xxHash
v0.8.2
xxhashは非常に高速なハッシュアルゴリズムであり、RAM速度制限で処理されます。コードは非常にポータブルであり、すべてのプラットフォームで同一のハッシュを生成します(リトル /ビッグエンディアン)。ライブラリには、次のアルゴリズムが含まれています。
v0.8.0以降):ベクトル化された算術を使用して、64または128ビットのハッシュを生成します。 128ビットバリアントはXXH128と呼ばれます。すべてのバリアントは、ハッシュ関数の品質(衝突、分散、ランダム性)を評価するSmhasherテストスイートを正常に完了します。 64ビットハッシュのより徹底的な速度と衝突特性を評価する追加のテストも提供されます。
| 支店 | 状態 |
|---|---|
| リリース |  |
| 開発者 |  |
ベンチマークされた参照システムは、Intel I7-9700K CPUを使用し、Ubuntu X64 20.04を実行します。オープンソースベンチマークプログラムは、 -O3フラグを使用してclang V10.0でコンパイルされています。
| ハッシュ名 | 幅 | 帯域幅(gb/s) | 小さなデータ速度 | 品質 | コメント |
|---|---|---|---|---|---|
| XXH3 (SSE2) | 64 | 31.5 gb/s | 133.1 | 10 | |
| XXH128 (SSE2) | 128 | 29.6 gb/s | 118.1 | 10 | |
| RAMシーケンシャル読み取り | n/a | 28.0 gb/s | n/a | n/a | 参照用 |
| City64 | 64 | 22.0 gb/s | 76.6 | 10 | |
| T1HA2 | 64 | 22.0 gb/s | 99.0 | 9 | 衝突が少し悪い |
| City128 | 128 | 21.7 gb/s | 57.7 | 10 | |
| xxh64 | 64 | 19.4 gb/s | 71.0 | 10 | |
| Spookyhash | 64 | 19.3 gb/s | 53.2 | 10 | |
| お母さん | 64 | 18.0 gb/s | 67.0 | 9 | 衝突が少し悪い |
| xxh32 | 32 | 9.7 gb/s | 71.9 | 10 | |
| City32 | 32 | 9.1 gb/s | 66.0 | 10 | |
| Murmur3 | 32 | 3.9 gb/s | 56.1 | 10 | |
| サイファッシュ | 64 | 3.0 gb/s | 43.2 | 10 | |
| FNV64 | 64 | 1.2 gb/s | 62.7 | 5 | 不十分な雪崩のプロパティ |
| Blake2 | 256 | 1.1 gb/s | 5.1 | 10 | 暗号化 |
| SHA1 | 160 | 0.8 gb/s | 5.6 | 10 | 暗号化が壊れているが壊れている |
| MD5 | 128 | 0.6 gb/s | 7.8 | 10 | 暗号化が壊れているが壊れている |
注1:小さなデータ速度は、小さなデータに対するアルゴリズムの効率の大まかな評価です。より詳細な分析については、次の段落を参照してください。
注2:一部のアルゴリズムは、RAM速度よりも速く機能します。その場合、入力がすでにCPUキャッシュ(L3以下)にある場合にのみ、全速度のポテンシャルに到達できます。それ以外の場合は、RAM速度制限で最大になります。
