Modèle de correspondance d'emploi empirique utilisant des connaissances humaines expertes: une approche de méthodes mixtes
L'objectif primordial de cette recherche était de, en utilisant des curriculum vitae et des descriptions de poste, concevoir un système qui permet la classification des candidats et des postes de travail dans le développement de logiciels et les zones liées à la science des données comme adaptées ou non appropriées. Ceci a été réalisé en identifiant et en modélisant des processus de recrutement menés par le personnel d'embauche, pour une application dans le profilage automatique du personnel.
Contenu
- 1_instruments_eval : Ce dossier contient les versions JSON et Latex des instruments pour l'expérience d'évaluation.
- 2_fuzzymeasuredata : Ce dossier contient les mesures qui définissent la mesure floue ordinaire $ mu $ utilisé dans l'intégration de Chaquet. Contient également les poids d'ancienneté $ W_j $ , $ W_m $ , $ W_s $ .
- 3_DB_EVAL_AND_QUERY : Ce dossier contient le classement et les coupures de classement des CV fabriqués par les participants de l'expérience et les métadonnées générales associées à chaque participant au format de base de données. Des fonctions Python spéciales sont fournies pour interroger cette base de données.
- 4_TRAIN_TEST_SET : Ce dossier contient l'ensemble de données CV et description du travail utilisé pendant la formation du réseau siamois. Chaque ensemble de données comprend son schéma de table.
1_instruments_eval Description
Les instruments sont regroupés en utilisant les noms de l'ensemble Grèce , arbres , constellations , fruits . Chaque ensemble contient six CV associés. Par exemple, à l'intérieur du dossier de la Grèce , il y a les cvs delta, kappa, lambda, sigma, oméga et tau. La version latex des ensembles a été réalisée à l'aide d'un modèle de CV Clean de version modifiée par Vinayak Sharma sur Overleaf. Le «présent» dans le CVS fait référence à novembre 2023.
2_fuzzymeasuredata Description
Il contient deux fichiers Excel. Le fichier fspace_powerset_measure.xlsx a la définition de la mesure floue ordinaire $ mu $ et Senoritylevelsweights.xlsx contient le travail d'ancienneté Junior ( $ W_j $ ), de niveau intermédiaire ( $ W_m $ ), et senior ou supérieur ( $ W_s $ ).
3_DB_EVAL_AND_QUERY Description
Trois fichiers sont inclus dans le dossier 3_DB_EVAL_AND_QUERY. Le premier est hlp_ranking_experiment.db, cela a été créé dans Python à l'aide de SQLite3, et contient les informations de l'expérience comme on peut le voir dans le diagramme ER. Le deuxième fichier SQLite-ExampleQueries est un cahier Jupyter avec quelques exemples de l'utilisation de la base de données. Le troisième fichier contient un dictionnaire de toutes les tables, expliquant la signification de chaque colonne.
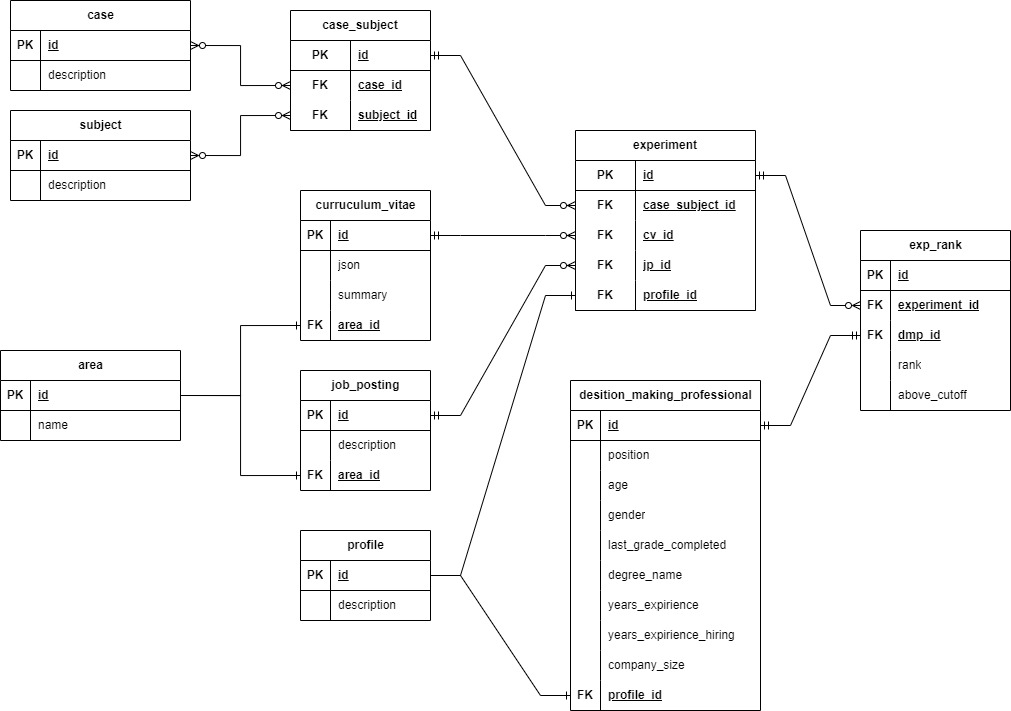
Exemple de cellule:
# Assuming that a connection is established above
# The IDs you want to search for
decision_making_professional_id = 14
case_id = 'Greece'
# SQL query using placeholders for parameters
sql_query = """
SELECT er.*, cs.case_id, cs.subject_id
FROM exp_rank er
JOIN experiment e ON er.experiment_id = e.id
JOIN case_subject cs ON e.case_subject_id = cs.id
JOIN decision_making_professional dmp ON er.dmp_id = dmp.id
WHERE cs.case_id = ? AND dmp.id = ?;
"""
