ask redis blogs
1.0.0
我们构建了一个聊天机器人,可以根据用户查询在Redis.com网站上汇总并推荐博客。
这个小型项目使用2种AI模型
在这个项目中,我们旨在证明
最简单的方法是使用以下命令使用Docker映像
docker run -d -p 6379:6379 -p 8001:8001 redis/redis-stack:latest如果您不想使用Docker映像,则可以在此处注册免费的Redis Cloud订阅。
下载存储库
git clone https://github.com/mar1boroman/ask-redis-blogs.git && cd ask-redis-blogs
准备并激活虚拟环境
python3 -m venv .env && source .env/bin/activate
安装必要的库和依赖项
pip install -r requirements.txt
我们在REDIS博客上拥有广泛的知识库,让运行第一个脚本是Web Craper,该脚本将刮擦网站并创建一个包含所有可用博客数据的CSV文件。
python 0_ext_redis_blogs.py请注意,该存储库已经已更新到2023年9月19日,运行此脚本只会下载新博客。 CSV文件保存在redis_blogs.csv上
在此步骤中,我们为每个博客的文本内容生成嵌入,并以哈希格式存储它们
python 1_load_redis_blogs.py您可以在http:// localhost:8001中对redisinsight进行redis数据库的内容探索您的redis数据库的内容
