youtube auto dub
1.0.0
该存储库是通过使用OpenVoice捕获和推断语音音色来开发FastAPI后端来配音YouTube视频的起点。
fastapi-cloudrun-Starter
要开始使用YouTube Auto-Dub,请按照以下步骤:
对于本地开发,我们建议通过以下方式建立一个Conda环境
conda install mamba -n base -c conda-forge
mamba create -n youtube-auto-dub python=3.9 -y
mamba install -n youtube-auto-dub pytorch==1.13.1 torchvision==0.14.1 torchaudio==0.13.1 pytorch-cuda=11.7 -c pytorch -c nvidia -y
conda activate youtube-auto-dub
pip install -r requirements.txt下载语音音色识别和综合所需的模型检查点:
sudo aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://myshell-public-repo-hosting.s3.amazonaws.com/checkpoints_1226.zip -d /code -o checkpoints_1226.zip
sudo unzip /code/checkpoints_1226.zip -d backend/checkpoints设置环境并下载了检查点,请导航到后端目录并使用以下方式启动应用程序:
cd backend
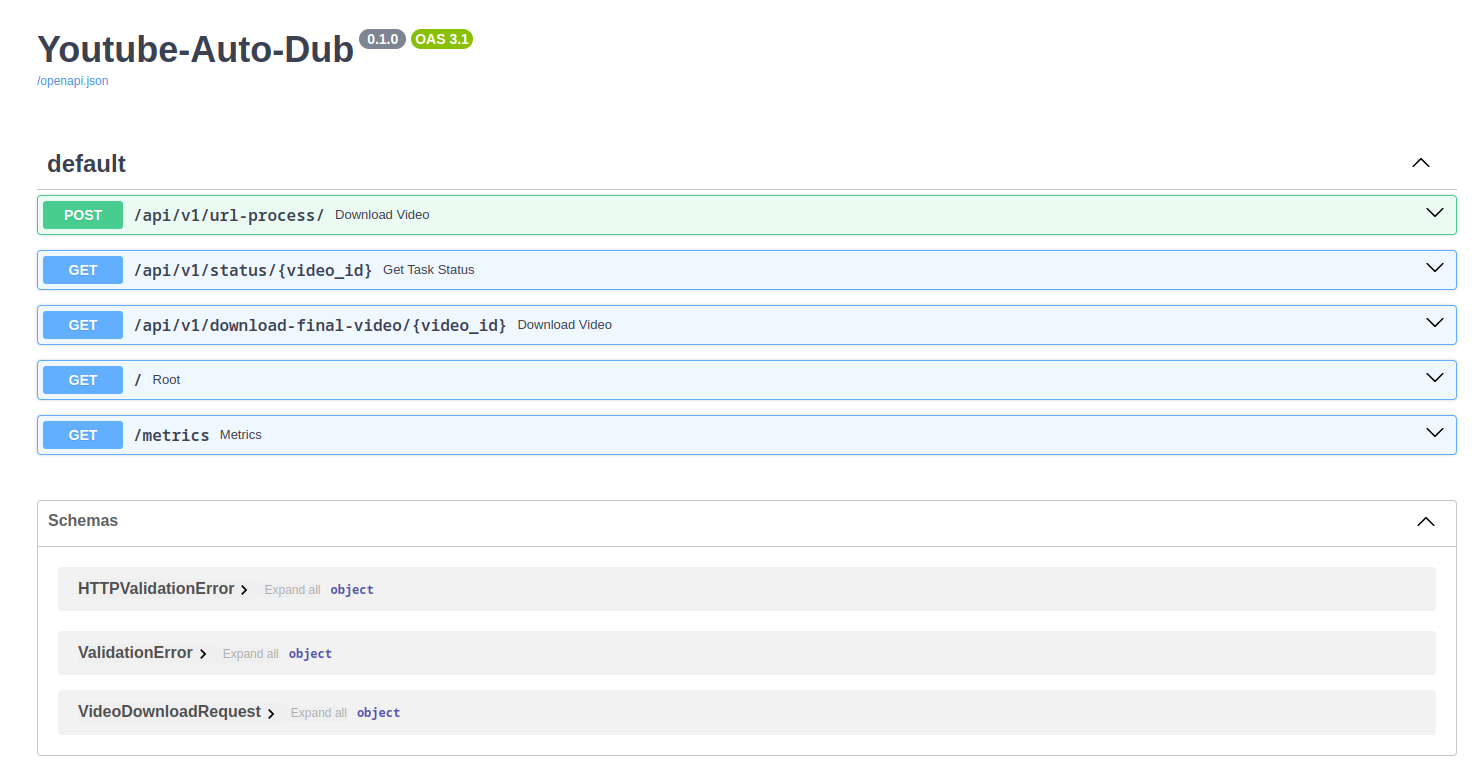
uvicorn app.main:app --reload要使用YouTube Auto-Dub,请首先通过端点提交YouTube链接:
/api/v1/download/
该应用程序将处理视频,识别语音音色,翻译字幕,合成与原始音色匹配的翻译语音,然后组装最终视频。处理后的视频将保存在backend/data/final_videos中。随着输出中的视频ID返回,您可以通过端点检查处理状态:
/api/v1/status/{video_id}
最后,您可以使用端点下载最终视频:
/api/v1/download-video/{video_id}
插入视频的ID。
该项目的设计考虑了云部署。提供的cloudbuild.yaml和Terraform配置有助于在Google Cloud Platform上部署,专门使用云运行用于可扩展的无服务器应用程序托管。
欢迎捐款!无论您是修复错误,添加新功能还是改进文档,您的帮助都将受到赞赏。请随时订购存储库并提交拉动请求。
YouTube Auto-Dub的开发受到以下存储库的启发:
该项目是根据MIT许可证获得许可的 - 有关详细信息,请参见许可证文件。


