document retrieval caching
1.0.0
キャッシングを使用したドキュメント検索用のバックエンドを作成します。
キャッシングアルゴリズムは、以前のクーリーのベクトルデータベースから限られた数のノードを保存するサーバーにキューを作成しました。ユーザーからのすべてのクエリについて、最初にキュー内のクエリと一致し、類似性(コサイン)が別々に維持されているルックアップテーブルから戻ったノードよりも0.9を超えている場合。
最初のリクエスト=> 787 msかかります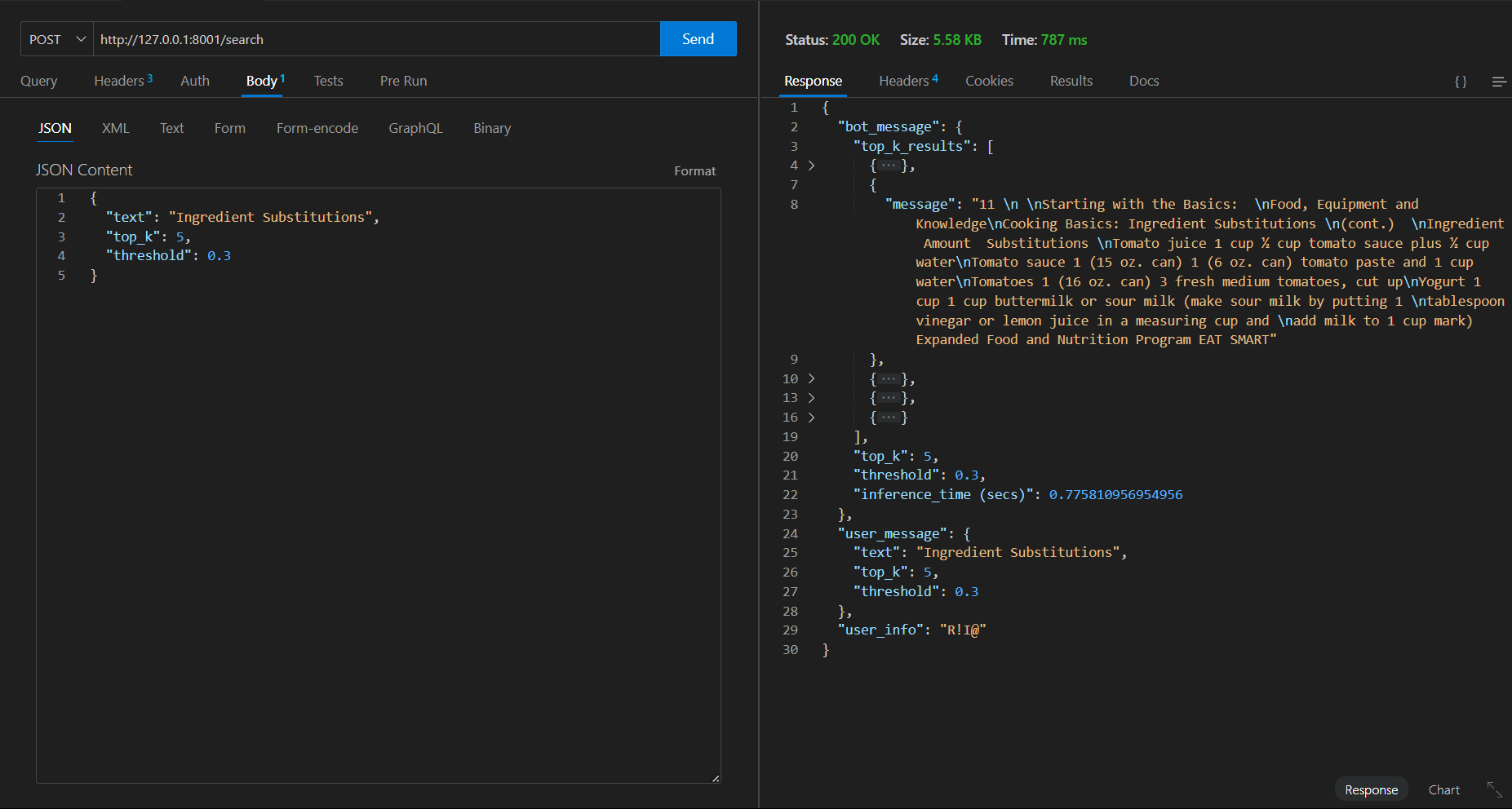
2番目の同様のリクエスト=> 54 msかかります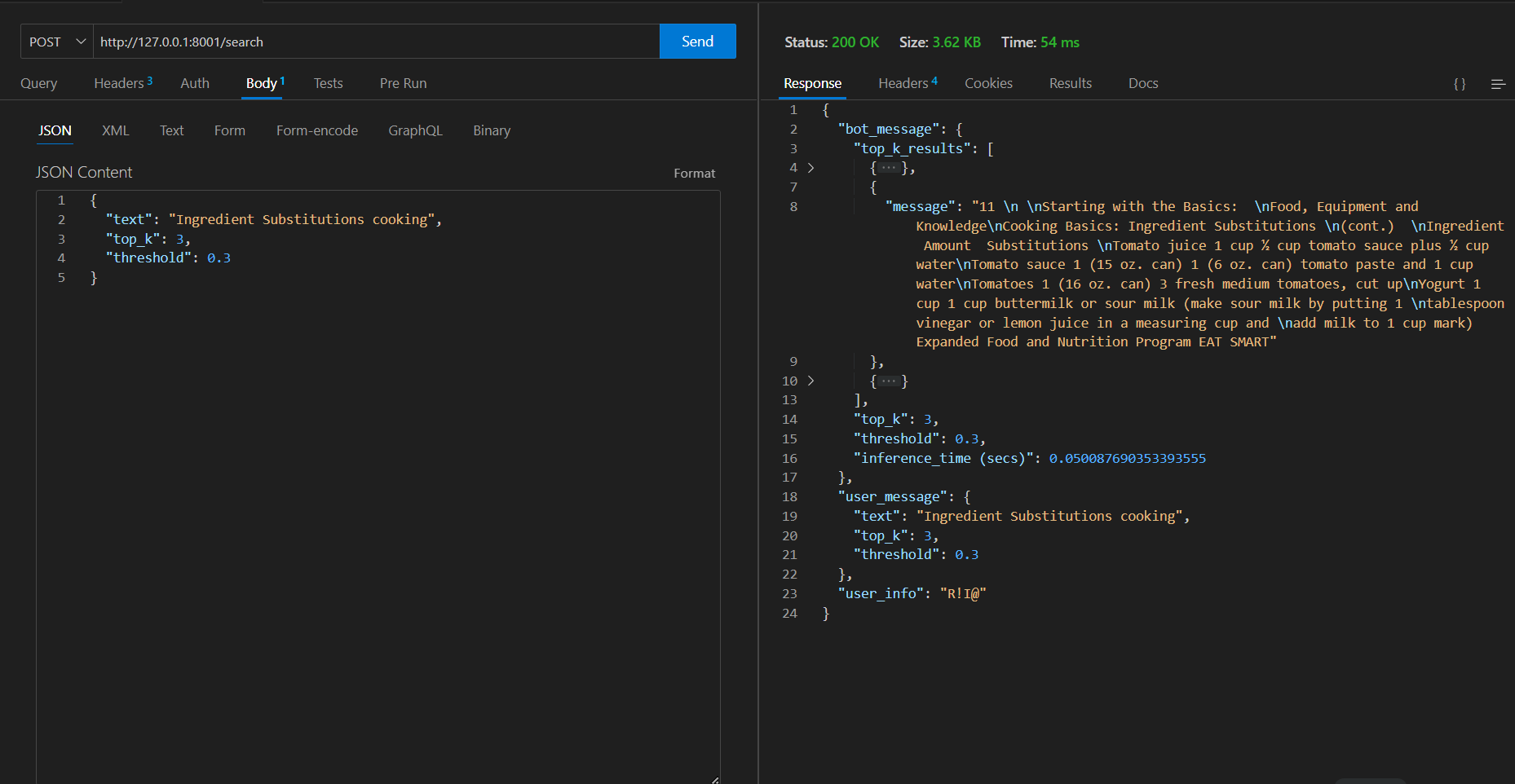
要求の形式が正しくありません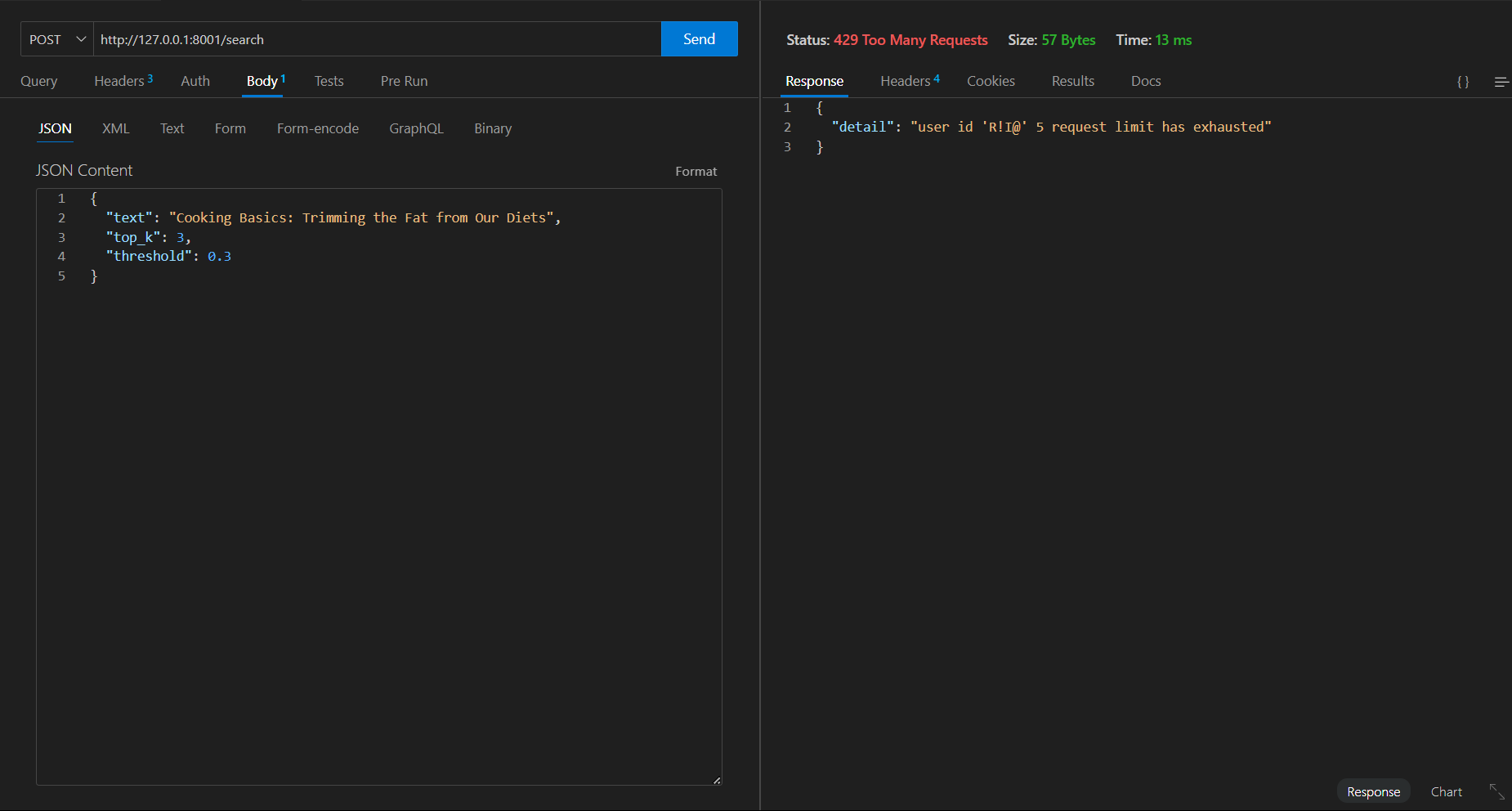
ヘルスチェックエンドポイント
curl --location ' localhost:8001/health '検索チェックエンドポイント
curl --location ' localhost:8001/search ' --header ' user_id: riondsilva ' --header ' Content-Type: application/json ' --data ' { "text": "Ingredient Substitutions" , "top_k": 5 , "threshold": 0.3 } '*順番に実行します
