document retrieval caching
1.0.0
캐싱으로 문서 검색을위한 백엔드를 구축하십시오.
캐싱 알고리즘은 서버에서 큐를 생성하여 이전 Quries의 벡터 데이터베이스에서 제한된 수의 노드를 저장합니다. 사용자의 모든 쿼리마다 먼저 큐의 Queries와 일치하며 유사성 (코사인)이 룩업 테이블에서 다시 반환 된 노드보다 유사성 (코사인)이 0.9 이상인 경우 별도로 유지 관리됩니다.
첫 번째 요청 => 시간 787 ms 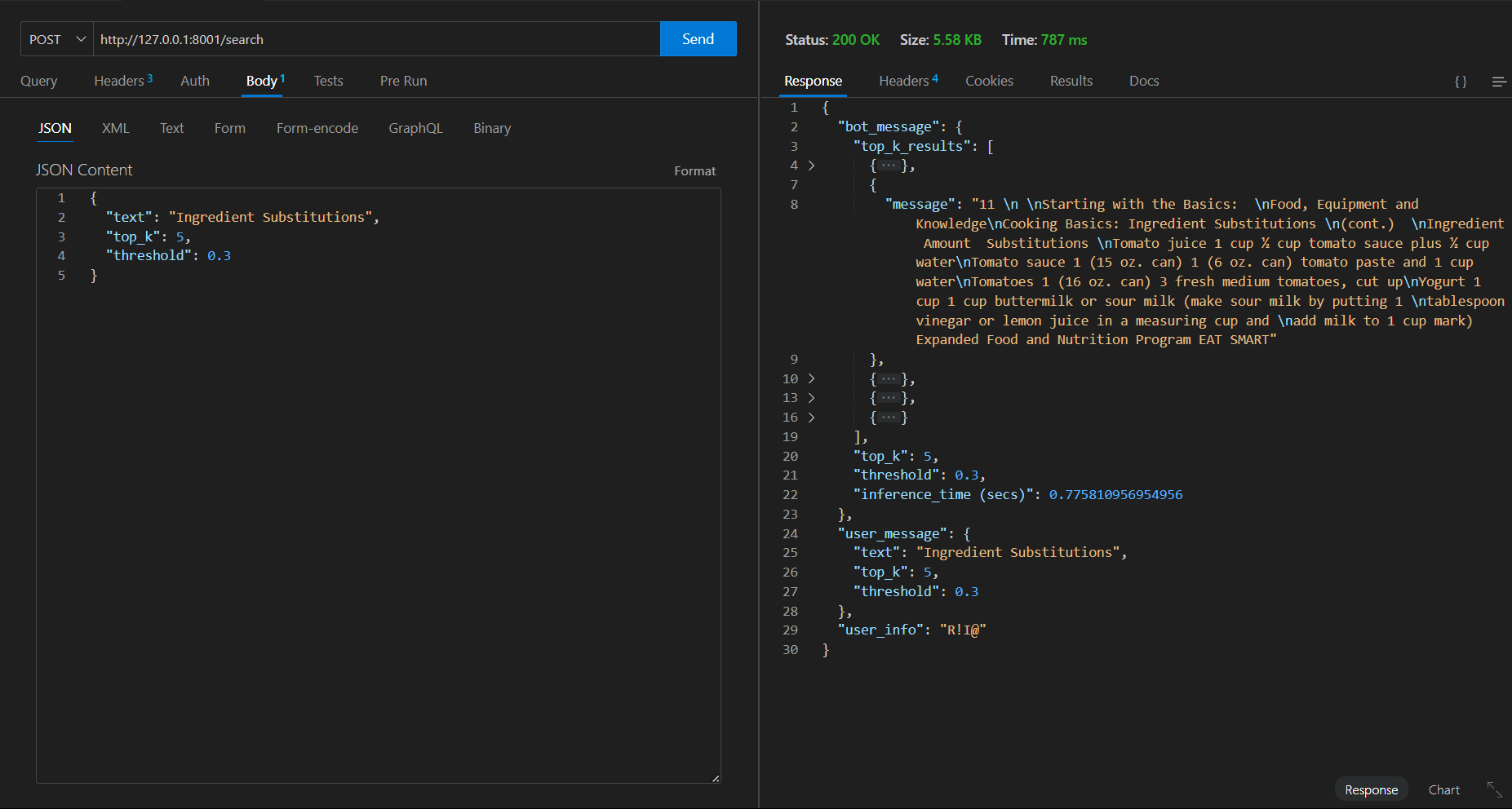
두 번째 유사한 요청 => 시간이 54 ms 에 걸렸습니다 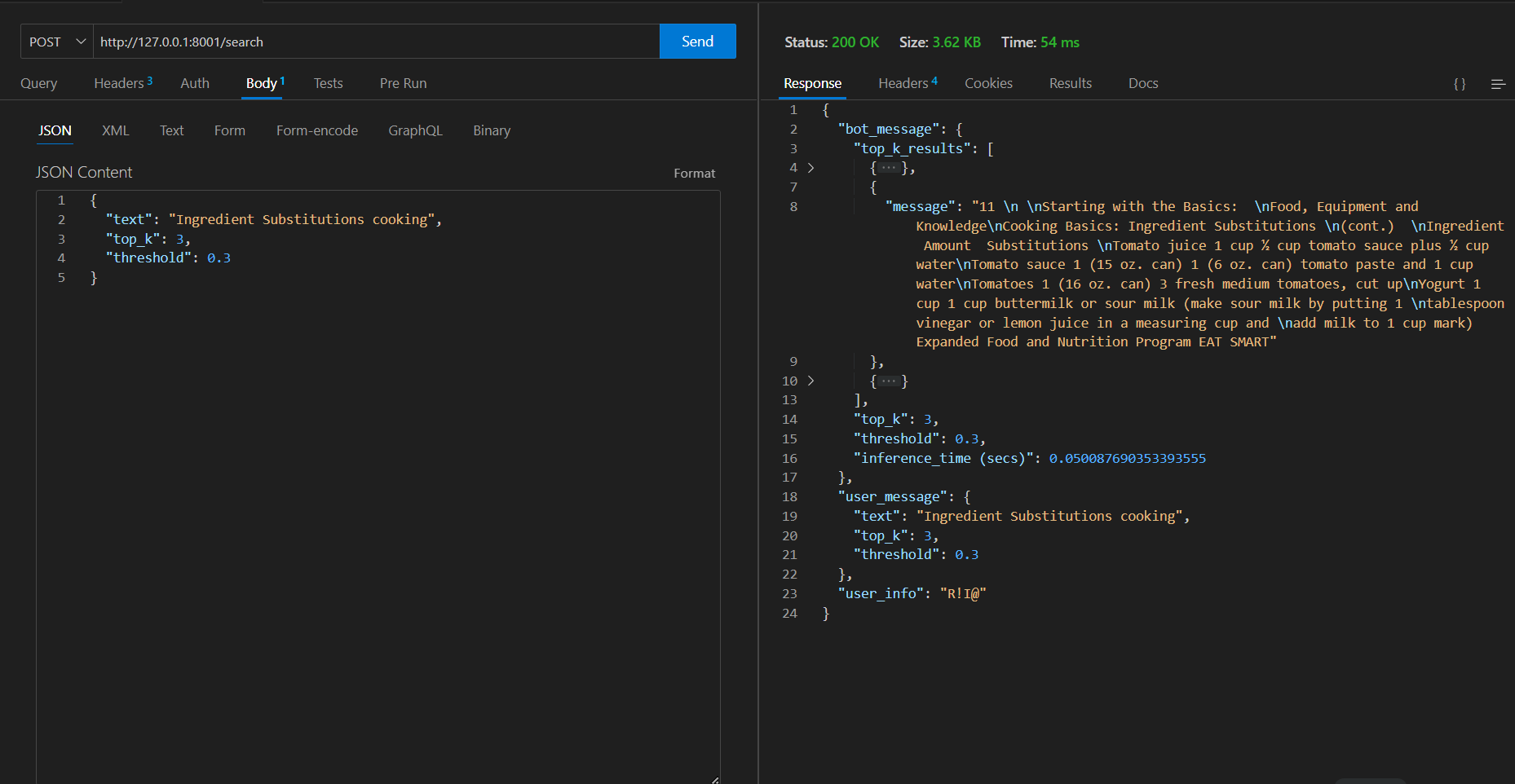
나쁜 요청 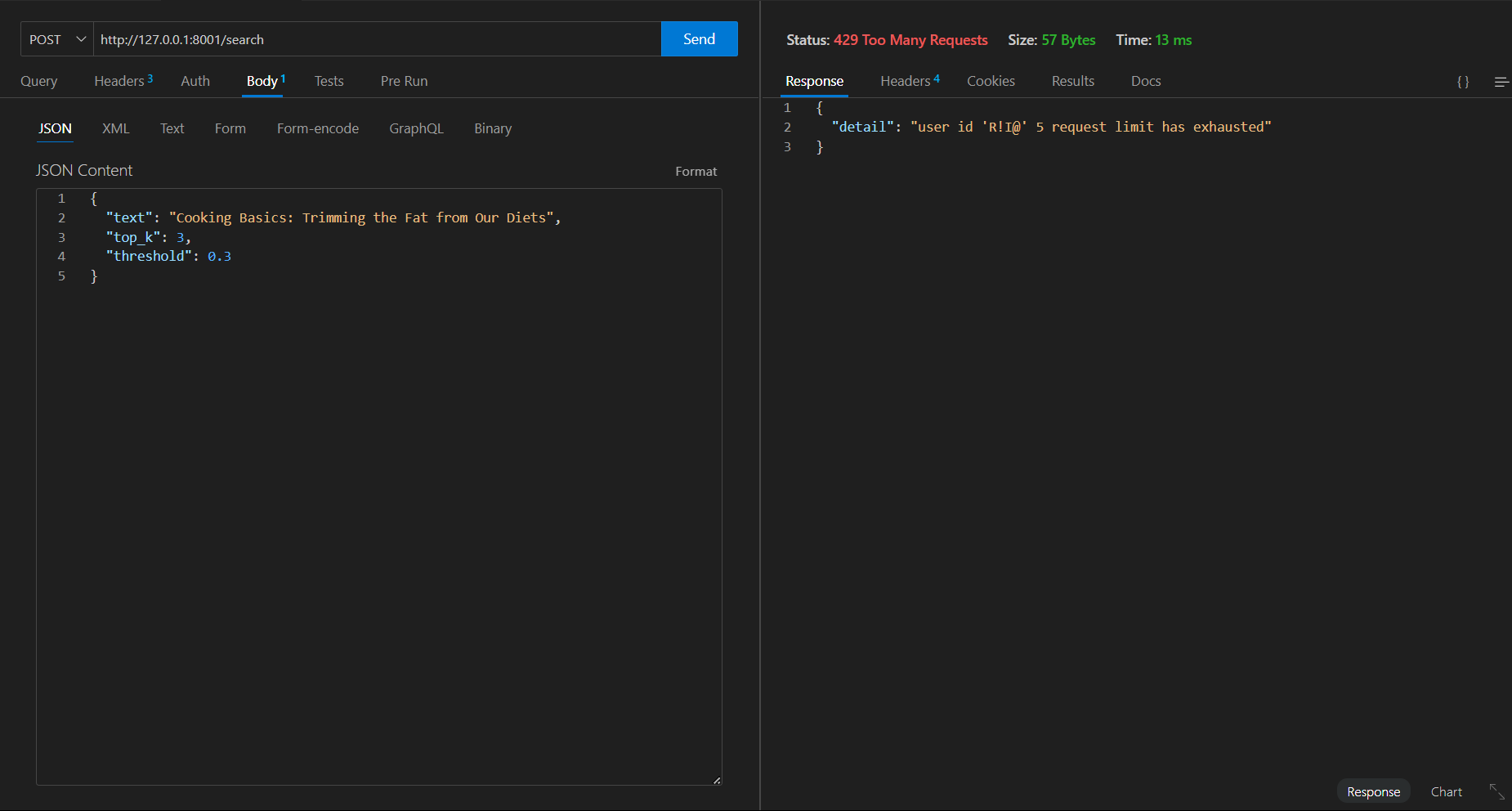
건강 검사 종말점
curl --location ' localhost:8001/health '검색 확인 엔드 포인트
curl --location ' localhost:8001/search ' --header ' user_id: riondsilva ' --header ' Content-Type: application/json ' --data ' { "text": "Ingredient Substitutions" , "top_k": 5 , "threshold": 0.3 } '*순서대로 실행하십시오
