ask redis blogs
1.0.0
Construímos um chatbot que pode resumir e recomendar blogs no site Redis.com com base na consulta do usuário.
Este pequeno projeto usa 2 modelos de IA
Neste projeto, pretendemos demonstrar
A maneira mais fácil de usar uma imagem do docker usando o comando abaixo
docker run -d -p 6379:6379 -p 8001:8001 redis/redis-stack:latestSe você não deseja usar uma imagem do Docker, pode se inscrever para uma assinatura gratuita da Redis Cloud aqui.
Baixe o repositório
git clone https://github.com/mar1boroman/ask-redis-blogs.git && cd ask-redis-blogs
Prepare e ativar o ambiente virtual
python3 -m venv .env && source .env/bin/activate
Instale as bibliotecas e dependências necessárias
pip install -r requirements.txt
Temos uma extensa base de conhecimento no Redis Blog, vamos executar o primeiro script que é um escravo da Web, este script raspará o site e criará um arquivo CSV que contém os dados de todos os blogs disponíveis.
python 0_ext_redis_blogs.pyObserve que este repositório já possui os blogs atualizados até 19 de setembro de 2023, executando este script apenas baixará os novos blogs. O arquivo CSV é salvo em redis_blogs.csv
Nesta etapa, geramos a incorporação para o conteúdo de texto de cada blog e os armazenamos em um formato de hash
python 1_load_redis_blogs.pyVocê pode explorar o conteúdo do seu banco de dados Redis no Redisinsight em seu navegador em http: // localhost: 8001
Agora que armazenamos os blogs e suas incorporações em Redis, é hora de ver o chatbot em ação!.
streamlit run 3_ui.py
Vamos executar uma pesquisa simples de similaridade vetorial em nossos blogs.
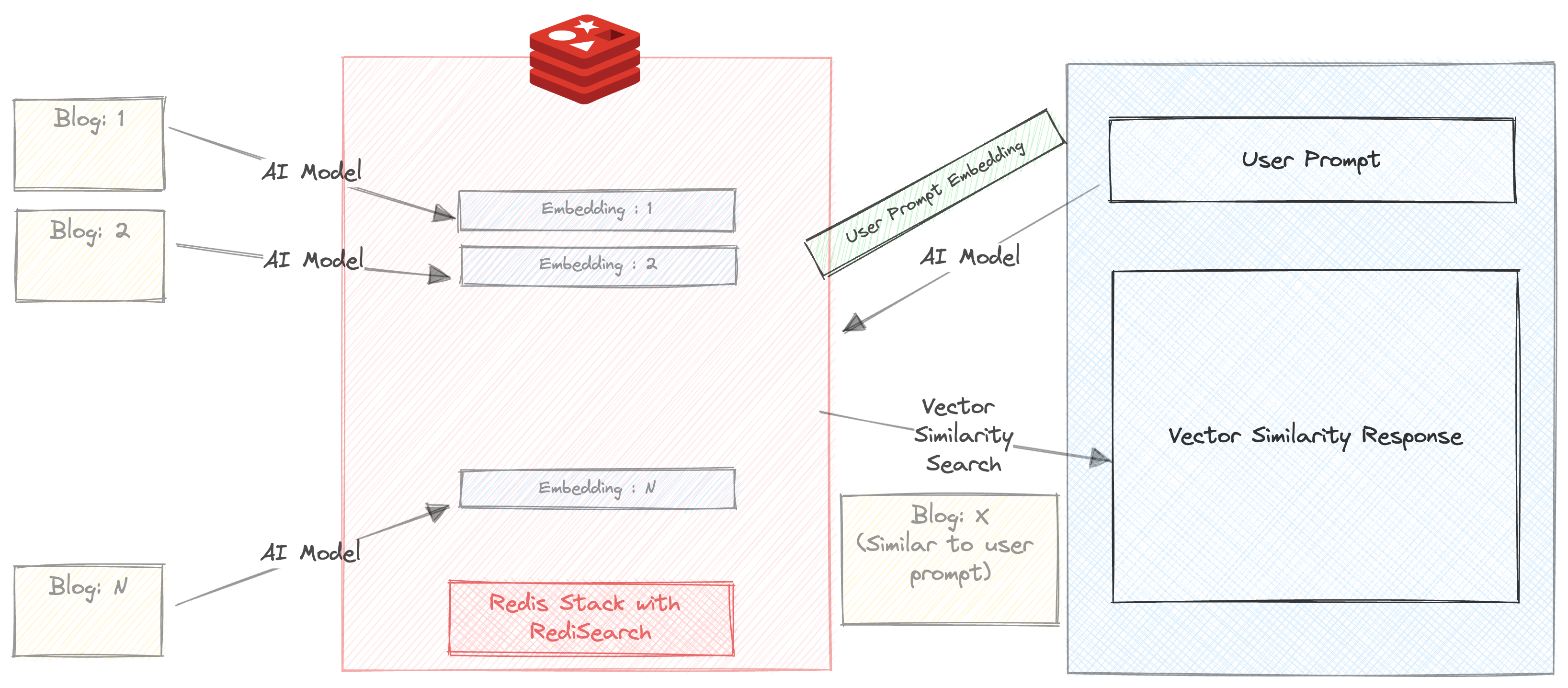
Certifique -se de que a caixa de seleção 'resumir automaticamente' não seja desmarcada
Digite um prompt. Para por exemplo
Triggers and Functions
Você receberá três recomendações de blog em milissegundos. A resposta também inclui o tempo necessário para devolver a resposta. Nesse caso, a pesquisa acontece inteiramente em Redis, exceto que o prompt é executado através do All-MPNET-BASE-V2 antes de executar a pesquisa de similaridade
Vamos ficar um pouco mais avançados.
