candy machine
1.0.0
基于Web的手动图像标记器用于训练自定义稳定扩散Loras&Dreambooth模型
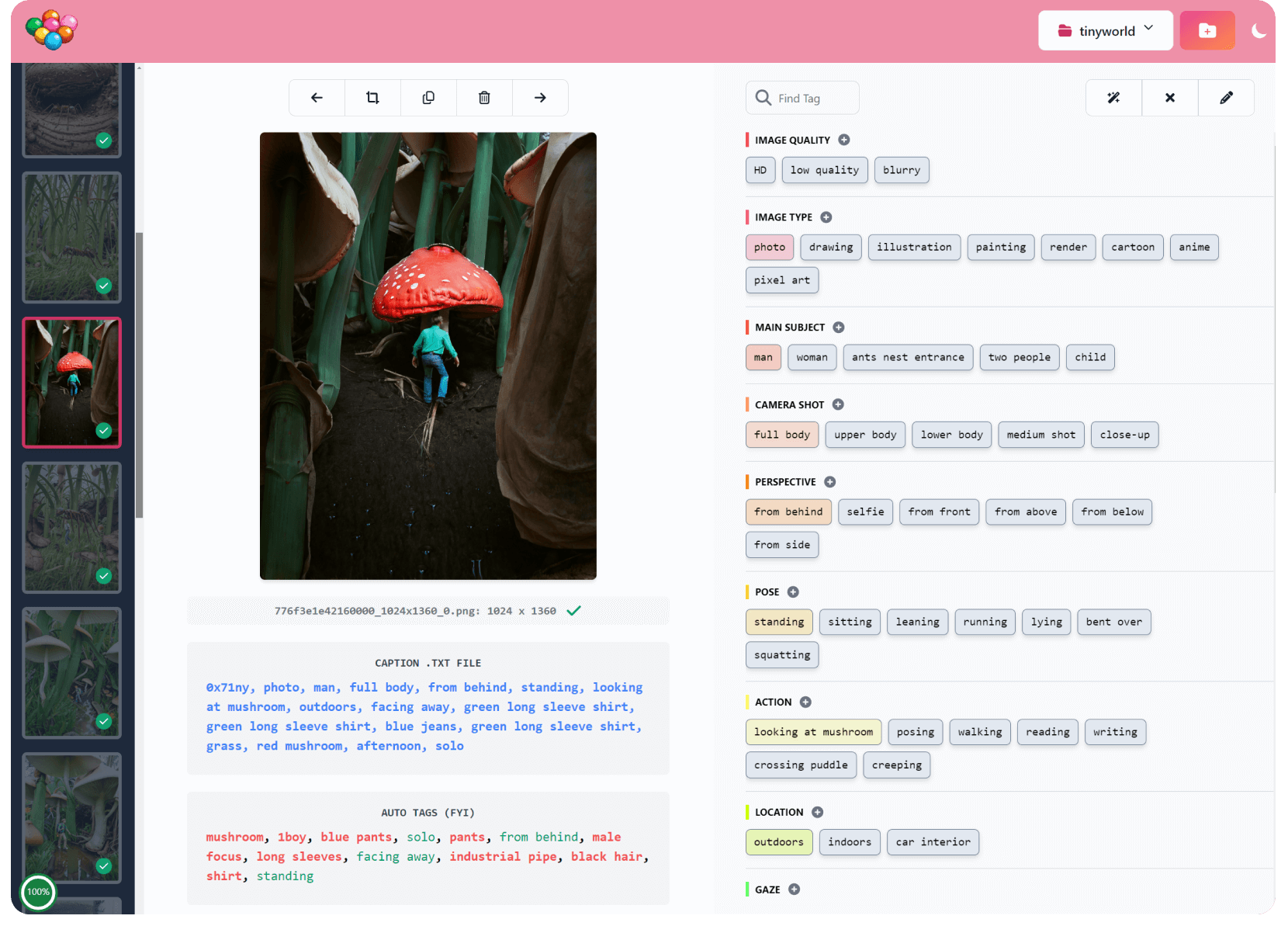
Candy Machine是一个新生的图像标记器,用于用.txt字幕文件手动标记小数据集(<1k images):
可自定义的标签布局,用于一致的标签
占位符标签模板:ie {type} clothes ,在添加标签时可以指定{type}
内部形成的图像编辑(作物,旋转和翻转水平)
创建新项目时使用wd-v1-4-convnext-tagger.v3的标签建议
自动文件从.webp,.avif,.gif等转换为.png
进度%饼图- 在您想知道“我已经做好了吗?!”的时候
键盘快捷键- 按'?'对于列表
还有更多即将到来!
