PPO PyTorch
1.0.0
action_stdに線形減衰が追加されました。複雑な環境のトレーニングをより安定させるため.csvファイルに記録されるようになりましたPPO_colab.ipynbすべてのファイルを組み合わせて、グラフをトレーニング /テスト /プロットする / GoogleコラブでGIFをトレーニング /テスト /プロットします。 PPO_colab.ipynbを開きますこのリポジトリは、OpenAIジム環境の目標が切り取られた近位政策最適化(PPO)の最小限のPytorch実装を提供します。これは主に、PPOアルゴリズムを理解するための補強学習の初心者向けです。複雑な環境には使用できますが、ハイパーパラメーター調整またはコードの変更が必要になる場合があります。 PPOアルゴリズムの簡潔な説明はここにあり、最高のパフォーマンスPPOを実装するためのすべての詳細の徹底的な説明がここにあります(すべてこのレポではすべて実装されていません)。
トレーニング手順を簡単に保つには:
train.pytest.pyを実行しますplot_graph.pyを実行しますmake_gif.py.pyファイルにありますPPO_colab.ipynb 、jupyter-notebookのすべてのファイルを組み合わせていますREADME.mdにリストされています出版物でこのリポジトリを引用したい場合は、このbibtexを使用してください。
@misc{pytorch_minimal_ppo,
author = {Barhate, Nikhil},
title = {Minimal PyTorch Implementation of Proximal Policy Optimization},
year = {2021},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/nikhilbarhate99/PPO-PyTorch}},
}
| PPO連続Roboschoolhalfcheetah-v1 | PPO連続Roboschoolhalfcheetah-v1 |
|---|---|
 | 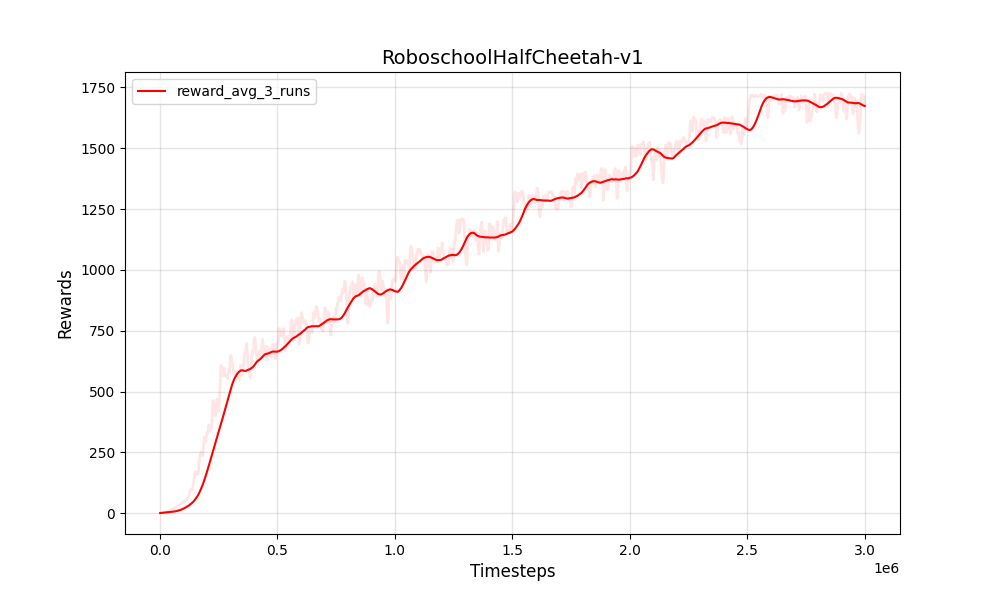 |
| PPO連続ROBOSCHOOLHOPPER-V1 | PPO連続ROBOSCHOOLHOPPER-V1 |
|---|---|
 | 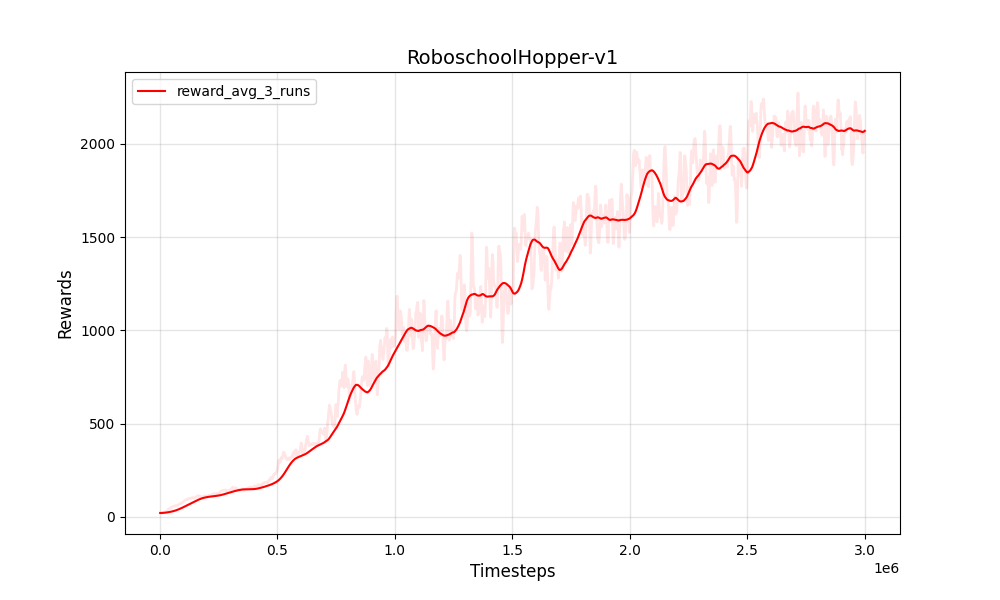 |
