xxHash
v0.8.2
XXHASH是一种非常快速的哈希算法,以RAM速度限制处理。代码是高度便携的,并且在所有平台(小 /大端)上产生相同的哈希。该库包括以下算法:
v0.8.0以来):使用矢量化算术生成64或128位哈希。 128位变体称为XXH128。所有变体都成功完成了评估哈希功能质量(碰撞,分散和随机性)的Smhasher测试套件。还提供了其他测试,该测试还提供了更全面的速度和64位哈希的碰撞特性。
| 分支 | 地位 |
|---|---|
| 发布 |  |
| 开发 |  |
基准的参考系统使用Intel I7-9700K CPU,并运行Ubuntu X64 20.04。使用-O3标志与clang V10.0编译开源基准程序。
| 哈希名 | 宽度 | 带宽(GB/S) | 小数据速度 | 质量 | 评论 |
|---|---|---|---|---|---|
| XXH3 (SSE2) | 64 | 31.5 GB/s | 133.1 | 10 | |
| XXH128 (SSE2) | 128 | 29.6 GB/s | 118.1 | 10 | |
| RAM顺序读取 | N/A。 | 28.0 GB/s | N/A。 | N/A。 | 供参考 |
| 城市64 | 64 | 22.0 GB/s | 76.6 | 10 | |
| T1HA2 | 64 | 22.0 GB/s | 99.0 | 9 | 碰撞稍差 |
| 城市128 | 128 | 21.7 GB/s | 57.7 | 10 | |
| xxh64 | 64 | 19.4 GB/s | 71.0 | 10 | |
| Spookyhash | 64 | 19.3 GB/s | 53.2 | 10 | |
| 妈妈 | 64 | 18.0 GB/s | 67.0 | 9 | 碰撞稍差 |
| xxh32 | 32 | 9.7 GB/s | 71.9 | 10 | |
| 城市32 | 32 | 9.1 GB/s | 66.0 | 10 | |
| Murmur3 | 32 | 3.9 GB/s | 56.1 | 10 | |
| siphash | 64 | 3.0 GB/s | 43.2 | 10 | |
| FNV64 | 64 | 1.2 GB/s | 62.7 | 5 | 雪崩的差 |
| Blake2 | 256 | 1.1 GB/s | 5.1 | 10 | 加密 |
| SHA1 | 160 | 0.8 GB/s | 5.6 | 10 | 加密但破裂 |
| MD5 | 128 | 0.6 GB/s | 7.8 | 10 | 加密但破裂 |
注意1:小数据速度是对算法在小数据上的效率的粗略评估。有关更多详细分析,请参阅下一段。
注2:某些算法的特征比RAM速度快。在这种情况下,当输入已经在CPU缓存(L3或更高)中时,它们只能达到全速电位。否则,它们会以RAM速度限制最大化。
大数据的性能只是图片的一部分。哈希在哈希表和盛开过滤器之类的结构中也非常有用。在这些用例中,经常使用许多小数据(以几个字节开始)。对于这种情况,算法的性能可能会大不相同,因为算法的某些部分(例如初始化或最终化)成为固定成本。分支错误预测的影响也变得更加存在。
XXH3已设计为在长输入和小型输入上都具有出色的性能,可以在以下图中观察到:
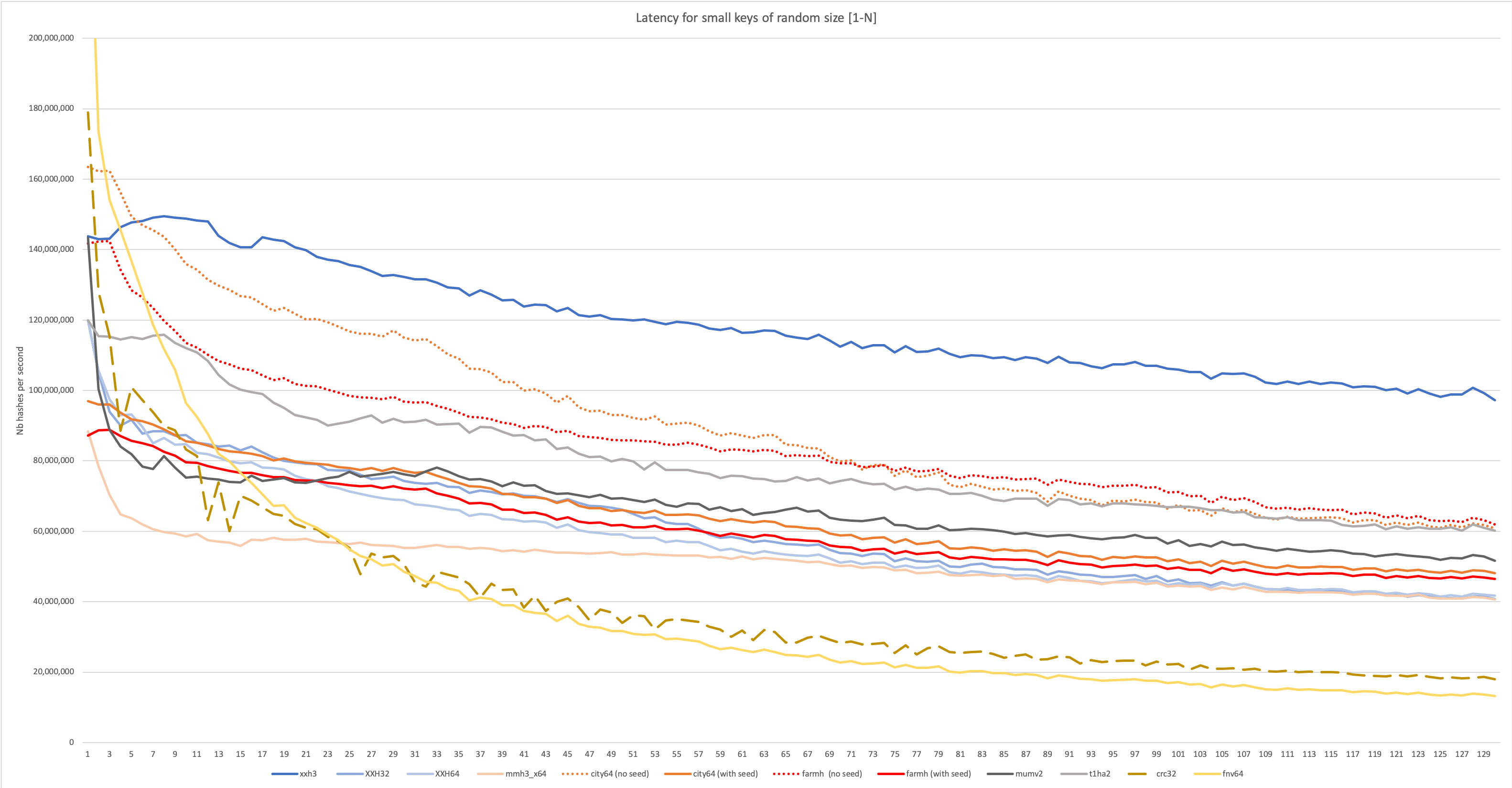
要进行更详细的分析,请访问Wiki:https://github.com/cyan4973/xxhash/wiki/performance-comparison-comparison#benchs-concentration-concentration-oncentration-on-small-data--
