PPO PyTorch
1.0.0
action_std添加了线性衰减;使培训在复杂环境中更稳定.csv文件,情节,时间段和奖励现在已登录PPO_colab.ipynb组合所有文件 /测试 /绘图图 /在Google colab上制作gifs的文件PPO_colab.ipynb 该存储库提供了最小的Pytorch近端策略优化(PPO),并为OpenAI Gym环境提供了剪辑的目标。它主要用于加强学习PPO算法的初学者。它仍然可以用于复杂的环境,但可能需要一些高参数调整或代码更改。可以在此处找到PPO算法的简要解释,并且可以在此处找到实施最佳性能PPO的所有细节的详尽解释(所有这些都尚未在此存储库中实施)。
保持训练程序的简单:
train.pytest.pyplot_graph.pymake_gif.py.py文件中PPO_colab.ipynb结合了jupyter音符中的所有文件README.md中列出如果您想在出版物中引用此存储库,请使用此Bibtex:
@misc{pytorch_minimal_ppo,
author = {Barhate, Nikhil},
title = {Minimal PyTorch Implementation of Proximal Policy Optimization},
year = {2021},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/nikhilbarhate99/PPO-PyTorch}},
}
| PPO连续的Roboschoolhalfcheetah-V1 | PPO连续的Roboschoolhalfcheetah-V1 |
|---|---|
 | 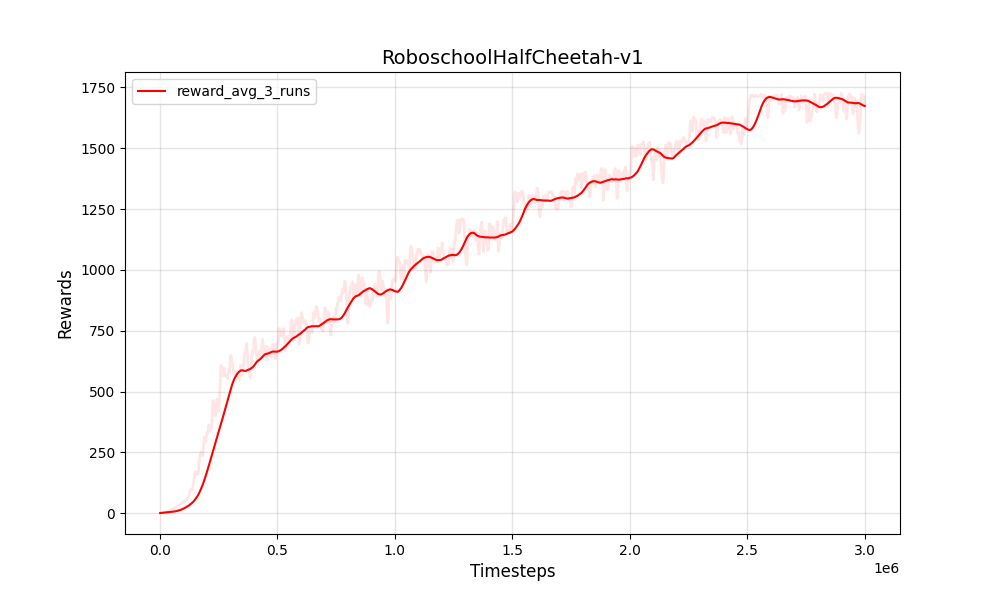 |
| PPO连续roboschoolhopper-v1 | PPO连续roboschoolhopper-v1 |
|---|---|
 | 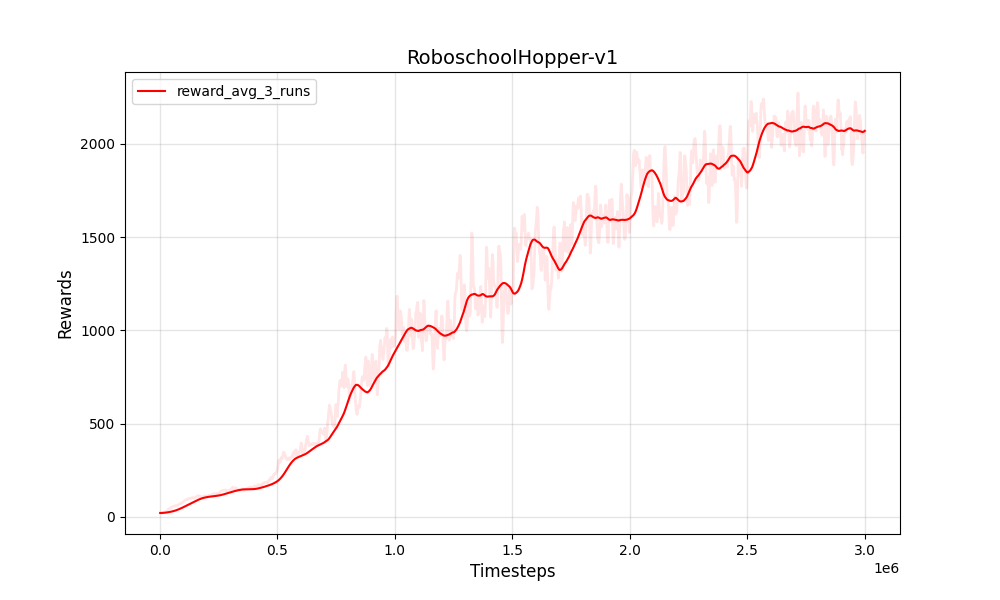 |
| PPO连续roboschoolwalker2d-v1 | PPO连续roboschoolwalker2d-v1 |
