xxHash
v0.8.2
XXHASH는 RAM 속도 제한으로 처리하는 매우 빠른 해시 알고리즘입니다. 코드는 휴대 성이 뛰어나며 모든 플랫폼 (Little / Big Endian)에서 동일한 해시를 생성합니다. 라이브러리에는 다음 알고리즘이 포함되어 있습니다.
v0.8.0 이후) : 벡터 화 된 산술을 사용하여 64 또는 128 비트 해시를 생성합니다. 128 비트 변형을 XXH128이라고합니다.모든 변종은 해시 함수의 품질 (충돌, 분산 및 무작위성)을 평가하는 Smhasher 테스트 스위트를 성공적으로 완료합니다. 64 비트 해시의보다 철저한 속도 및 충돌 속성을 평가하는 추가 테스트도 제공됩니다.
| 나뭇가지 | 상태 |
|---|---|
| 풀어 주다 |  |
| 데브 |  |
벤치마킹 된 참조 시스템은 Intel i7-9700K CPU를 사용하고 Ubuntu X64 20.04를 실행합니다. 오픈 소스 벤치 마크 프로그램은 -O3 플래그를 사용하여 clang V10.0으로 컴파일됩니다.
| 해시 이름 | 너비 | 대역폭 (GB/S) | 작은 데이터 속도 | 품질 | 논평 |
|---|---|---|---|---|---|
| XXH3 (SSE2) | 64 | 31.5GB/s | 133.1 | 10 | |
| XXH128 (SSE2) | 128 | 29.6GB/s | 118.1 | 10 | |
| RAM 순차적 읽기 | N/A | 28.0 GB/s | N/A | N/A | 참조 |
| City64 | 64 | 22.0GB/s | 76.6 | 10 | |
| T1HA2 | 64 | 22.0GB/s | 99.0 | 9 | 약간 더 나쁜 충돌 |
| City128 | 128 | 21.7 GB/s | 57.7 | 10 | |
| xxh64 | 64 | 19.4 GB/s | 71.0 | 10 | |
| Spookyhash | 64 | 19.3 GB/s | 53.2 | 10 | |
| 침묵 | 64 | 18.0GB/s | 67.0 | 9 | 약간 더 나쁜 충돌 |
| xxh32 | 32 | 9.7 GB/s | 71.9 | 10 | |
| City32 | 32 | 9.1 GB/s | 66.0 | 10 | |
| murmur3 | 32 | 3.9GB/s | 56.1 | 10 | |
| Siphash | 64 | 3.0GB/s | 43.2 | 10 | |
| FNV64 | 64 | 1.2GB/s | 62.7 | 5 | 불쌍한 눈사태 속성 |
| Blake2 | 256 | 1.1GB/s | 5.1 | 10 | 암호화 |
| Sha1 | 160 | 0.8GB/s | 5.6 | 10 | 암호화하지만 깨졌습니다 |
| MD5 | 128 | 0.6GB/s | 7.8 | 10 | 암호화하지만 깨졌습니다 |
참고 1 : 작은 데이터 속도는 작은 데이터에 대한 알고리즘의 효율성에 대한 대략적인 평가입니다. 자세한 분석은 다음 단락을 참조하십시오.
참고 2 : 일부 알고리즘은 RAM 속도보다 빠릅니다 . 이 경우 입력이 이미 CPU 캐시 (L3 이상)에있을 때만 최고 속도 전위에 도달 할 수 있습니다. 그렇지 않으면 RAM 속도 제한에서 최대입니다.
큰 데이터의 성능은 그림의 한 부분 일뿐입니다. 해싱은 또한 해시 테이블 및 블룸 필터와 같은 구성에 매우 유용합니다. 이러한 사용 사례에서는 많은 작은 데이터를 해시하는 것이 빈번합니다 (몇 바이트에서 시작). 초기화 또는 마무리와 같은 알고리즘의 일부는 고정 비용이되므로 이러한 시나리오에서는 알고리즘의 성능이 매우 다를 수 있습니다. 지점의 잘못된 예측의 영향도 훨씬 더 많이 나타납니다.
XXH3은 길고 작은 입력 모두에서 우수한 성능을 위해 설계되었으며, 다음 그래프에서 볼 수 있습니다.