速度不是唯一重要的属性。产生的哈希值必须尊重出色的分散性和随机性特性,以便可以使用其最大分布表或索引的任何子部分,并在生日悖论之后将碰撞量减少到最小的理论水平。
xxHash已通过Austin Appleby出色的Smhasher测试套件进行了测试,并通过所有测试,确保了合理的质量水平。它还通过Smhasher的新叉子进行了扩展测试,其中包括其他场景和条件。
最后,XXHASH提供了自己的巨大碰撞测试仪,能够生成和比较数十亿个哈希人来测试64位哈希算法的限制。在这方面,XXHASH也具有与生日悖论一致的良好结果。 Wiki中记录了更详细的分析。
可以在汇编时间设置以下宏来修改libxxhash的行为。默认情况下,它们通常被禁用。
XXH_INLINE_ALL :使所有功能inline ,实现直接包含在xxhash.h中。插入功能对速度有益,特别是对小键。当Key的长度表示为编译时间常数时,它非常有效,并且在 +200%范围内观察到性能提高。有关详细信息,请参见本文。XXH_PRIVATE_API :与XXH_INLINE_ALL相同的结果。仍然可用于传统支持。该名称强调了XXH_*符号名称不会导出。XXH_STATIC_LINKING_ONLY :访问静态分配所需的内部状态声明。由于ABI变化的风险,与动态链接不兼容。XXH_NAMESPACE :前缀所有符号都具有XXH_NAMESPACE的值。该宏只能使用可编译的字符集。如果XXHASH的源代码多个包含物,则有助于逃避符号命名碰撞。客户端应用程序仍然使用常规函数名称,因为符号会自动通过xxhash.h自动翻译。XXH_FORCE_ALIGN_CHECK :在对齐输入时,请使用更快的直接读取路径。当输入到Hash恰好在32或64位边界上对齐时,此选项可能会导致无法从未对齐地址加载内存的体系结构的急剧提高。它(略有)在平台上具有良好的未对齐内存访问性能(对对齐和未对准访问的指令相同)。此选项将在x86 , x64和aarch64上自动禁用,并在所有其他平台上启用。XXH_FORCE_MEMORY_ACCESS :默认方法0使用便携式memcpy()符号。方法1使用特定于GCC的packed属性,该属性可以为某些目标提供更好的性能。方法2力量不一致的读数,这不是标准的,但有时可能是提取更好读取性能的唯一方法。方法3使用字节截面操作,最适合不嵌入memcpy()或大型系统的旧编译器,而没有字节汇款说明。XXH_CPU_LITTLE_ENDIAN :默认情况下,Endianness由在编译时解决的运行时测试确定。如果出于某种原因,编译器无法简化运行时测试,则可以花费性能。可以跳过自动检测,并简单地说明该架构将其设置为1。XXH_ENABLE_AUTOVECTORIZE :XXH32和XXH64可以触发自动矢量化,具体取决于CPU矢量功能和编译器版本。注意:最近版本的clang倾向于更容易触发自动矢量化。对于XXH32,SSE4.1或等效(NEON)就足够了,而XXH64需要AVX512。不幸的是,自动矢量化通常不利于XXH性能。因此,XXHASH源代码试图防止默认情况下自动矢量化。话虽这么说,系统就不断发展,并且这一结论并不是即将得出的。例如,据报道,最近的Zen4 CPU更有可能通过矢量化提高性能。因此,如果您喜欢或想测试矢量化代码,则可以启用此标志:它将删除无矢量化保护代码,从而使XXH32和XXH64自动矢量化更有可能。XXH32_ENDJMP :单个跳跃的XXH32的多分支最终确定阶段。