PPO PyTorch
1.0.0
action_std ؛ لجعل التدريب أكثر استقرارًا للبيئات المعقدة.csvPPO_colab.ipynb دمج جميع الملفات لتدريب / اختبار / رسم الرسوم البيانية / صنع صور GIF على Google Colab في كتاب jupyter-notebook مناسب PPO_colab.ipynb في Google Colab يوفر هذا المستودع الحد الأدنى من تنفيذ Pytorch لتحسين السياسة القريبة (PPO) مع الهدف المقطوع لبيئات صالة الألعاب الرياضية Openai. إنه مخصص في المقام الأول للمبتدئين في التعلم التعزيز لفهم خوارزمية PPO. لا يزال من الممكن استخدامه للبيئات المعقدة ولكن قد يتطلب بعض التثبيت أو التغييرات في الكود. يمكن العثور على شرح موجز لخوارزمية PPO هنا ويمكن العثور على شرح شامل لجميع التفاصيل لتنفيذ أفضل PPO أداءً هنا (لا يتم تنفيذها في هذا الريبو بعد).
للحفاظ على إجراء التدريب بسيط:
train.pytest.pyplot_graph.pymake_gif.py.py للتحكمPPO_colab.ipynb بين جميع الملفات الموجودة في جيبتر نوتREADME.md يرجى استخدام هذا bibtex إذا كنت تريد الاستشهاد بهذا المستودع في منشوراتك:
@misc{pytorch_minimal_ppo,
author = {Barhate, Nikhil},
title = {Minimal PyTorch Implementation of Proximal Policy Optimization},
year = {2021},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/nikhilbarhate99/PPO-PyTorch}},
}
| PPO المستمر roboschoolhalfchetah-v1 | PPO المستمر roboschoolhalfchetah-v1 |
|---|---|
 | 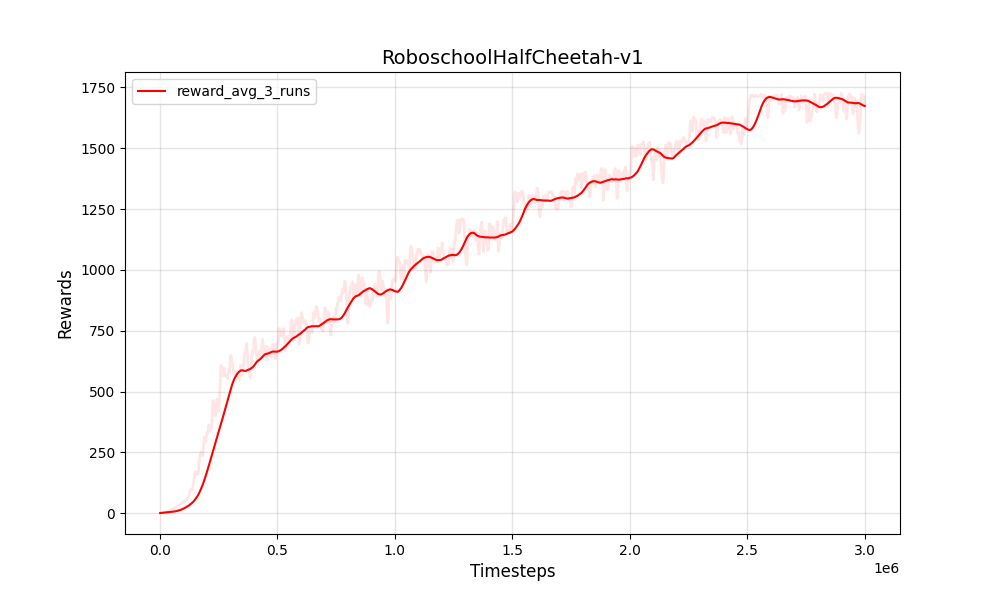 |
| PPO المستمر roboschoolhopper-V1 | PPO المستمر roboschoolhopper-V1 |