大規模なデータのパフォーマンスは、写真の一部にすぎません。ハッシュは、ハッシュテーブルやブルームフィルターなどの構造でも非常に役立ちます。これらのユースケースでは、多くの小さなデータをハッシュすることが頻繁にあります(数バイトから始まります)。アルゴリズムのパフォーマンスは、このようなシナリオでは非常に異なる場合があります。これは、初期化や最終化などのアルゴリズムの一部が固定コストになるためです。支店の誤解の影響もはるかに存在します。
XXH3は、長い入力と小さな入力の両方で優れたパフォーマンスのために設計されています。これは、次のグラフで観察できます。
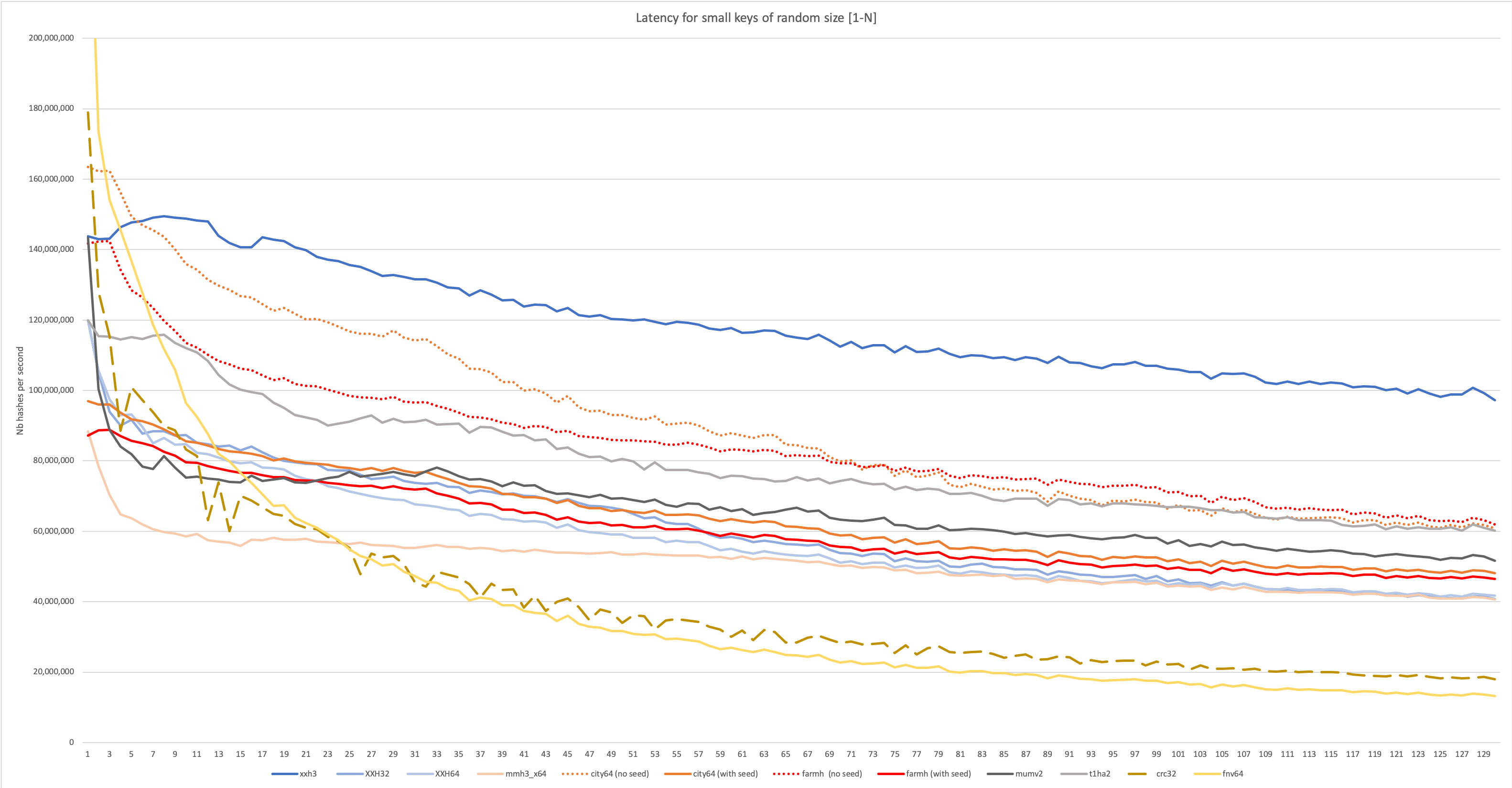
より詳細な分析については、wiki:https://github.com/cyan4973/xxhash/wiki/performance-comparison#benchmarks-concentrating-on-small-data-をご覧ください。
重要なプロパティは速度だけではありません。生成されたハッシュ値は、優れた分散特性とランダム性特性を尊重する必要があります。これにより、誕生日パラドックスに続いて、それのサブセクションを使用してテーブルまたはインデックスを最大限に広げ、最小限の理論レベルに縮小することができます。
xxHash 、オースティンアップルビーの優れたSmhasherテストスイートでテストされており、すべてのテストに合格し、合理的な品質レベルを確保しています。また、追加のシナリオと条件を備えた、Smhasherの新しいフォークからの拡張テストに合格します。
最後に、XXHASHは独自の大規模な衝突テスターを提供し、64ビットハッシュアルゴリズムの限界をテストするために数十億のハッシュを生成および比較できます。この面でも、Xxhashは誕生日のパラドックスに沿って良い結果を備えています。より詳細な分析がWikiに記録されています。
次のマクロをコンパイル時間に設定して、 libxxhashの動作を変更できます。通常、デフォルトでは無効になります。
XXH_INLINE_ALL :すべての関数inlineし、実装はxxhash.hに直接含まれます。インランス関数は、特に小さなキーにとっては速度に有益です。キーの長さがコンパイル時定数として表現され、パフォーマンスの改善が +200%範囲で観察される場合、非常に効果的です。詳細については、この記事を参照してください。XXH_PRIVATE_API : XXH_INLINE_ALLと同じ結果。まだレガシーサポートに利用できます。名前は、 XXH_*シンボル名がエクスポートされないことを強調しています。XXH_STATIC_LINKING_ONLY :静的割り当てに必要な内部状態宣言へのアクセスを提供します。 ABIの変化のリスクにより、動的リンクと互換性がありません。XXH_NAMESPACE :すべてのシンボルをXXH_NAMESPACEの値でプレフィックスします。このマクロは、まとめ可能な文字セットのみを使用できます。 xxhashのソースコードの複数の包含の場合、シンボルの命名衝突を回避するのに役立ちます。シンボルはxxhash.hを介して自動的に翻訳されるため、クライアントアプリケーションは通常の関数名を使用します。