크로마 이미지
docker run -p 8000:8000 chromadb/chromaPostgres 이미지
docker run --name user-database -p 5432:5432
-e POSTGRES_PASSWORD=your_password -d postgres:12.20-alpine3.20 docker stop user-databaseDoc-Retieval
git clone https://github.com/RionDsilvaCS/document-retrieval-caching.git 기본 디렉토리에서 .env 파일을 작성하고 아래 변수를 추가하십시오.
DATABASE_URL="postgresql://postgres:your_password@localhost:5432/postgres"
COLLECTION_NAME="collection_name"
디렉토리 이름 data 작성하고 PDF 문서를 추가하십시오
mkdir data
./data 컨텐츠를 ChromADB에 저장하려면 store_in_db.py 실행하십시오
python store_in_db.pydocker compose up --build /health 서버가 부팅되는지 확인하기 위해 엔드 포인트를 얻습니다.
엔드 포인트
http://127.0.0.1:8001/health
응답
{
"Server Status" : " Successfully running ? "
} /search 챗봇과 대화하는 포스트 엔드 포인트입니다.
엔드 포인트
http://127.0.0.1:8001/search
헤더
{
"user_id" : " riondsilva "
}JSON 바디
{
"text" : " How are you? " ,
"top_k" : 3 ,
"threshold" : 0.3
}응답
{
"bot_message" : {
"top_k_results" : [
{
"message" : " I am great ? "
},
{
"message" : " I am fine "
},
{
"message" : " I am good "
}
],
"top_k" : 3 ,
"threshold" : 0.9
},
"user_message" : {
"text" : " How are you? " ,
"top_k" : 3 ,
"threshold" : 0.9 ,
"inference_time (secs)" : 1.16
},
"user_info" : " riondsilva "
}