|---|---|
 | 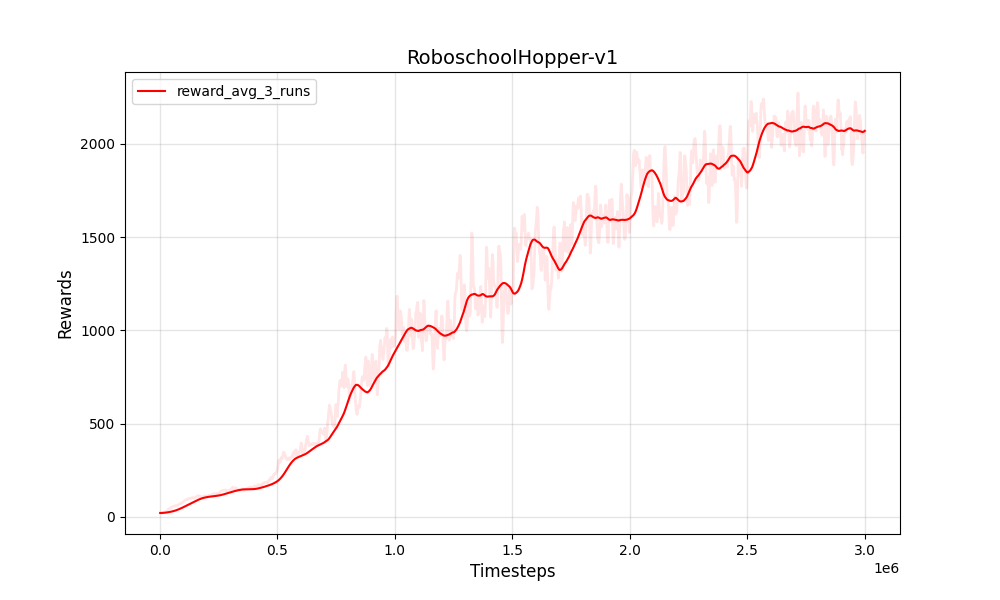 |
| PPO المستمر roboschoolwalker2d-v1 | PPO المستمر roboschoolwalker2d-v1 |
|---|---|
 | 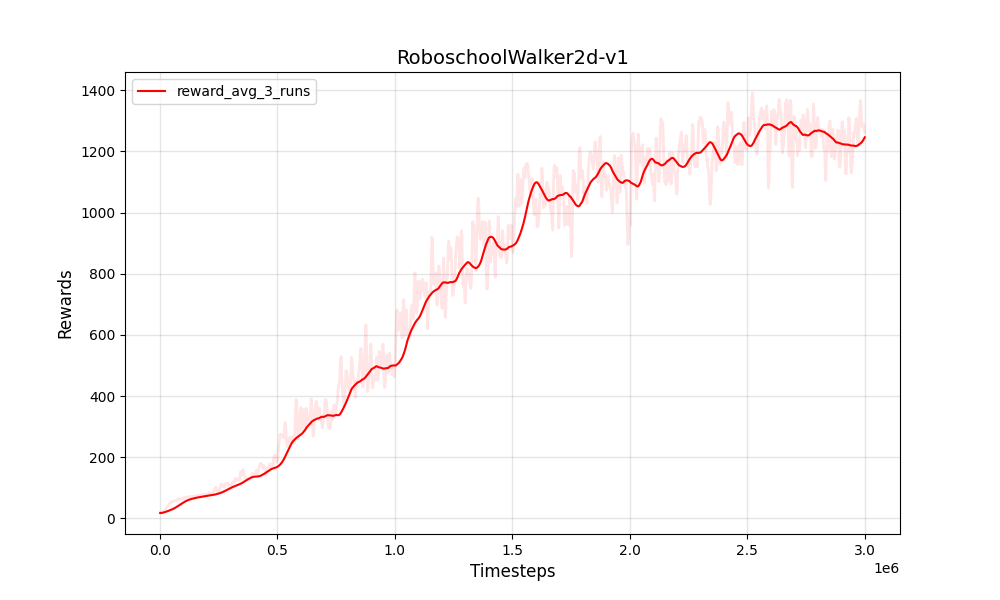 |
| PPO المستمر bipedalwalker-V2 | PPO المستمر bipedalwalker-V2 |
|---|---|
 | 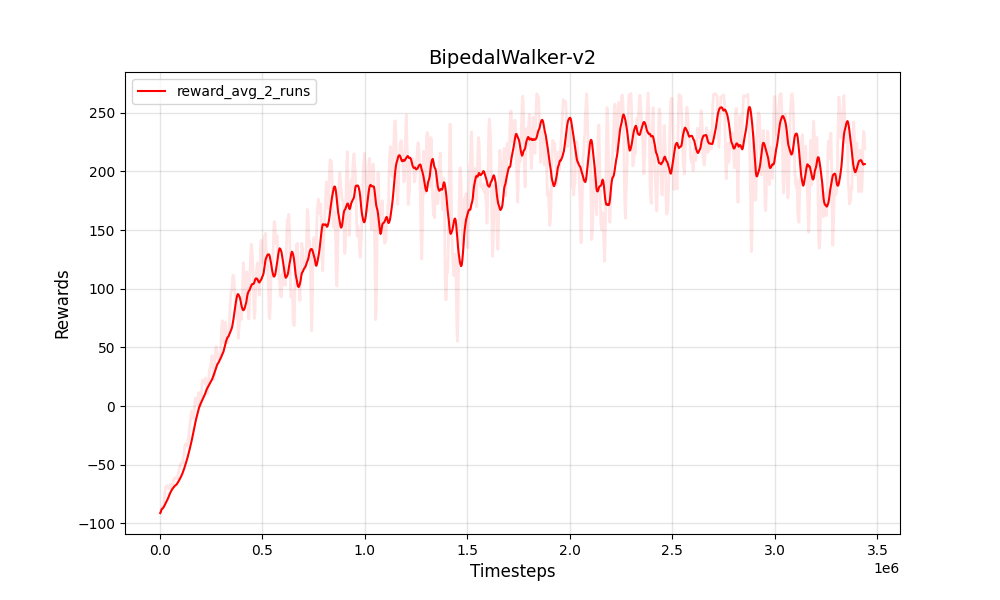 |
| PPO Cartpole-V1 | PPO Cartpole-V1 |
|---|---|
 | 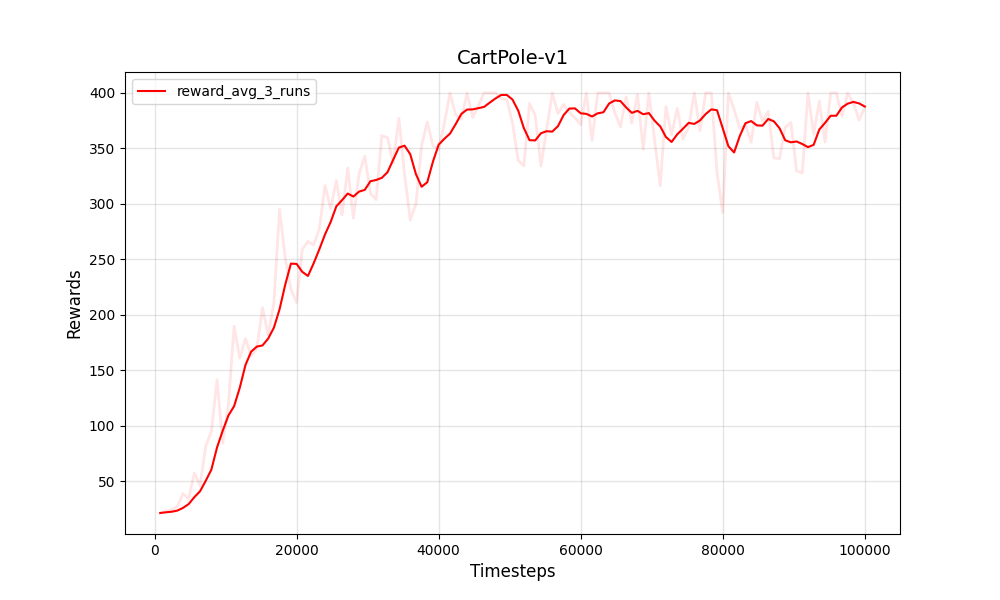 |
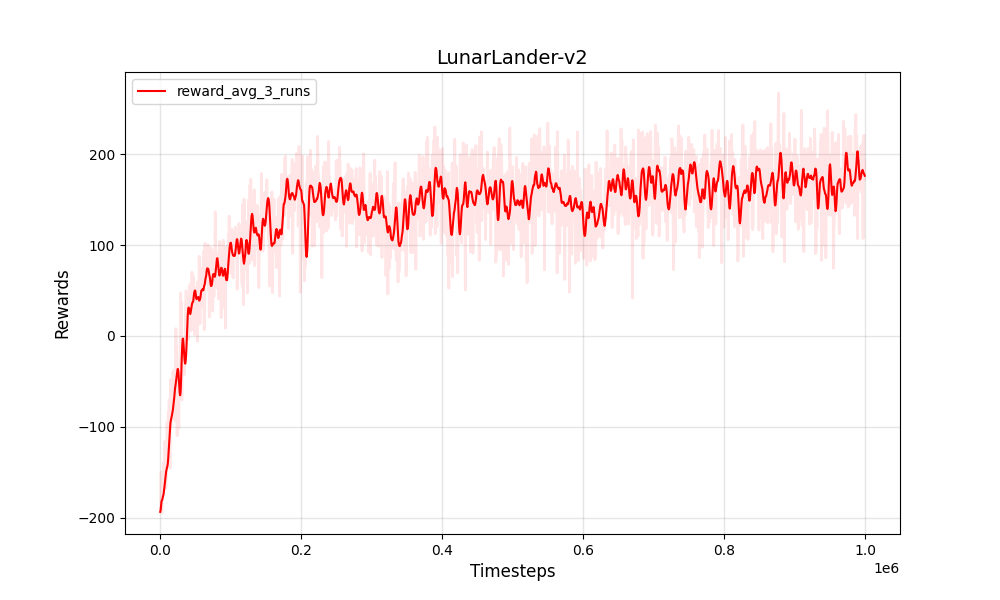
| PPO المنفصل Lunarlander-V2 | PPO المنفصل Lunarlander-V2 |
|---|---|
 |  |
تدرب واختبار على:
Python 3
PyTorch
NumPy
gym
بيئات التدريب
Box-2d
Roboschool
pybullet
الرسوم البيانية والصور المتحركة
pandas
matplotlib
Pillow