|---|---|
 | 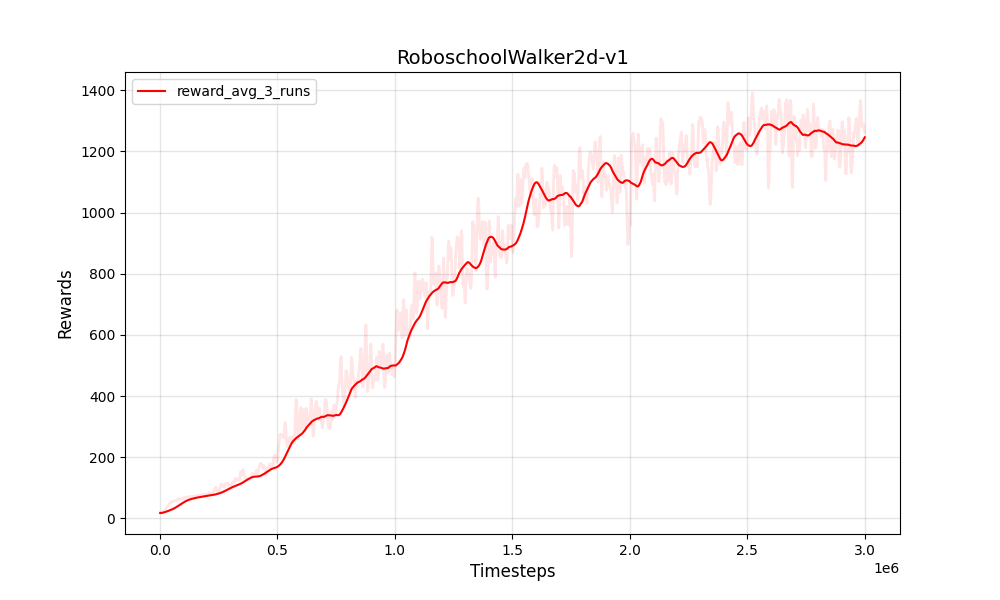 |
| PPO连续BipedalWalker-V2 | PPO连续BipedalWalker-V2 |
|---|---|
 | 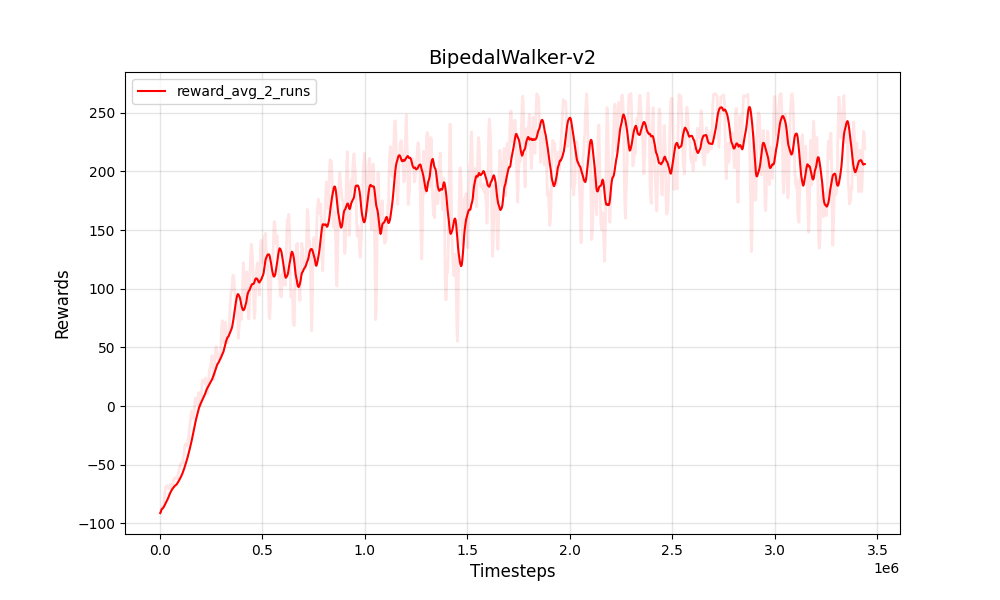 |
| PPO离散Cartpole-V1 | PPO离散Cartpole-V1 |
|---|---|
 | 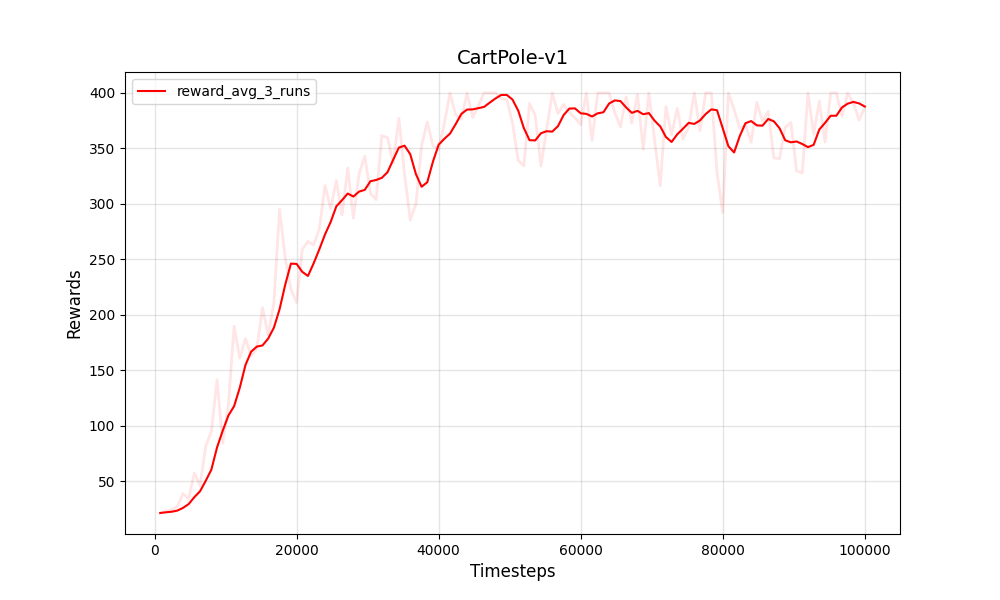 |
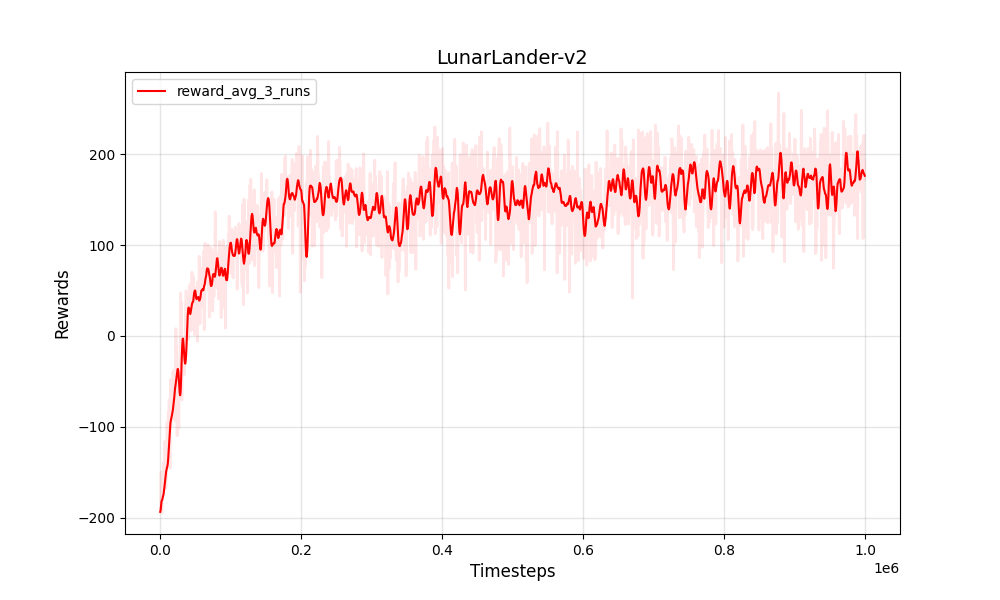
| PPO离散Lunarlander-V2 | PPO离散Lunarlander-V2 |
|---|---|
 |  |
经过培训和测试:
Python 3
PyTorch
NumPy
gym
培训环境
Box-2d
Roboschool
pybullet
图和GIF
pandas
matplotlib
Pillow


