PPO PyTorch
1.0.0
action_std 에 대한 선형 붕괴가 추가되었습니다. 복잡한 환경에 대한 훈련을보다 안정적으로 만들기 위해.csv 파일로 기록됩니다.PPO_colab.ipynb 모든 파일을 교육 / 테스트 / 플롯 그래프로 결합 / 편리한 Jupyter-Notebook에서 Google Colab에서 GIF를 만듭니다. PPO_colab.ipynb 엽니 다 이 저장소는 OpenAI 체육관 환경을위한 클리핑 목표를 가진 PPO (Plifal Policy Optimization)의 최소 Pytorch 구현을 제공합니다. 주로 PPO 알고리즘을 이해하기위한 강화 학습 초보자를위한 것입니다. 여전히 복잡한 환경에 사용될 수 있지만 일부 초 파라미터 조정 또는 코드 변경이 필요할 수 있습니다. PPO 알고리즘에 대한 간결한 설명은 여기에서 찾을 수 있으며 최상의 성능 PPO를 구현하기위한 모든 세부 사항에 대한 철저한 설명은 여기에서 찾을 수 있습니다 (모두이 리포지토리에서는 구현되지 않았습니다).
훈련 절차를 간단하게 유지하려면 :
train.py 실행하십시오test.py 실행하십시오plot_graph.pymake_gif.py.py 파일에 있습니다.PPO_colab.ipynb Jupyter-Notebook의 모든 파일을 결합합니다README.md 에 나열되어 있습니다. 출판물 에서이 저장소를 인용하려면이 Bibtex를 사용하십시오.
@misc{pytorch_minimal_ppo,
author = {Barhate, Nikhil},
title = {Minimal PyTorch Implementation of Proximal Policy Optimization},
year = {2021},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/nikhilbarhate99/PPO-PyTorch}},
}
| PPO 연속 Roboschoolhalfcheetah-v1 | PPO 연속 Roboschoolhalfcheetah-v1 |
|---|---|
 | 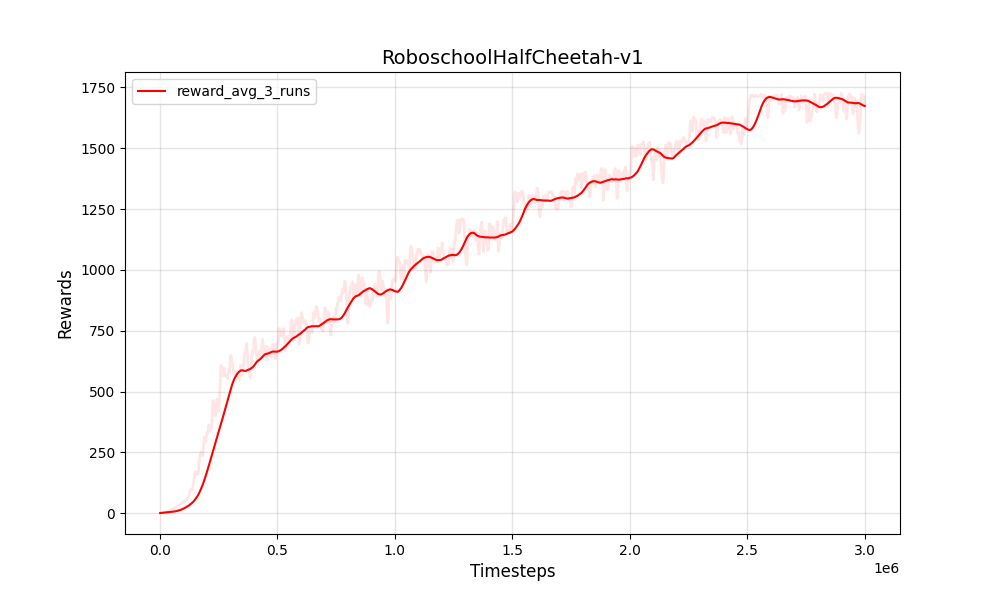 |
| PPO 연속 Roboschoolhopper-V1 | PPO 연속 Roboschoolhopper-V1 |
|---|---|
