document retrieval caching
1.0.0
建立一个通过缓存的文档检索的后端。
缓存算法在服务器中创建了一个队列,该队列将从以前的Quries中存储从向量数据库中存储有限数量的节点。对于来自用户的每个查询,首先将与队列中的查询匹配,如果相似性(cesine)高于0.9,则比从查找表中返回的那些节点分开保持。
第一个请求=>花费时间787 ms 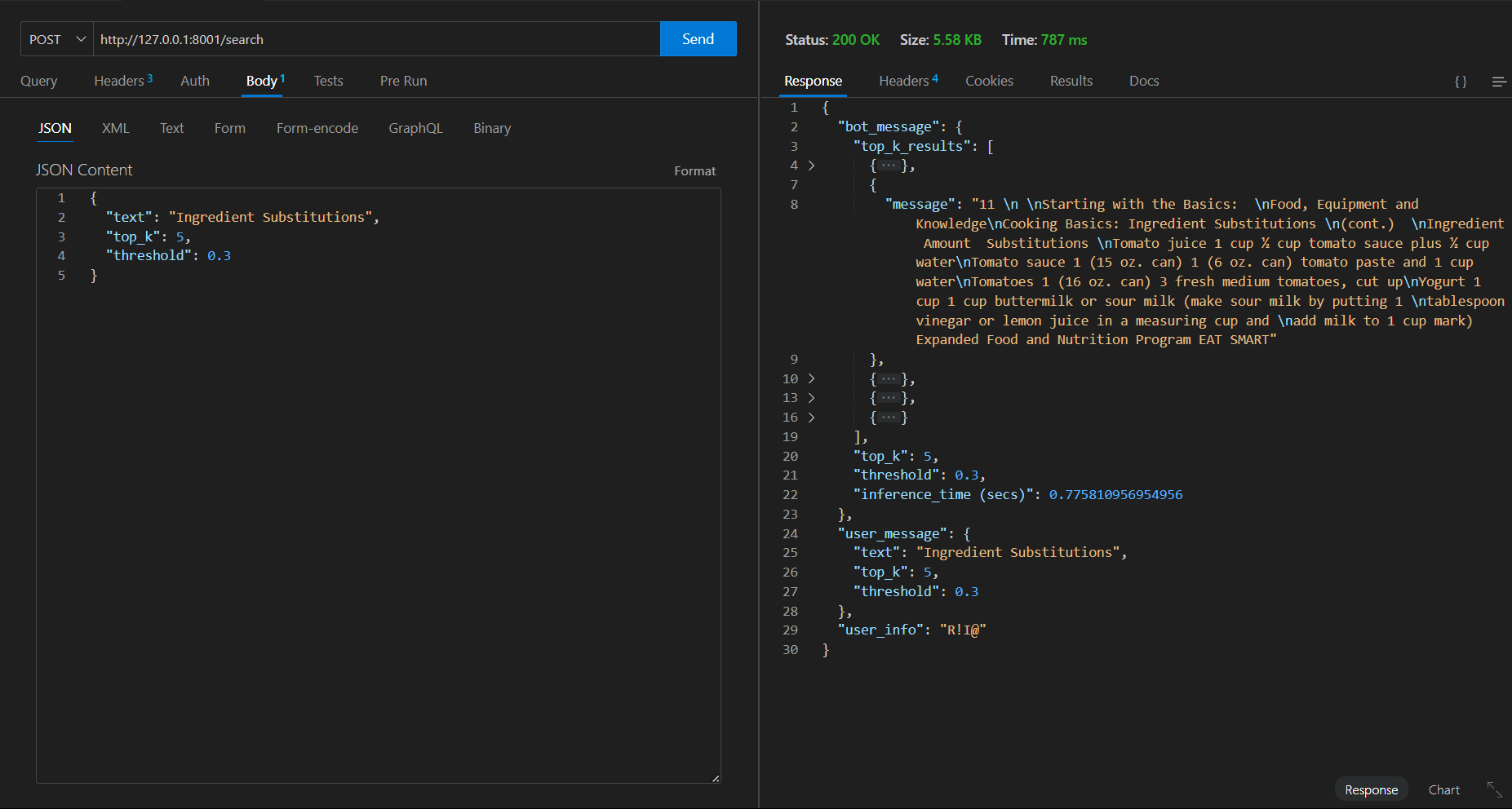
第二个类似请求=>花费的时间为54 ms 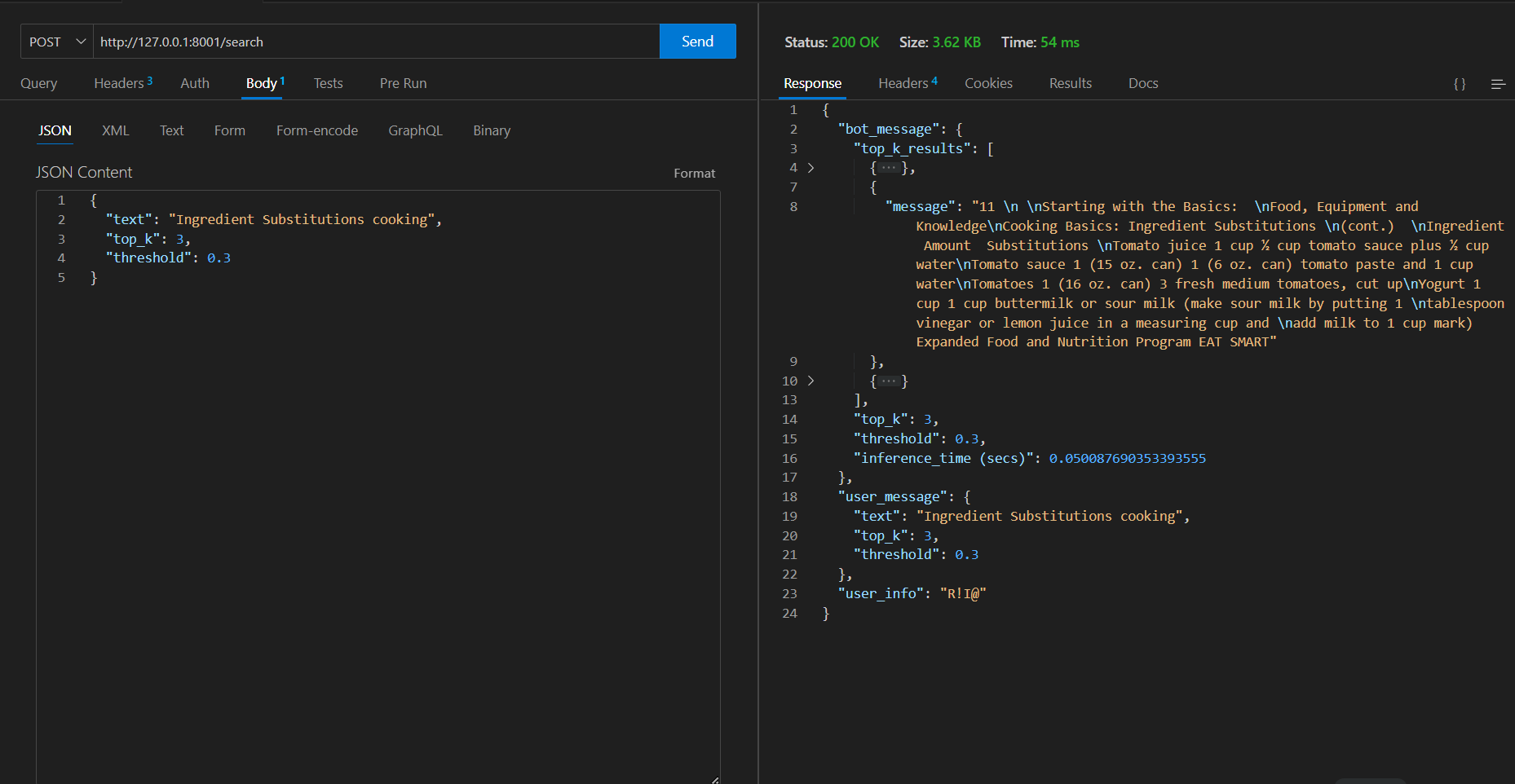
错误的请求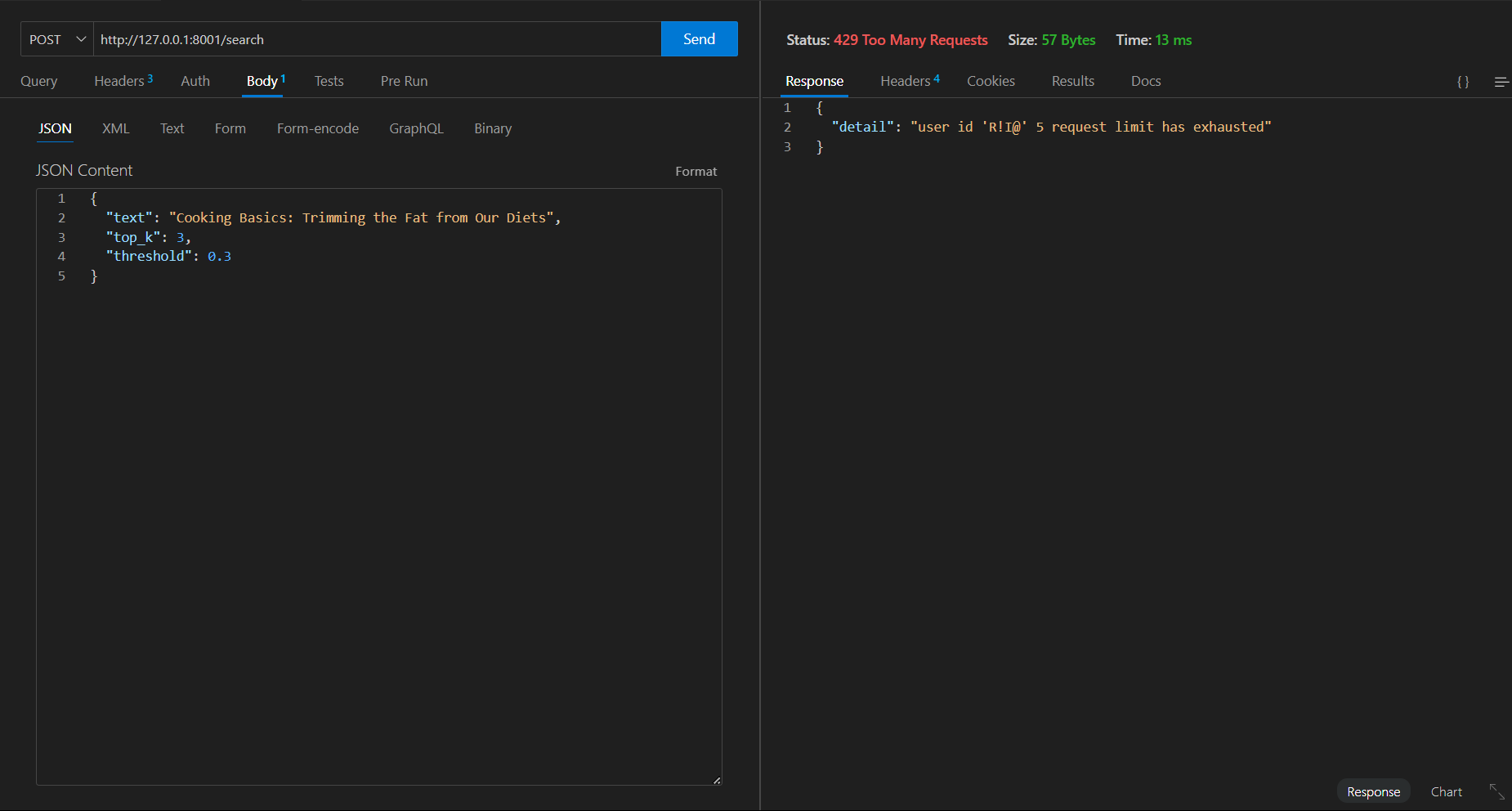
健康检查端点
curl --location ' localhost:8001/health '搜索检查端点
curl --location ' localhost:8001/search ' --header ' user_id: riondsilva ' --header ' Content-Type: application/json ' --data ' { "text": "Ingredient Substitutions" , "top_k": 5 , "threshold": 0.3 } '*按顺序运行