通常,这对于性能是不可取的,尤其是在随机大小的哈希输入时。但是根据确切的体系结构和编译器,跳跃可能会在小型输入上提供更好的性能。默认情况下禁用。XXH_IMPORT :MSVC特定:仅应为动态链接定义,因为它可以防止链接错误。XXH_NO_STDLIB : <stdlib.h>函数的禁用调用,尤其是malloc()和free() 。 libxxhash的XXH*_createState()将始终失败并返回NULL 。但是一击哈希(例如XXH32() )或使用静态分配状态流式传输仍可以按预期工作。该构建标志对于没有动态分配的嵌入式环境很有用。XXH_DEBUGLEVEL :设置为任何值> = 1时,启用assert()语句。这(稍微)减慢了执行,但可能有助于在调试会议期间找到错误。 XXH_NO_XXH3 :从生成的二进制文件中删除与XXH3 (64和128位)相关的符号。 XXH3是迄今为止libxxhash尺寸的最大贡献者,因此减少不使用XXH3的应用程序二进制尺寸很有用。XXH_NO_LONG_LONG :删除依赖64位long long类型的算法的编译,包括XXH3和XXH64 。仅XXH32将被编译。对于无64位支持的目标(架构和编译器)有用。XXH_NO_STREAM :禁用流动API,将库仅限于单个镜头变体。XXH_NO_INLINE_HINTS :默认情况下,XXHASH使用__attribute__((always_inline))和__forceinline以代码大小为代价来提高性能。将此宏定义为1将所有内部功能都标记为static ,从而允许编译器决定是否嵌入功能。当对最小的二进制尺寸进行优化时,这非常有用,并且在使用-O0 , -Os , -Oz或-fno-inline上在GCC和Clang上自动定义。这也可能会根据编译器和体系结构提高性能。XXH_SIZE_OPT : 0 :默认值,优化速度1 : -Os和-Oz的默认值:禁用一些速度hacks以进行大小优化2 :使代码尽可能小,性能可能会哭泣XXH_VECTOR :手动选择一个向量指令集(默认:在编译时自动选择)。可用的说明集为XXH_SCALAR , XXH_SSE2 , XXH_AVX2 , XXH_AVX512 , XXH_NEON和XXH_VSX 。编译器可能需要其他标志来确保适当的支持(例如,X86_64上的gcc需要-mavx2的AVX2或-mavx512f , AVX512 )。XXH_PREFETCH_DIST :选择预取距离。以近距离适应特定的硬件平台。仅xxh3。XXH_NO_PREFETCH :禁用预取。某些平台或情况可能会表现更好,而无需预取。仅xxh3。 使用make编译命令行界面xxhsum时,还可以设置以下环境变量:
DISPATCH=1 :使用xxh_x86dispatch.c ,根据本地主机在运行时自动选择scalar , sse2 , avx2或avx512指令。此选项仅对x86 / x64系统有效。XXH_1ST_SPEED_TARGET :选择一个以MB/s表示的初始速度目标,以在基准模式下进行首次速度测试。基准将在随后的迭代中调整目标,但是第一个测试是通过靶向此速度“盲目”进行的。目前,保守的设置为10 MB/s,以支持非常缓慢(模拟)平台。NODE_JS=1 :当使用emscripten编译node.js xxhsum时,这将链接NODERAWFS库以进行无限制的文件系统访问和修补程序isatty ,以使命令行实用程序正确检测终端。这确实使二进制特定于node.js。您可以使用VCPKG依赖项管理器下载并安装XXHASH:
