3 | 76.0 |
| - | MSS | 17.7 | 38.6 | 57.4 | 72.4 |
| T5 (3B) | BM25 + MSS | 22.0 | 50.5 | 71.4 | 84.0 |
| gpt-neo (2.7b) | BM25 + MSS | 27.2 | 55.0 | 73.9 | 84.2 |
| GPT-J (6B) | BM25 + MSS | 29.8 | 59.5 | 76.8 | 85.6 |
| T5-LM-Adapt (250m) | BM25 + MSS | 23.9 | 51.4 | 70.7 | 83.1 |
| T5-LM-Adapt (800m) | BM25 + MSS | 29.1 | 57.5 | 75.1 | 84.8 |
| T5-LM-Adapt (3B) | BM25 + MSS | 29.7 | 59.9 | 76.9 | 85.6 |
| T5-LM-Adapt (11b) | BM25 + MSS | 32.1 | 62.3 | 78.5 | 85.8 |
| T0-3B | BM25 + MSS | 36.7 | 64.9 | 79.1 | 86.1 |
| T0-11B | BM25 + MSS | 37.4 | 64.9 | 79.1 | 86.0 |
GPT 모델은 스크립트 gpt/upr_gpt.py 사용하여 UPR로 실행할 수 있습니다. 이 스크립트에는 upr.py 스크립트와 유사한 옵션이 있지만 --use-bf16 대신 인수로 --use-fp16 통과해야합니다. --hf-model-name 의 주장은 EleutherAI/gpt-neo-2.7B 또는 EleutherAI/gpt-j-6B 일 수 있습니다.
미리 훈련 된 체크 포인트에 대한 훈련 및 추론을 수행하려면 Directory Open-Domain-QA를 참조하십시오.
Codebase의 오류 또는 버그는 새 문제를 열거 나 Devendra Singh Sachan ([email protected])에게 이메일을 보내주십시오.
이 코드 나 데이터가 유용하다고 생각되면 다음과 같은 논문을 인용하는 것을 고려하십시오.
@article{sachan2022improving,
title = " Improving Passage Retrieval with Zero-Shot Question Generation " ,
author = " Sachan, Devendra Singh and Lewis, Mike and Joshi, Mandar and Aghajanyan, Armen and Yih, Wen-tau and Pineau, Joelle and Zettlemoyer, Luke " ,
booktitle = " Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing " ,
publisher = " Association for Computational Linguistics " ,
url = " https://arxiv.org/abs/2204.07496 " ,
year = " 2022 "
}