色度图像
docker run -p 8000:8000 chromadb/chromaPostgres图像
docker run --name user-database -p 5432:5432
-e POSTGRES_PASSWORD=your_password -d postgres:12.20-alpine3.20 docker stop user-database文档取回
git clone https://github.com/RionDsilvaCS/document-retrieval-caching.git在主目录中创建.env文件并添加以下变量
DATABASE_URL="postgresql://postgres:your_password@localhost:5432/postgres"
COLLECTION_NAME="collection_name"
创建目录名称data并添加PDF文档
mkdir data
运行store_in_db.py以将./data内容保存到chromadb
python store_in_db.pydocker compose up --build/health是终点以检查服务器是否启动
端点
http://127.0.0.1:8001/health
回复
{
"Server Status" : " Successfully running ? "
} /search是与聊天机器人交谈的帖子端点
端点
http://127.0.0.1:8001/search
标题
{
"user_id" : " riondsilva "
}json身体
{
"text" : " How are you? " ,
"top_k" : 3 ,
"threshold" : 0.3
}回复
{
"bot_message" : {
"top_k_results" : [
{
"message" : " I am great ? "
},
{
"message" : " I am fine "
},
{
"message" : " I am good "
}
],
"top_k" : 3 ,
"threshold" : 0.9
},
"user_message" : {
"text" : " How are you? " ,
"top_k" : 3 ,
"threshold" : 0.9 ,
"inference_time (secs)" : 1.16
},
"user_info" : " riondsilva "
}