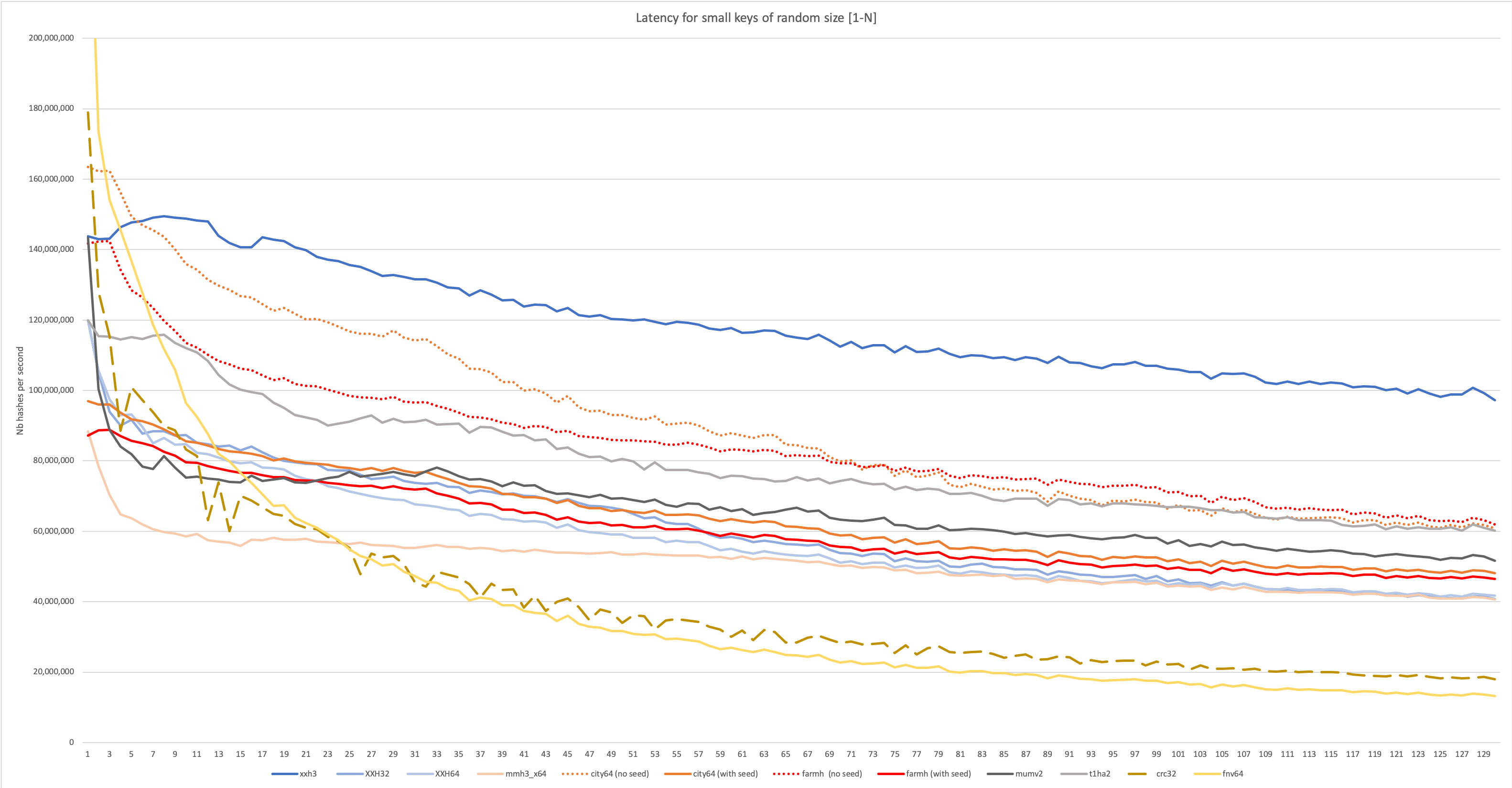
보다 자세한 분석을 보려면 wiki : https://github.com/cyan4973/xxhash/wiki/performance-comparison#benchmarks-concentrating-on-small-data-를 방문하십시오.
속도만이 중요한 속성은 아닙니다. 생성 된 해시 값은 탁월한 분산 및 임의성 특성을 존중해야하므로, 그 하위 섹션은 생일 역설에 따라 최소 이론적 수준으로 충돌량을 줄일뿐만 아니라 테이블 또는 색인을 최대로 퍼뜨리는 데 사용될 수 있습니다.
xxHash Austin Appleby의 우수한 Smhasher Test Suite에서 테스트를 거쳤으며 모든 테스트를 통과하여 합리적인 품질 수준을 보장합니다. 또한 추가 시나리오 및 조건을 특징으로하는 Smhasher의 새로운 포크에서 확장 된 테스트를 통과합니다.
