ask redis blogs
1.0.0
Nous créons un chatbot qui peut résumer et recommander des blogs sur le site Web redis.com en fonction de la requête utilisateur.
Ce petit projet utilise 2 modèles d'IA
Dans ce projet, nous visons à démontrer
Le moyen le plus simple est d'utiliser une image Docker en utilisant la commande ci-dessous
docker run -d -p 6379:6379 -p 8001:8001 redis/redis-stack:latestSi vous ne souhaitez pas utiliser une image Docker, vous pouvez vous inscrire à un abonnement Redis Cloud gratuit ici.
Télécharger le référentiel
git clone https://github.com/mar1boroman/ask-redis-blogs.git && cd ask-redis-blogs
Préparer et activer l'environnement virtuel
python3 -m venv .env && source .env/bin/activate
Installez les bibliothèques et dépendances nécessaires
pip install -r requirements.txt
Nous avons une vaste base de connaissances sur le blog Redis permet d'exécuter le premier script qui est un webscraper, ce script grattera le site Web et créera un fichier CSV contenant les données de tous les blogs disponibles.
python 0_ext_redis_blogs.pyRemarque Ce référentiel a déjà les blogs mis à jour jusqu'au 19 septembre 2023, l'exécution de ce script ne téléchargera que les nouveaux blogs. Le fichier CSV est enregistré sur redis_blogs.csv
Dans cette étape, nous générons l'incorporation pour le contenu texte de chaque blog et les stockons dans un format de hachage
python 1_load_redis_blogs.pyVous pouvez explorer le contenu de votre base de données Redis dans RedisInssight sur votre navigateur sur http: // localhost: 8001
Maintenant que nous avons stocké les blogs et leurs intérêts dans Redis, il est temps de voir le chatbot en action!.
streamlit run 3_ui.py
Permet d'exécuter une simple recherche de similitude vectorielle sur nos blogs.
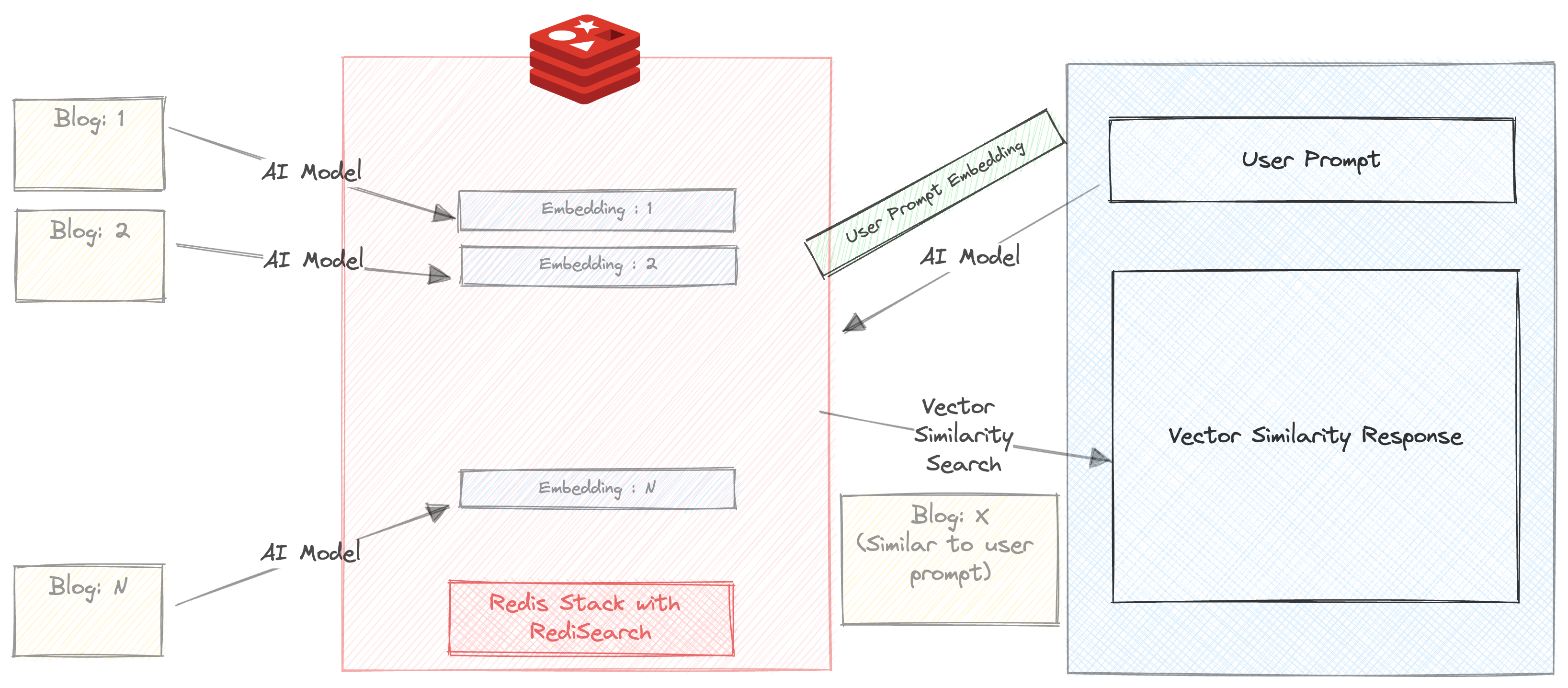
Assurez-vous que la case à cocher «Auto Résumé» n'est pas contrôlée
Entrez une invite. Par exemple
Triggers and Functions
Vous obtiendrez 3 recommandations de blog en millisecondes. La réponse comprend également le temps pris pour retourner la réponse. Dans ce cas, la recherche se produit entièrement dans Redis, sauf que l'invite est exécutée via All-MPNET-Base-V2 avant d'exécuter la recherche de similitude
Permet de devenir un peu plus avancé.