| PPO連続ROBOSCHOOLWALKER2D-V1 | PPO連続ROBOSCHOOLWALKER2D-V1 |
|---|---|
 | 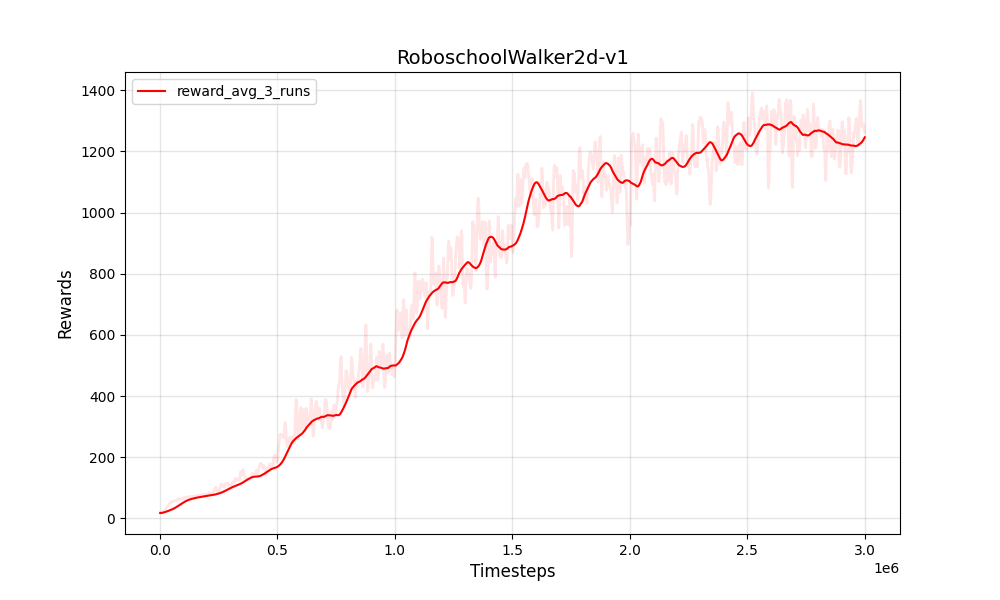 |
| PPO連続二足骨walker-v2 | PPO連続二足骨walker-v2 |
|---|---|
 | 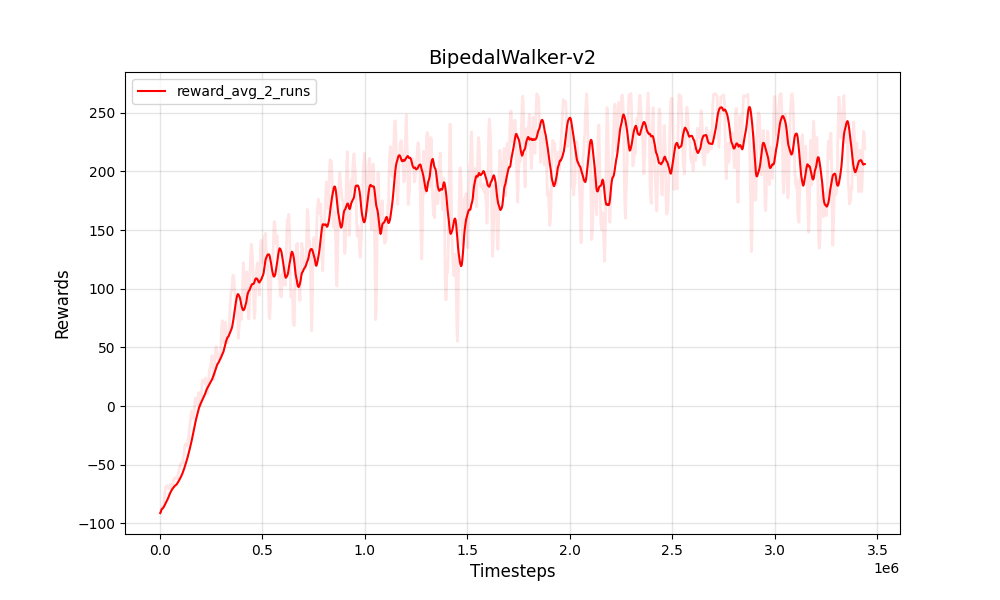 |
| PPO離散カートポール-V1 | PPO離散カートポール-V1 |
|---|---|
 | 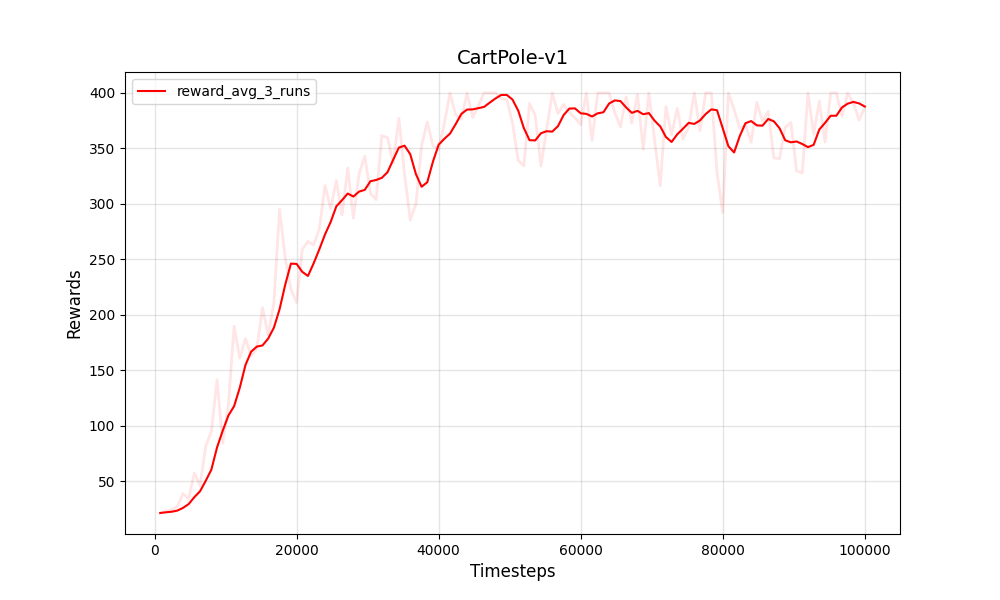 |
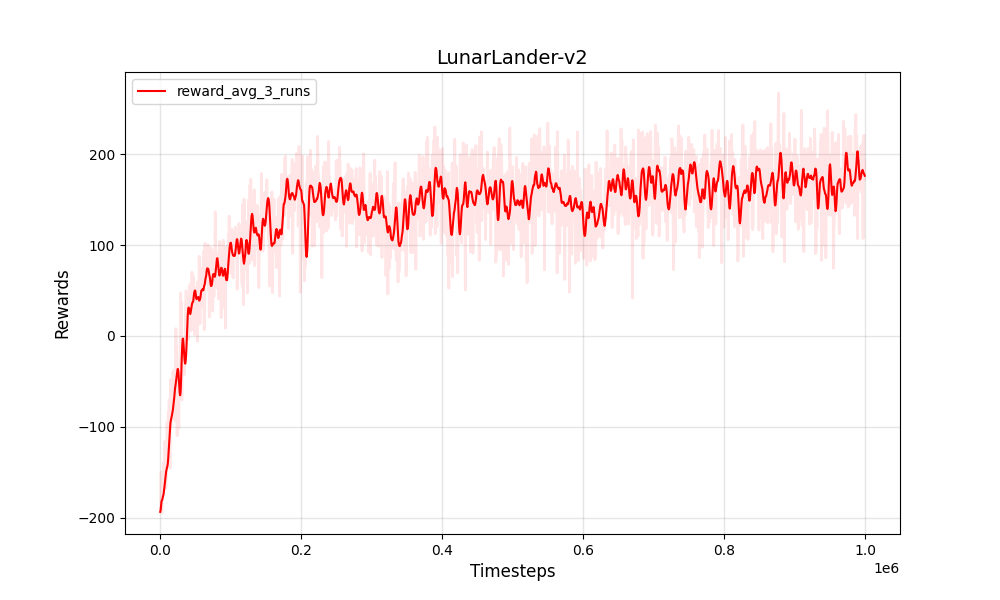
| PPO離散Lunarlander-V2 | PPO離散Lunarlander-V2 |
|---|---|
 |  |
トレーニングとテスト:
Python 3
PyTorch
NumPy
gym
トレーニング環境
Box-2d
Roboschool
pybullet
グラフとGIF
pandas
matplotlib
Pillow