마지막으로, XXHash는 자체 대규모 충돌 테스터를 제공하여 수십억 개의 해시를 생성하고 비교하여 64 비트 해시 알고리즘의 한도를 테스트 할 수 있습니다. 이 전선에서도 Xxhash는 생일 역설에 따라 좋은 결과를 제공합니다. 보다 자세한 분석은 위키에 문서화되어 있습니다.
다음 매크로는 편집 시간에 설정하여 libxxhash 의 동작을 수정할 수 있습니다. 일반적으로 기본적으로 비활성화됩니다.
XXH_INLINE_ALL : 모든 기능을 inline 만들고 구현은 xxhash.h 에 직접 포함됩니다. 인라인 함수는 특히 작은 키의 경우 속도에 유리합니다. 키의 길이가 컴파일 시간 상수 로 표현되면 매우 효과적 이며 +200% 범위에서 성능 향상이 관찰됩니다. 자세한 내용은이 기사를 참조하십시오.XXH_PRIVATE_API : XXH_INLINE_ALL 과 동일한 결과입니다. 레거시 지원에 여전히 사용할 수 있습니다. 이름은 XXH_* 기호 이름이 내보내지 않는다는 것을 강조합니다.XXH_STATIC_LINKING_ONLY : 정적 할당에 필요한 내부 상태 선언에 액세스 할 수 있습니다. ABI 변화의 위험으로 인해 동적 링크와 호환되지 않습니다.XXH_NAMESPACE : XXH_NAMESPACE 값으로 모든 기호를 접두사합니다. 이 매크로는 편집 가능한 문자 세트 만 사용할 수 있습니다. XXHASH 소스 코드의 여러 포함이 발생할 경우 기호 명명 충돌을 피하는 데 유용합니다. 기호는 xxhash.h 통해 자동으로 번역되므로 클라이언트 응용 프로그램은 여전히 일반 기능 이름을 사용합니다.XXH_FORCE_ALIGN_CHECK : 입력이 정렬 될 때 더 빠른 직접 읽기 경로를 사용하십시오. 이 옵션은 32 또는 64 비트 경계에서 입력에 대한 입력이 정렬 될 때 정렬되지 않은 주소에서 메모리를로드 할 수없는 아키텍처에서 극적인 성능이 향상 될 수 있습니다. 정렬되지 않은 메모리 액세스 성능 (정렬 및 정렬되지 않은 액세스 모두에 대한 동일한 명령)을 갖춘 플랫폼에서 (약간) 해입니다. 이 옵션은 x86 , x64 및 aarch64 에서 자동으로 비활성화되며 다른 모든 플랫폼에서 활성화됩니다.XXH_FORCE_MEMORY_ACCESS : 기본 메소드 0 휴대용 memcpy() 표기법을 사용합니다. 방법 1 GCC- 특이 packed 속성을 사용하여 일부 대상에 더 나은 성능을 제공 할 수 있습니다. 방법 2 표준 준수하지는 않지만 때로는 더 나은 읽기 성능을 추출하는 유일한 방법 일 수있는 정렬되지 않은 읽기를 강요합니다. 방법 3 Byteshift 작업을 사용합니다.이 작업은 memcpy() 또는 Byteswap 명령어가없는 Big-Endian Systems를 인화하지 않는 오래된 컴파일러에 가장 적합합니다.XXH_CPU_LITTLE_ENDIAN : 기본적으로 Endianness는 컴파일 시간에 해결 된 런타임 테스트에 의해 결정됩니다. 어떤 이유로 든 컴파일러가 런타임 테스트를 단순화 할 수 없으면 성능이 요약 될 수 있습니다. 자동 감지를 건너 뛰고이 매크로를 1로 설정하여 아키텍처가 리틀 엔디언이라고 말할 수 있습니다.XXH_ENABLE_AUTOVECTORIZE : CPU 벡터 기능 및 컴파일러 버전에 따라 XXH32 및 XXH64에 대해 자동 벡터화가 트리거 될 수 있습니다. 참고 : 최근 버전의 clang 에서 자동 벡터화가 더 쉽게 트리거되는 경향이 있습니다. XXH32의 경우 SSE4.1 또는 동등한 (네온)가 충분하고 XXH64에는 AVX512가 필요합니다. 불행히도, 자동 벡터화는 일반적으로 XXH 성능에 해롭다. 이러한 이유로 XXHASH 소스 코드는 기본적으로 자동 벡터화를 방지하려고 시도합니다. 즉, 시스템은 진화 하며이 결론은 다가오는 것이 아닙니다. 