糖果机完全在您的本地机器上以“单人玩家”模式运行。没有信息传输到任何第三方系统。
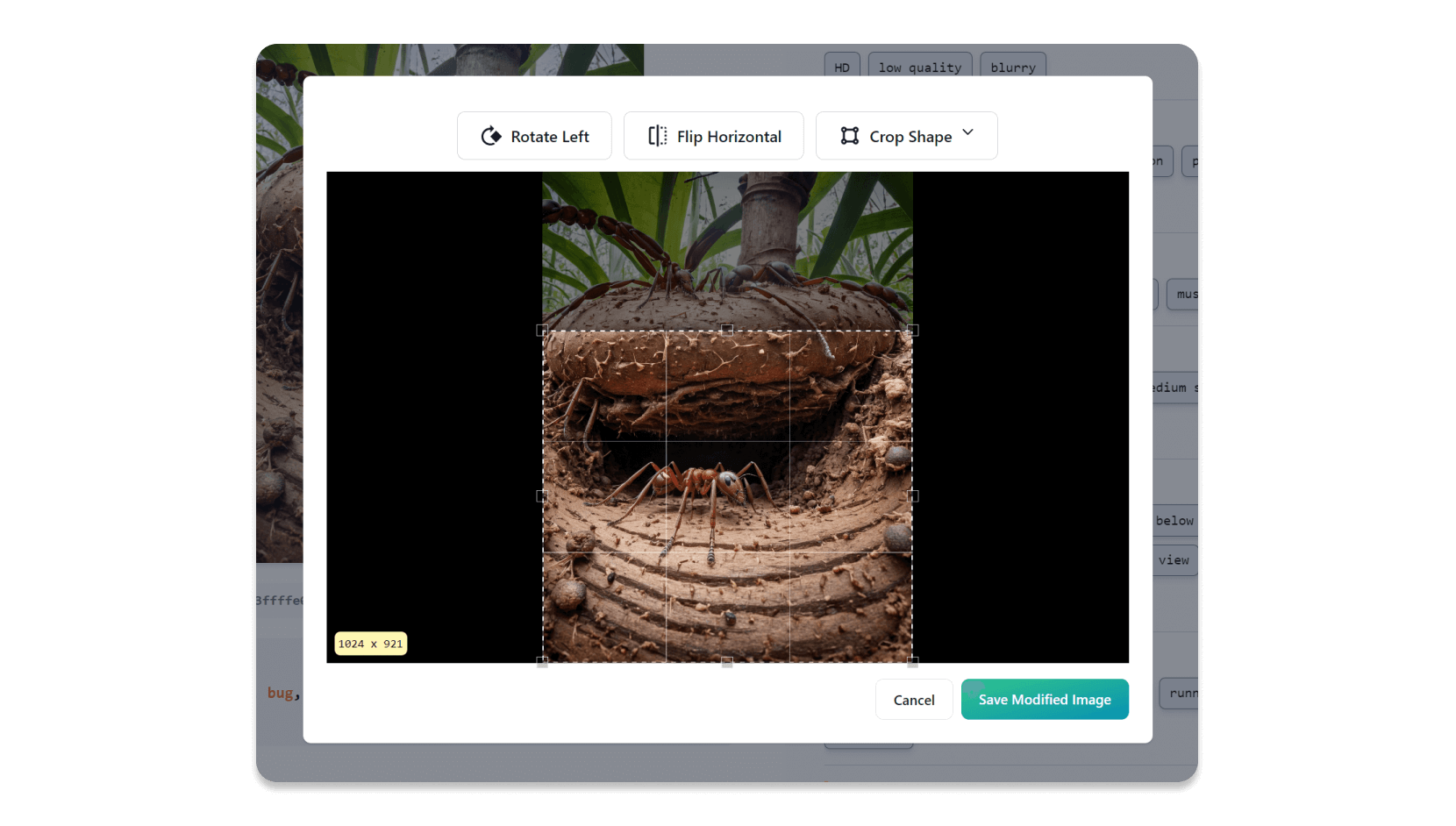
我受到有关如何最好地标记小型图像数据集的Reddit帖子的启发,主要关注一致性。
我也从不喜欢构建数据集的“贴心”部分 - 转换图像,重命名,裁剪等。我想快速,简单,简单,谁知道,甚至很有趣!
H/T到Binaryalley的原型也是如此。
该软件完全免费用于个人非商业用途。如果您在商业环境或商业用途中使用它(即从中赚钱),请与我联系以安排付费许可证。这将有助于支持我的发展成本。
git clone [email protected]:mikeknapp/candy-machine.git
cd candy-machine
run浏览器窗口应自动打开: http://127.0.0.1:5000/
(请注意,我还没有测试过,可能有错误!)
git clone [email protected]:mikeknapp/candy-machine.git
cd candy-machine
chmod +x run.sh
./run.sh浏览器窗口应自动打开: http://127.0.0.1:5000/
需要Cuda 12.2和Cudnn8.x。
激活Python Venv。 (查看Inside run.bat了解如何做到这一点的线索。)
安装onnxruntime-gpu
pip install onnxruntime-gpu --extra-index-url
https://aiinfra.pkgs.visualstudio.com/PublicPackages/_packaging/onnxruntime-cuda-12/pypi/simple/ 无法编辑应用程序中的项目标签布局或默认标签布局。 (解决方法:编辑default_categories.json在服务器目录中或一个项目的categories.json 。对于后者,请确保不要删除正在积极使用的标签,否则,如果将来保存该图像,它们将在标签列表的末端被孤儿。
无法在项目中添加更多图像! (解决方法:创建一个新项目。我知道,不是理想的。)
无法编辑触发单词 /同义词。 (解决方法:编辑项目的config.json和所有现有的.txt字幕文件。)
技术堆栈:
在花费任何时间编写代码之前,请与您的提案打开一个问题,以便我们讨论。谢谢!
python -m venv venv
call .venvScriptsactivate
pip install -r requirements.txt先决条件:节点和纱线。
cd ui
yarn start cd server
python main.py 请给我发送消息或打开问题。谢谢!