# Define your query with parameters
parameters = ( case_id , decision_making_professional_id )
# Execute the query and fetch the result into a DataFrame
df = pd . read_sql_query ( sql_query , conn , params = parameters )
Résultat:
| identifiant | Experiment_id | dmp_id | rang | ci-dessus_cutoff | case_id | Subject_id |
|---|
| 1 | 1 | 14 | 5 | 1 | Grèce | Delta |
| 2 | 2 | 14 | 2 | 1 | Grèce | Kappa |
| 3 | 3 | 14 | 3 | 1 | Grèce | Lambda |
| 4 | 4 | 14 | 1 | 1 | Grèce | Sigma |
| 5 | 5 | 14 | 4 | 1 | Grèce | Oméga |
| 6 | 6 | 14 | 6 | 1 | Grèce | Tau |
Contact
Pour toute question, suggestions ou clarifications concernant ces ressources, vous pouvez contacter les auteurs par les moyens suivants:
María Elena
Jordan Joel
À propos des auteurs
- María Elena Martínez-Manzanares est titulaire d'un baccalauréat en mathématiques obtenu en 2018 de l'Université de Sonora (Mexique), et un baccalauréat en éducation en mathématiques obtenue en 2023 de l'Universidad Abierta Ya Distancia de México. En 2019, elle a obtenu un MSC en mathématiques de l'Universidad de Sonora. Actuellement, elle termine un doctorat. à Universidad de Sonora, concentrant son travail sur la zone de contrôle stochastique. Elle est sur le point de conclure son deuxième MSC en science des données dans la même université avec un accent sur la région de la PNL. Elle possède une expérience de recherche sur les modèles théoriques markoviens et semi-markoviens et les problèmes utilisant des méthodes mixtes dans différents domaines de l'enseignement des mathématiques et des mathématiques appliqués. Elle a travaillé comme scientifique des données dans le secteur télématique.
- Jordan Joel Urias Paramo est titulaire d'un baccalauréat en informatique, obtenu en 2019 de l'Universidad de Sonora (Mexique). Il travaille actuellement en tant qu'ingénieur de données et est étudiant en maîtrise en sciences des données à l'Universidad de Sonora.
- Julio Wissman-Vilanova a un doctorat. dans les systèmes automatiques de l'Institut National Polytechnique de Toulouse (France). Il est professeur titulaire à Universidad de Sonora, au Mexique, et ses intérêts de recherche actuels incluent le traitement d'image, la reconnaissance des modèles et la PNL.
- Gudelia Figueroa-Preciado a un doctorat. en mathématiques de l'Universidad de Sonora (Mexique). Elle est professeure titulaire à Universidad de Sonora, au Mexique, et ses intérêts de recherche actuels comprennent des méthodes d'échantillonnage, des conceptions expérimentales, des statistiques inférentielles.
Remerciements
Nous voulons reconnaître les personnes suivantes pour leurs précieuses contributions à ce travail:
- doctorat Cipriano Arturo Santos-Borbolla et MBA Francisco Enrique Andrade-López du Group d'opérations artificielles (Oper.ai) à l'Instituto Tecnológico y De Estudios Superiores de Monterrey (Mexique);
- Evelyn Mercedes Medina-García du programme de maîtrise en sciences sociales à l'Universidad de Sonora (Mexique);
- doctorat Ramón Soto de la Cruz et Francisco Alejandro Bernal-Cañez du Département de mathématiques de l'Universidad de Sonora (Mexique);
- M.Sc. Irenisolina Antelo-López du programme de doctorat en sciences avec une spécialisation en mathématiques éducatives à l'Université de Sonora (Mexique);
- Informaticien, Luis Fernando Sotomayor-Samaniego.
Merci de votre intérêt pour cette recherche.