예를 들어, 최근의 ZEN4 CPU는 벡터화로 성능을 향상시킬 가능성이 더 높다고보고되었습니다. 따라서 벡터화 된 코드를 선호하거나 테스트하려는 경우이 플래그를 활성화 할 수 있습니다. No-Vectorization Protection Code를 제거하여 XXH32 및 XXH64가 자동 벡터화 될 가능성이 높아집니다.XXH32_ENDJMP : 단일 점프로 XXH32의 다중 브랜치 최종화 단계를 스위치하십시오. 이는 일반적으로 성능에 바람직하지 않습니다. 특히 임의의 크기의 해시를 해싱 할 때. 그러나 정확한 아키텍처 및 컴파일러에 따라 점프는 작은 입력에서 약간 더 나은 성능을 제공 할 수 있습니다. 기본적으로 비활성화.XXH_IMPORT : MSVC 특정 : 연결 오류를 방지하므로 동적 연결에 대해서만 정의해야합니다.XXH_NO_STDLIB : <stdlib.h> 함수, 특히 malloc() 및 free() 의 호출 비활성화. libxxhash 의 XXH*_createState() 항상 실패하고 NULL 반환합니다. 그러나 원샷 해싱 ( XXH32() ) 또는 정적으로 할당 된 상태를 사용한 스트리밍은 여전히 예상대로 작동합니다. 이 빌드 플래그는 동적 할당이없는 임베디드 환경에 유용합니다.XXH_DEBUGLEVEL : value> = 1으로 설정하면 assert() 문을 활성화합니다. 이것은 (약간) 실행 속도가 느려지지만 디버깅 세션 중에 버그를 찾는 데 도움이 될 수 있습니다. XXH_NO_XXH3 : 생성 된 이진에서 XXH3 (64 및 128 비트)과 관련된 기호를 제거합니다. XXH3 은 libxxhash 크기에 가장 큰 기여자이므로 XXH3 사용하지 않는 응용 분야의 이진 크기를 줄이는 것이 유용합니다.XXH_NO_LONG_LONG : XXH3 및 XXH64 포함한 64 비트 long long 유형에 의존하는 알고리즘의 컴파일을 제거합니다. XXH32 만 컴파일됩니다. 64 비트 지원이없는 대상 (아키텍처 및 컴파일러)에 유용합니다.XXH_NO_STREAM : 스트리밍 API를 비활성화하여 라이브러리를 단일 샷 변형으로만 제한합니다.XXH_NO_INLINE_HINTS : 기본적으로 XXHASH는 __attribute__((always_inline)) 및 __forceinline 사용하여 코드 크기 비용으로 성능을 향상시킵니다. 이 매크로를 1로 정의하면 모든 내부 기능이 static 으로 표시되어 컴파일러가 함수를 인화할지 여부를 결정할 수 있습니다. 이것은 가장 작은 이진 크기를 최적화 할 때 매우 유용하며 GCC 및 Clang에서 -O0 , -Os , -Oz 또는 -fno-inline 으로 컴파일 할 때 자동으로 정의됩니다. 이는 컴파일러 및 아키텍처에 따라 성능을 향상시킬 수 있습니다.XXH_SIZE_OPT : 0 : 기본값, 속도 1 에 최적화, -Os 및 -Oz 에 대한 기본값 : 크기 최적화에 대한 속도 해킹을 비활성화합니다 2 XXH_VECTOR : 수동으로 벡터 명령 세트를 선택합니다 (기본값 : 컴파일 시간에 자동 선택). 사용 가능한 명령 세트는 XXH_SCALAR , XXH_SSE2 , XXH_AVX2 , XXH_AVX512 , XXH_NEON 및 XXH_VSX 입니다. 컴파일러는 적절한지지를 보장하기 위해 추가 플래그가 필요할 수 있습니다 (예 : x86_64의 gcc 는 AVX2 의 경우 -mavx2 또는 AVX512 의 경우 -mavx512f 필요합니다).XXH_PREFETCH_DIST : 프리 페치 거리를 선택하십시오. 특정 하드웨어 플랫폼에 대한 금속 적응. xxh3 만.XXH_NO_PREFETCH : 프리 페치 비활성화. 일부 플랫폼이나 상황은 프리 페치없이 더 잘 수행 될 수 있습니다. xxh3 만. make 사용하여 명령 줄 인터페이스 xxhsum 컴파일 할 때 다음 환경 변수도 설정할 수 있습니다.