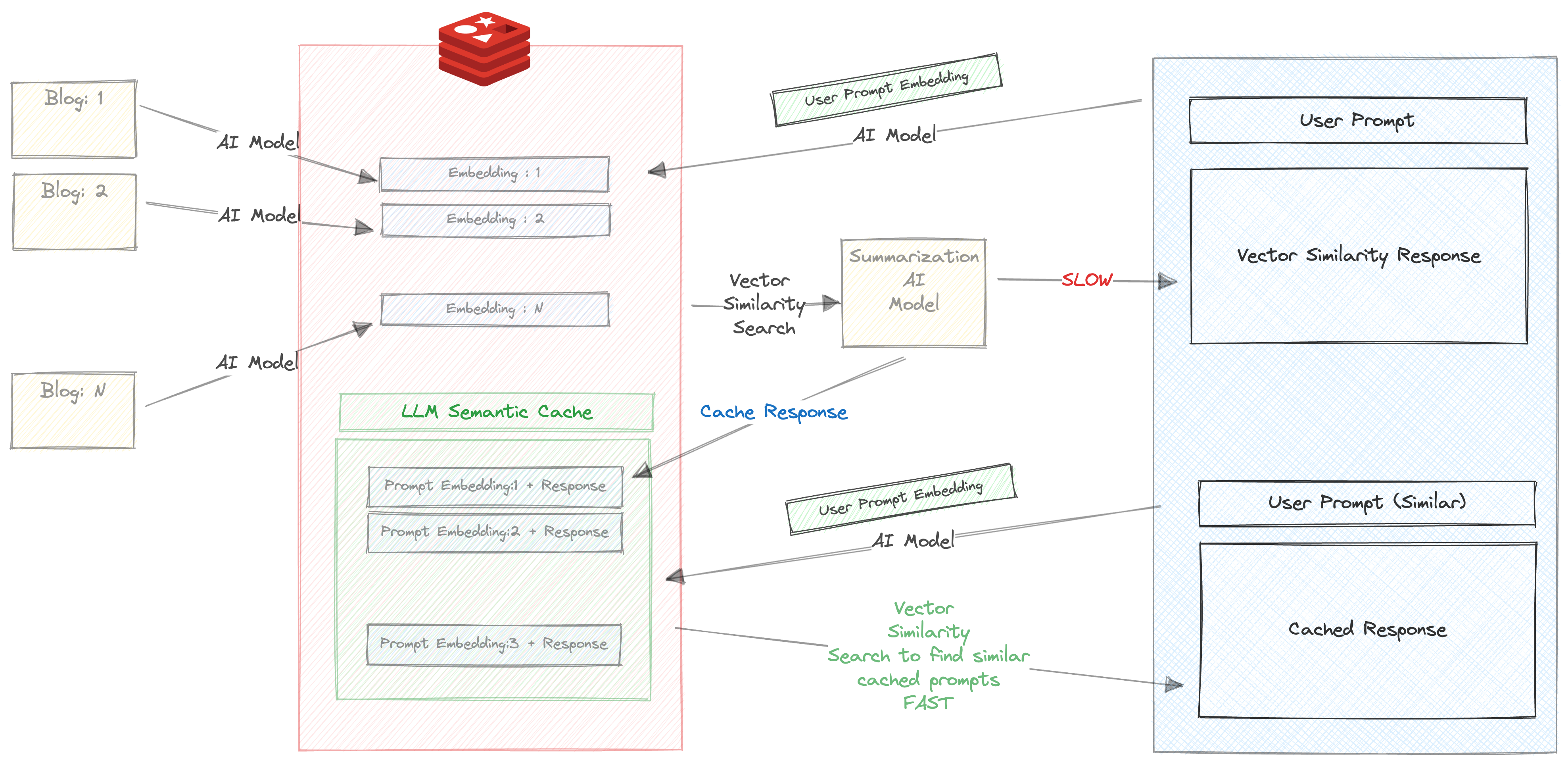
Assurez-vous que la case à cocher «Auto Résumé» est cochée
Entrez une invite. Par exemple
Triggers and Functions
Lorsque vous entrez cette invite pour la première fois, les choses suivantes se produiront
Cela prend beaucoup de temps, environ 30 s
Par conséquent, nous stockons la réponse et l'invite dans Redis. Vérifiez votre RedisInsight dans le navigateur et vous verrez une clé créée avec le préfixe llm_cache
Une fois la réponse qu'il est retourné, l'invite et la réponse sont mises en cache, et plus important encore , l'invite est exécutée via All-MPNET-Base-V2 et son intégration correspondante est également mise en cache
Essayez maintenant d'exécuter à nouveau la même invite (ou une invite similaire). Par exemple
About Triggers and functions
Vous obtiendrez la réponse en cache en fonction de la recherche de similitude vectorielle et rapide dans une influence entre les invites et la réponse qui a été mise en cache à l'étape précédente.
Nous pouvons clairement voir les avantages de l'utilisation de la mise en cache sémantique ici
Une version du chatbot est disponible en version CLI
python 2_vecsim_redis_blogs.py