git clone https://github.com/Microsoft/vcpkg.git
cd vcpkg
./bootstrap-vcpkg.sh
./vcpkg integrate install
./vcpkg install xxhash
Microsoft团队成员和社区贡献者保持了VCPKG的XXHASH港口的最新状态。如果该版本已过时,请在VCPKG存储库上创建问题或拉出请求。
最简单的示例将XXHASH 64位变体称为单次函数,从单个缓冲区生成哈希值,并从C/C ++程序调用:
#include "xxhash.h"
(...)
XXH64_hash_t hash = XXH64 ( buffer , size , seed );
}流式变体更多地参与了,但可以逐步提供数据:
#include "stdlib.h" /* abort() */
#include "xxhash.h"
XXH64_hash_t calcul_hash_streaming ( FileHandler fh )
{
/* create a hash state */
XXH64_state_t * const state = XXH64_createState ();
if ( state == NULL ) abort ();
size_t const bufferSize = SOME_SIZE ;
void * const buffer = malloc ( bufferSize );
if ( buffer == NULL ) abort ();
/* Initialize state with selected seed */
XXH64_hash_t const seed = 0 ; /* or any other value */
if ( XXH64_reset ( state , seed ) == XXH_ERROR ) abort ();
/* Feed the state with input data, any size, any number of times */
(...)
while ( /* some data left */ ) {
size_t const length = get_more_data ( buffer , bufferSize , fh );
if ( XXH64_update ( state , buffer , length ) == XXH_ERROR ) abort ();
(...)
}
(...)
/* Produce the final hash value */
XXH64_hash_t const hash = XXH64_digest ( state );
/* State could be re-used; but in this example, it is simply freed */
free ( buffer );
XXH64_freeState ( state );
return hash ;
}库文件xxhash.c和xxhash.h已获得BSD许可。公用事业xxhsum已获得GPL许可。
除C参考版本外,XXHASH还可以从许多不同的编程语言中获得,这要归功于出色的贡献者。他们在这里列出。
许多发行版将软件包管理器捆绑在一起,该软件包管理器允许轻松安装XXHASH安装,因为libxxhash库和xxhsum命令行接口。
xxhsum -c ,并在早期XXH版本中获得大力支持XXH64的第一个版本XXH3和XXH128的令人难以置信的低级优化

