document retrieval caching
1.0.0
Build a backend for document retrieval with caching.
Caching Algorithm Created a Queue in server which will store limited number of nodes from vector database from previous quries. For every query from user will be first matched with queries in queue and if similarity (cosine) is above 0.9 than those nodes returned back from the lookup table maintained seperately.
First request => time taken 787 ms
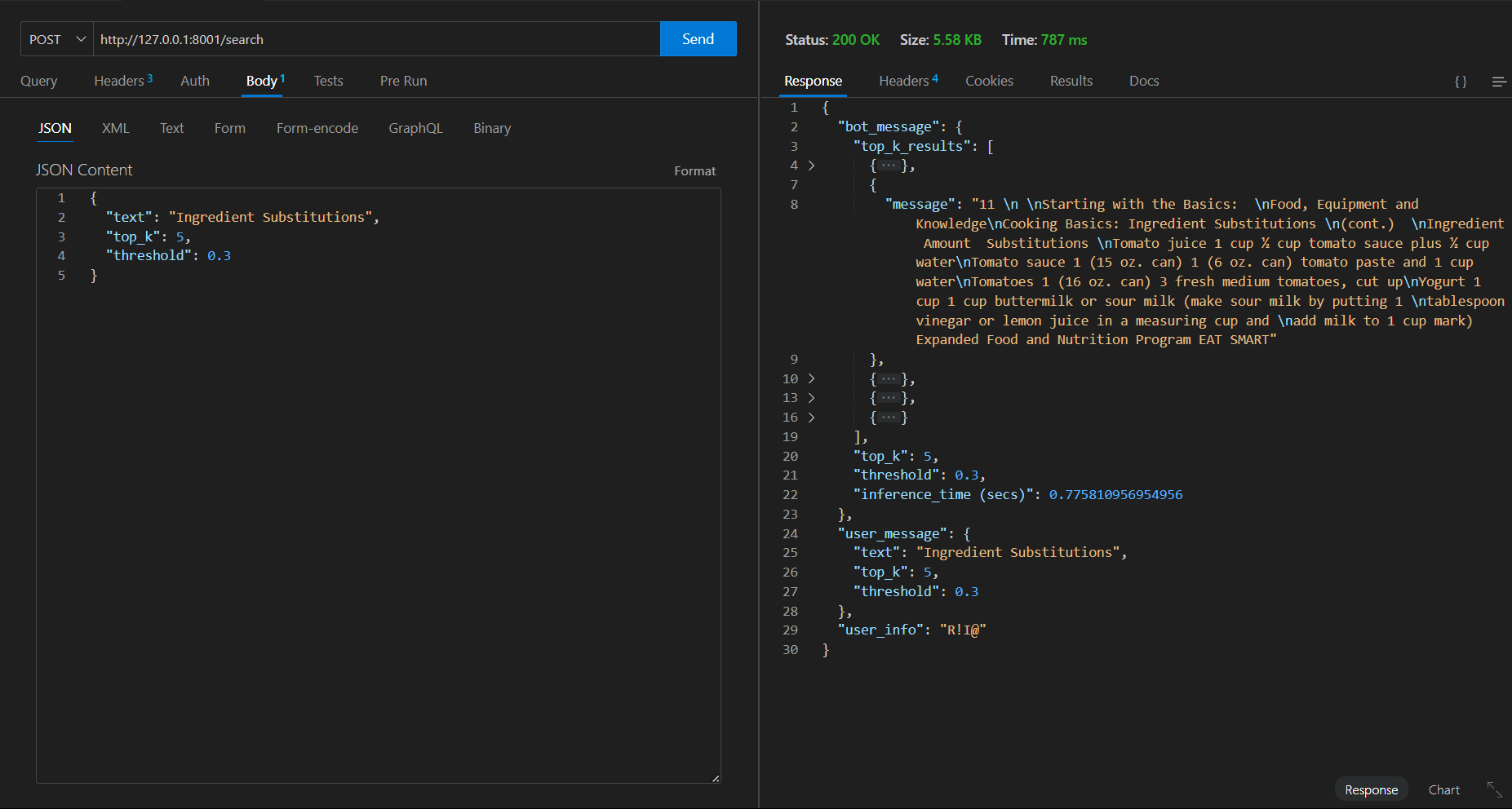
Second Similar request => time taken 54 ms
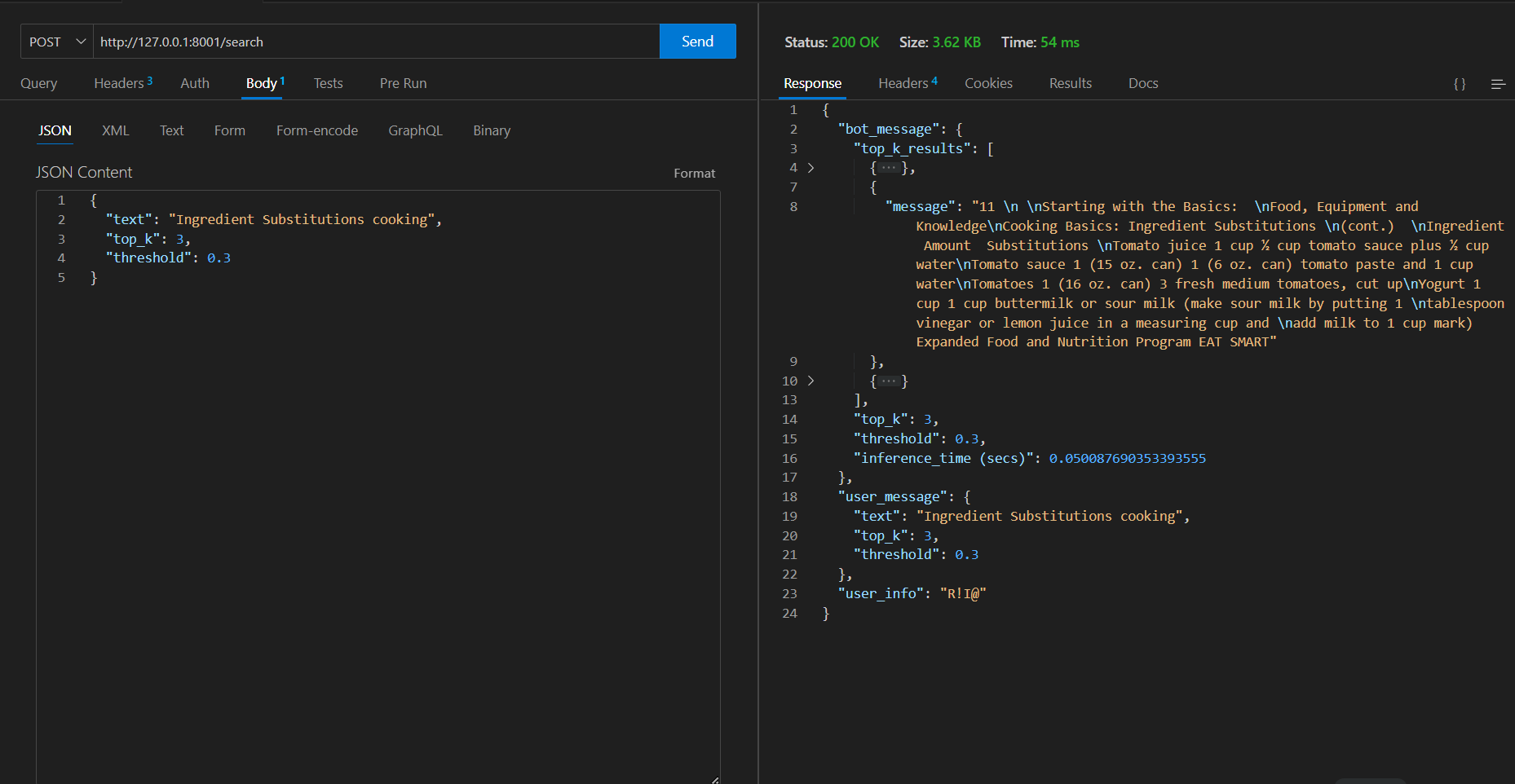
Bad request
Health check endpoint
curl --location 'localhost:8001/health'Search check endpoint
curl --location 'localhost:8001/search' --header 'user_id: riondsilva' --header 'Content-Type: application/json' --data '{ "text": "Ingredient Substitutions" , "top_k": 5 , "threshold": 0.3 }'*Run in order
Chroma Image
docker run -p 8000:8000 chromadb/chromaPostgres Image
docker run --name user-database -p 5432:5432
-e POSTGRES_PASSWORD=your_password -d postgres:12.20-alpine3.20 docker stop user-databaseDoc-Retrieval
git clone https://github.com/RionDsilvaCS/document-retrieval-caching.gitCreate .env file in the main directory and add the below variables
DATABASE_URL="postgresql://postgres:your_password@localhost:5432/postgres"
COLLECTION_NAME="collection_name"
Create directory name data and add pdf documents
mkdir data
Run store_in_db.py to save the ./data content to chromadb
python store_in_db.pydocker compose up --build/health is GET endpoint to check if server is boot up
Endpoint
http://127.0.0.1:8001/health
Response
{
"Server Status": "Successfully running ?"
}/search is a POST endpoint to conversate with the chatbot
Endpoint
http://127.0.0.1:8001/search
Header
{
"user_id": "riondsilva"
}JSON Body
{
"text": "How are you?",
"top_k": 3,
"threshold": 0.3
}Response
{
"bot_message": {
"top_k_results": [
{
"message": "I am great ?"
},
{
"message": "I am fine"
},
{
"message": "I am good"
}
],
"top_k": 3,
"threshold": 0.9
},
"user_message": {
"text": "How are you?",
"top_k": 3,
"threshold": 0.9,
"inference_time (secs)": 1.16
},
"user_info": "riondsilva"
}