DISPATCH=1 : xxh_x86dispatch.c 를 사용하여 로컬 호스트에 따라 런타임시 scalar , sse2 , avx2 또는 avx512 명령을 자동으로 선택하십시오. 이 옵션은 x86 / x64 시스템에만 유효합니다.XXH_1ST_SPEED_TARGET : 벤치 마크 모드에서 첫 번째 속도 테스트를 위해 MB/S로 표현 된 초기 속도 대상을 선택하십시오. 벤치 마크는 후속 반복에서 대상을 조정하지만 첫 번째 테스트는이 속도를 목표로하여 "맹목적으로"이루어집니다. 현재 매우 느리게 (에뮬레이션) 플랫폼을 지원하기 위해 현재 보수적으로 10MB/s로 설정합니다.NODE_JS=1 : emscripten을 사용하여 node.js에 xxhsum 컴파일 할 때, 이는 무제한 파일 시스템 액세스를 위해 NODERAWFS 라이브러리를 연결하여 명령 줄 유틸리티를 isatty 을 올바르게 감지하게합니다. 이것은 이진을 node.js에 특화시킵니다.VCPKG 종속성 관리자를 사용하여 XXHASH를 다운로드하여 설치할 수 있습니다.
git clone https://github.com/Microsoft/vcpkg.git
cd vcpkg
./bootstrap-vcpkg.sh
./vcpkg integrate install
./vcpkg install xxhash
VCPKG의 XXHASH 포트는 Microsoft 팀원 및 커뮤니티 기고자가 최신 상태로 유지됩니다. 버전이 오래된 경우 VCPKG 저장소에서 문제를 만들거나 요청을 가져 오십시오.
가장 간단한 예제는 XXHASH 64 비트 변형을 단일 버퍼에서 해시 값을 생성하는 원샷 함수로 호출하고 C/C ++ 프로그램에서 호출했습니다.
#include "xxhash.h"
(...)
XXH64_hash_t hash = XXH64 ( buffer , size , seed );
}스트리밍 변형은 더 관여하지만 데이터를 점진적으로 제공 할 수 있습니다.
#include "stdlib.h" /* abort() */
#include "xxhash.h"
XXH64_hash_t calcul_hash_streaming ( FileHandler fh )
{
/* create a hash state */
XXH64_state_t * const state = XXH64_createState ();
if ( state == NULL ) abort ();
size_t const bufferSize = SOME_SIZE ;
void * const buffer = malloc ( bufferSize );
if ( buffer == NULL ) abort ();
/* Initialize state with selected seed */
XXH64_hash_t const seed = 0 ; /* or any other value */
if ( XXH64_reset ( state , seed ) == XXH_ERROR ) abort ();
/* Feed the state with input data, any size, any number of times */
(...)
while ( /* some data left */ ) {
size_t const length = get_more_data ( buffer , bufferSize , fh );
if ( XXH64_update ( state , buffer , length ) == XXH_ERROR ) abort ();
(...)
}
(...)
/* Produce the final hash value */
XXH64_hash_t const hash = XXH64_digest ( state );
/* State could be re-used; but in this example, it is simply freed */
free ( buffer );
XXH64_freeState ( state );
return hash ;
} 라이브러리 파일 xxhash.c 및 xxhash.h 는 BSD 라이센스가 부여됩니다. 유틸리티 xxhsum 은 GPL 라이센스가 부여되었습니다.
C 참조 버전 외에도 XXHash는 훌륭한 기고자 덕분에 다양한 프로그래밍 언어에서도 제공됩니다. 여기에 나열되어 있습니다.
많은 배포판은 libxxhash 라이브러리 및 xxhsum 명령 줄 인터페이스로 쉽게 xxhash 설치할 수있는 패키지 관리자를 번들로 묶습니다.
xxhsum -c 만들기위한 Takayuki Matsuoka, aka @t -mat 및 초기 XXH 릴리스 동안 큰 지원XXH64 의 첫 번째 버전을 소개 한 Mathias Westerdahl, 일명 @jcashXXH3 및 XXH128 에서 놀라운 저수준 최적화를위한 Devin Hussey, aka @easyaspi314,