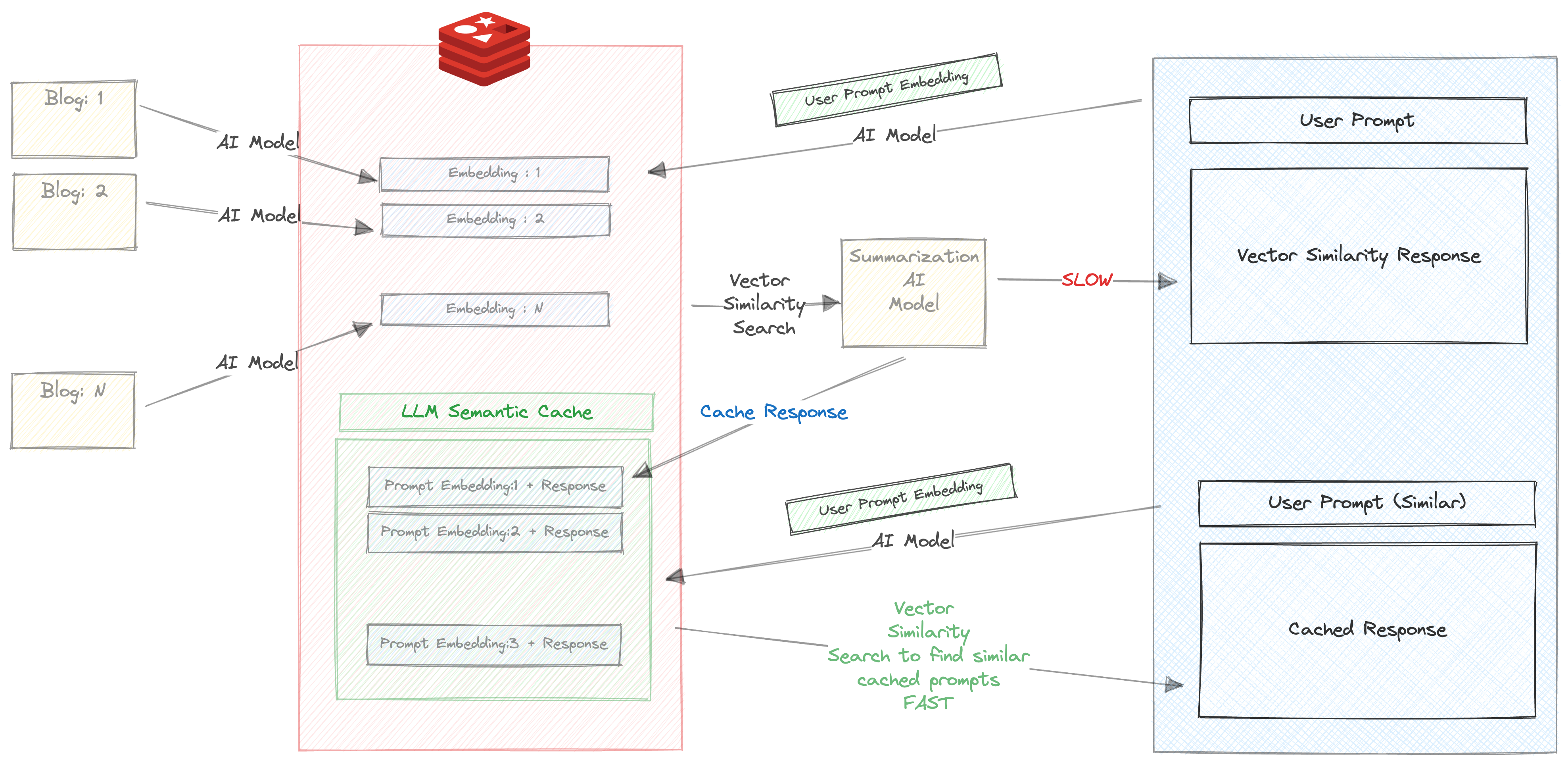
Certifique -se de que a caixa de seleção 'resumo automático' seja verificada
Digite um prompt. Para por exemplo
Triggers and Functions
Quando você entra neste prompt pela primeira vez, as seguintes coisas acontecerão
Isso leva um tempo consideravelmente longo, cerca de 30 s
Portanto, armazenamos a resposta e o prompt em Redis. Verifique seu Redisinsight no navegador e você verá uma chave criada com o prefix llm_cache
Depois que a resposta retornou, o prompt e a resposta são armazenados em cache e, mais importante, o prompt é executado através do All-MPNET-BASE-V2 e sua incorporação correspondente também é armazenada em cache
Agora tente executar o mesmo prompt (ou prompt de similar novamente). Para por exemplo
About Triggers and functions
Você receberá a resposta em cache com base na pesquisa de similaridade vetorial incrivelmente rápida entre a incorporação de prompts e a resposta que foi armazenada em cache na etapa anterior.
Podemos ver claramente os benefícios de usar o cache semântico aqui
Uma versão do chatbot está disponível na versão da CLI
python 2_vecsim_redis_blogs.py