现在,我们已经将博客及其嵌入在Redis中,该是时候看到聊天机器人正在行动!
streamlit run 3_ui.py
让我们在我们的博客上运行一个简单的向量相似性搜索。
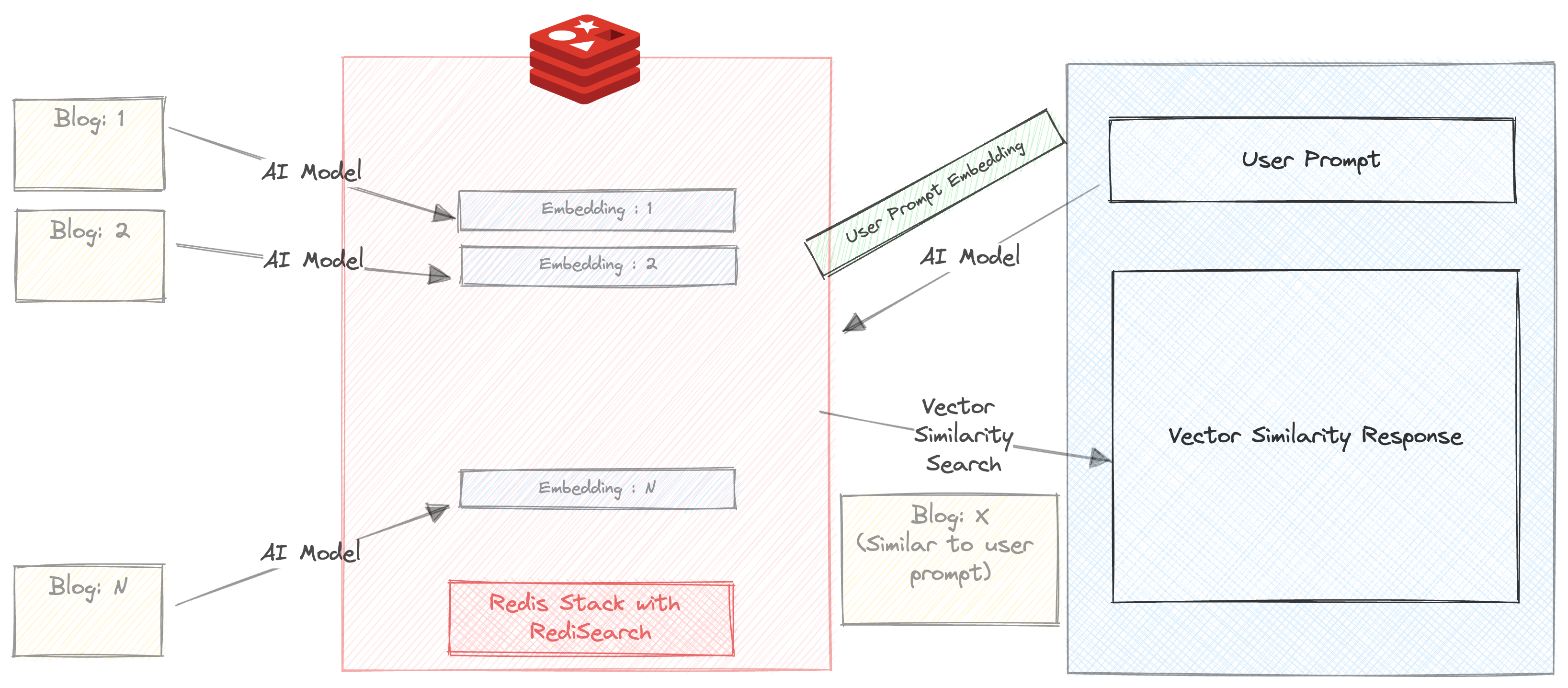
确保未选中“自动汇总”复选框
输入提示。例如
Triggers and Functions
您将在毫秒内获得3个博客建议。响应还包括返回响应所花费的时间。在这种情况下,搜索完全在REDIS中进行,只是在运行相似性搜索之前通过All-Mpnet-Base-V2运行该提示
让我们变得更加先进。
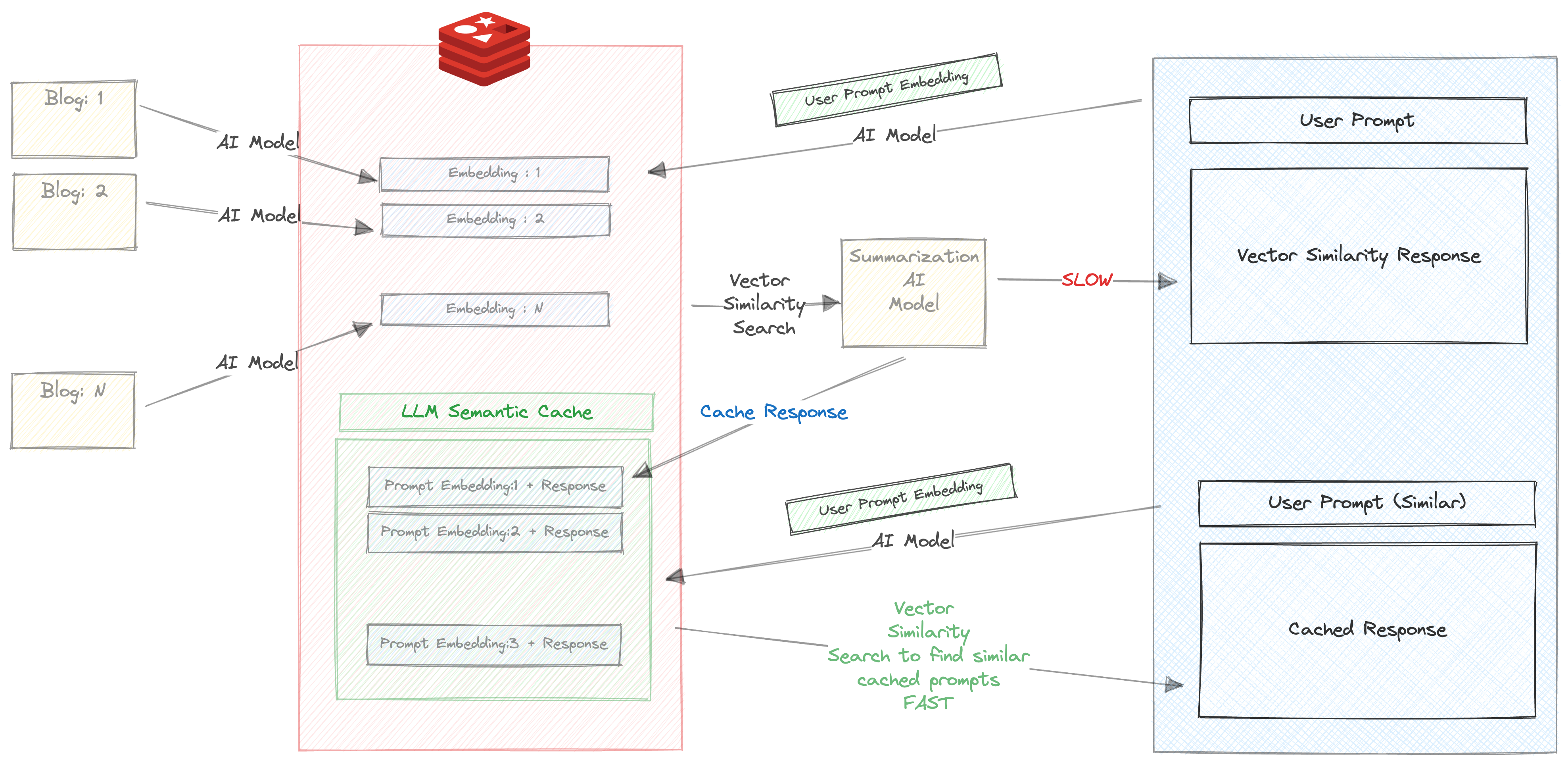
确保检查“自动总结”复选框
输入提示。例如
Triggers and Functions
当您第一次输入此提示时,将会发生以下事情
这需要相当长的时间,大约30 s
因此,我们将响应和提示存储在Redis中。在浏览器中检查您的重新介绍,您将看到一个使用前缀llm_cache创建的键
响应返回后,提示和响应将被缓存,更重要的是,该提示通过ALL-MPNET-BASE-V2运行,并且其相应的嵌入也被缓存
现在,尝试运行相同的提示(或再次相似的提示)。例如
About Triggers and functions
您将根据提示嵌入和上一步中缓存的响应之间的巨大快速向量相似性搜索获得缓存的响应。
我们可以清楚地看到在此处使用语义缓存的好处
CLI版本可用聊天机器人的版本
python 2_vecsim_redis_blogs.py