 | 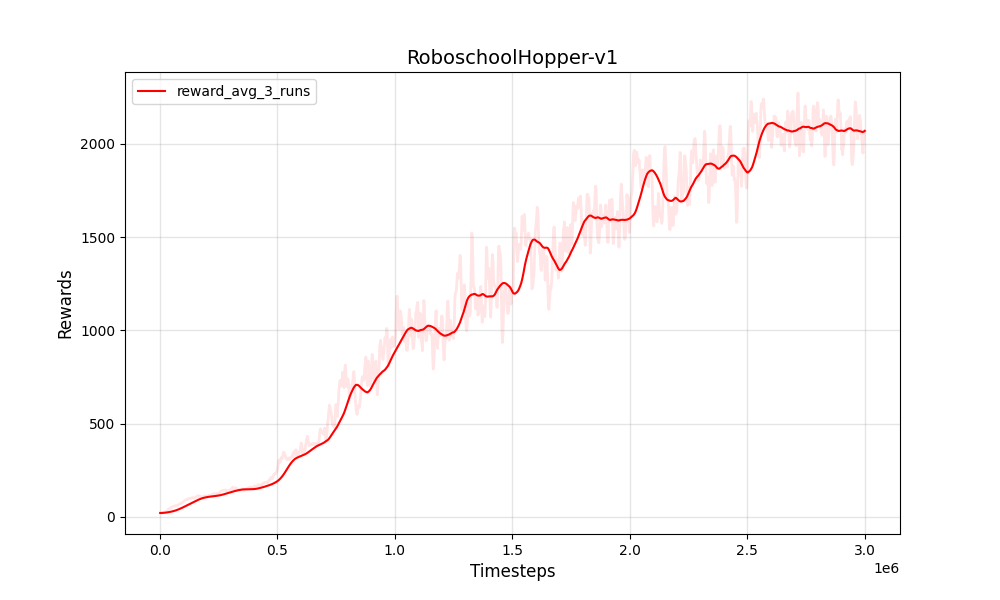 |
| PPO 연속 Roboschoolwalker2D-V1 | PPO 연속 Roboschoolwalker2D-V1 |
|---|---|
 | 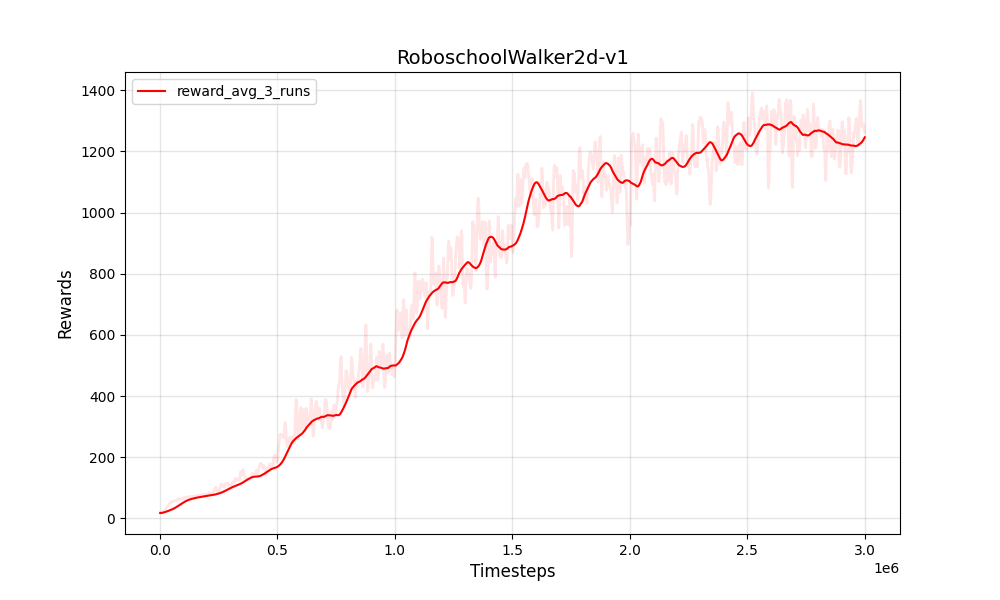 |
| PPO 연속 Bipedalwalker-V2 | PPO 연속 Bipedalwalker-V2 |
|---|---|
 | 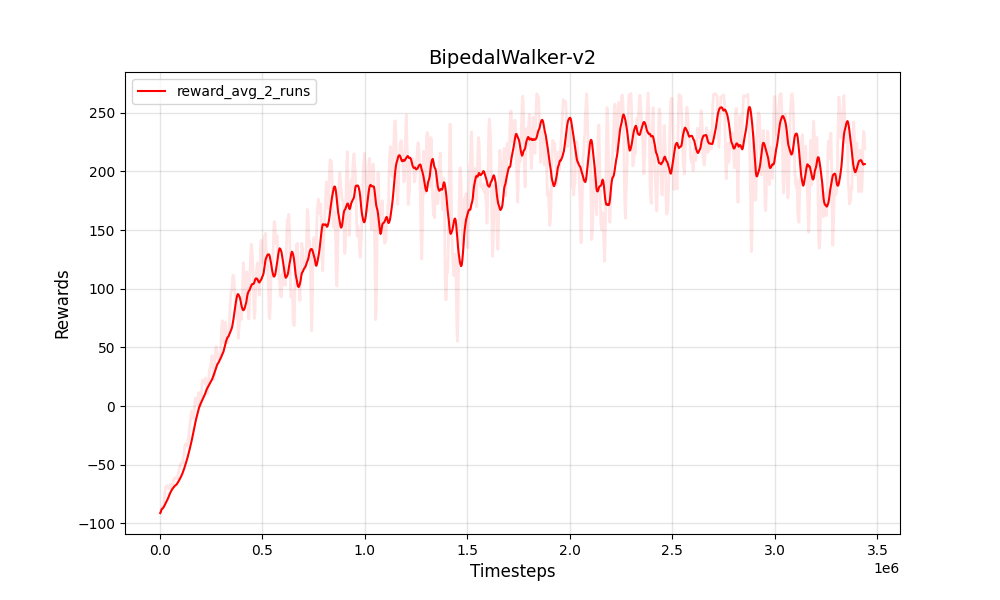 |
| PPO 이산 카트 폴 -V1 | PPO 이산 카트 폴 -V1 |
|---|---|
 | 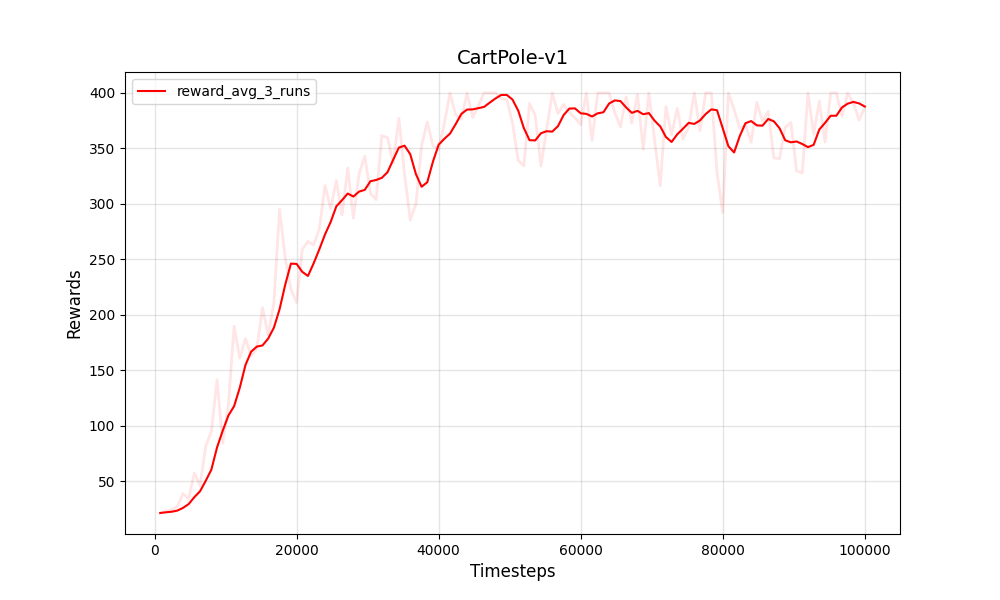 |
| PPO 이산 Lunarlander-V2 | PPO 이산 Lunarlander-V2 |
|---|---|
 | 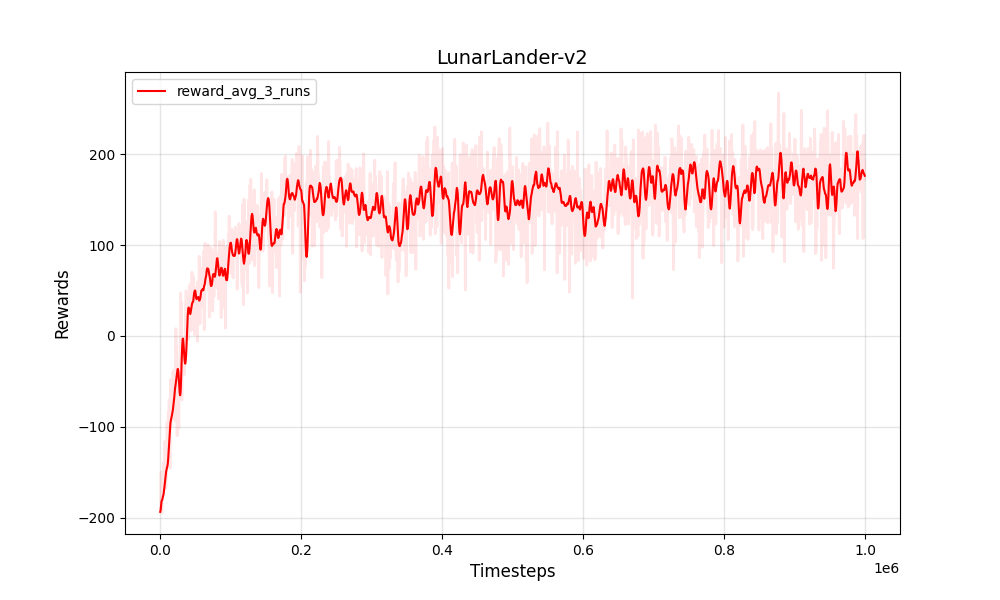 |
교육 및 테스트 :
Python 3
PyTorch
NumPy
gym
훈련 환경
Box-2d
Roboschool
pybullet
그래프 및 gif
pandas
matplotlib
Pillow