クロマ画像
docker run -p 8000:8000 chromadb/chromaポストグレス画像
docker run --name user-database -p 5432:5432
-e POSTGRES_PASSWORD=your_password -d postgres:12.20-alpine3.20 docker stop user-databasedoc-retrieval
git clone https://github.com/RionDsilvaCS/document-retrieval-caching.gitメインディレクトリに.envファイルを作成し、以下の変数を追加します
DATABASE_URL="postgresql://postgres:your_password@localhost:5432/postgres"
COLLECTION_NAME="collection_name"
ディレクトリ名dataを作成し、PDFドキュメントを追加します
mkdir data
chromadbに./dataコンテンツを保存するには、 store_in_db.pyを実行します
python store_in_db.pydocker compose up --build/healthはエンドポイントを取得してサーバーが起動しているかどうかを確認します
終点
http://127.0.0.1:8001/health
応答
{
"Server Status" : " Successfully running ? "
} /search 、チャットボットと会話するための投稿エンドポイントです
終点
http://127.0.0.1:8001/search
ヘッダ
{
"user_id" : " riondsilva "
}Json Body
{
"text" : " How are you? " ,
"top_k" : 3 ,
"threshold" : 0.3
}応答
{
"bot_message" : {
"top_k_results" : [
{
"message" : " I am great ? "
},
{
"message" : " I am fine "
},
{
"message" : " I am good "
}
],
"top_k" : 3 ,
"threshold" : 0.9
},
"user_message" : {
"text" : " How are you? " ,
"top_k" : 3 ,
"threshold" : 0.9 ,
"inference_time (secs)" : 1.16
},
"user_info" : " riondsilva "
}

