Empirical JobModel HLP
1.0.0
这项研究的总体目的是使用简历和职位描述,设计一个系统,可以将候选人和职位分类为软件开发和数据科学相关领域的合适或不合适。这是通过识别和建模由招聘人员进行的招聘过程,用于自动分析人员进行的。
使用该仪器的名称,树木,星座,水果对乐器进行分组。每组包含六个相关的简历。例如,在希腊文件夹中,有Delta,Kappa,Lambda,Sigma,Omega和Tau CVS。该集合的乳胶版本是使用Vinayak Sharma在Overleaf上的修改版本清洁简历模板制成的。 CVS中的“现在”是指2023年11月。
它包含两个Excel文件。 fspace_powerset_measure.xlsx文件具有常规模糊度量的定义
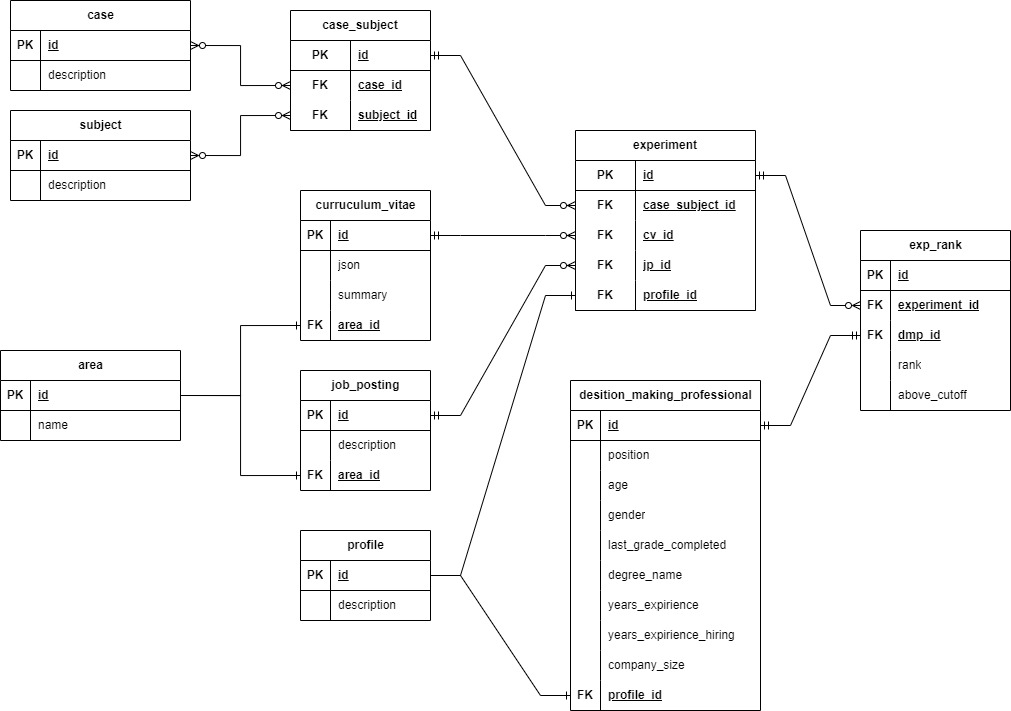
3_db_eval_and_query文件夹中包含三个文件。第一个是hlp_ranking_experiment.db,它是使用sqlite3在python中创建的,并包含ER图中可以看到的实验信息。第二个文件sqlite-examplequeries是jupyter笔记本,其中包含数据库使用范围的一些示例。第三个文件包含所有表的字典,解释了每列的含义。
# Assuming that a connection is established above
# The IDs you want to search for
decision_making_professional_id = 14
case_id = 'Greece'
# SQL query using placeholders for parameters
sql_query = """
SELECT er.*, cs.case_id, cs.subject_id
FROM exp_rank er
JOIN experiment e ON er.experiment_id = e.id
JOIN case_subject cs ON e.case_subject_id = cs.id
JOIN decision_making_professional dmp ON er.dmp_id = dmp.id
WHERE cs.case_id = ? AND dmp.id = ?;
"""
# Define your query with parameters
parameters = ( case_id , decision_making_professional_id )
# Execute the query and fetch the result into a DataFrame
df = pd . read_sql_query ( sql_query , conn , params = parameters )| ID | 实验_id | DMP_ID | 秩 | 上面_cutoff | case_id | 主题_id |
|---|---|---|---|---|---|---|
| 1 | 1 | 14 | 5 | 1 | 希腊 | 三角洲 |
| 2 | 2 | 14 | 2 | 1 | 希腊 | 卡帕 |
| 3 | 3 | 14 | 3 | 1 | 希腊 | Lambda |
| 4 | 4 | 14 | 1 | 1 | 希腊 | 西格玛 |
| 5 | 5 | 14 | 4 | 1 | 希腊 | 欧米茄 |
| 6 | 6 | 14 | 6 | 1 | 希腊 | tau |
对于有关这些资源的任何查询,建议或澄清,您可以通过以下方式与作者联系:
玛丽亚·埃琳娜(MaríaElena)
乔丹·乔尔
我们要承认以下人员对这项工作的宝贵贡献:
感谢您对这项研究的兴趣。