XXH_FORCE_ALIGN_CHECK :入力が調整されたら、より高速な直接読み取りパスを使用します。このオプションは、ハッシュへの入力が32または64ビットの境界で並べられたときに、整理されていないアドレスからメモリをロードできないアーキテクチャの劇的なパフォーマンスの改善をもたらす可能性があります。プラットフォームでは(わずかに)有害です。優れたメモリアクセスパフォーマンス(アライメントアクセスと整理されていないアクセスの両方について同じ命令)。このオプションは、 x86 、 x64 、およびaarch64で自動的に無効にされ、他のすべてのプラットフォームで有効になります。XXH_FORCE_MEMORY_ACCESS :デフォルトの方法0 、ポータブルmemcpy()表記を使用します。方法1では、GCC固有のpacked属性を使用します。これにより、一部のターゲットのパフォーマンスが向上します。方法2は、標準的な準拠ではないが、より良い読み取りパフォーマンスを抽出する唯一の方法である場合がある場合があります。方法3では、byteshift操作を使用します。これは、byteswap命令なしでmemcpy()またはビッグエンディアンシステムをインラインではない古いコンパイラーに最適です。XXH_CPU_LITTLE_ENDIAN :デフォルトでは、エンディアンネスはコンパイル時に解決されたランタイムテストによって決定されます。何らかの理由で、コンパイラがランタイムテストを簡素化できない場合、パフォーマンスのコストがかかります。自動検出をスキップし、このマクロを1に設定することにより、アーキテクチャは小さなエンディアンであると単純に述べることができます。XXH_ENABLE_AUTOVECTORIZE :CPUベクター機能とコンパイラバージョンに応じて、XXH32およびXXH64に対して自動ベクトル化がトリガーされる場合があります。注: clangの最近のバージョンでは、自動ベクトル化はより簡単にトリガーされる傾向があります。 XXH32の場合、SSE4.1または同等(NEON)で十分であり、XXH64はAVX512を必要とします。残念ながら、自動制定は一般にXXHパフォーマンスに有害です。このため、xxhashソースコードは、デフォルトで自動制定を防止しようとします。そうは言っても、システムは進化し、この結論は近づいていません。たとえば、最近のZen4 CPUは、ベクトル化によりパフォーマンスを改善する可能性が高いことが報告されています。したがって、ベクトル化されたコードを希望またはテストする場合は、このフラグを有効にすることができます。これにより、非ベクトル化保護コードが削除されるため、XXH32およびXXH64が自動ベクトル化される可能性が高くなります。XXH32_ENDJMP :XXH32のマルチブランチファイナライゼーションステージを1回のジャンプで切り替えます。これは一般に、特にランダムサイズの入力をハッシュする場合、パフォーマンスにとっては望ましくありません。しかし、正確なアーキテクチャとコンパイラに応じて、ジャンプは小さな入力でわずかに優れたパフォーマンスを提供する可能性があります。デフォルトで無効になっています。XXH_IMPORT :MSVC固有:リンケージエラーを防ぐため、動的リンクに対してのみ定義する必要があります。XXH_NO_STDLIB : <stdlib.h>関数、特にmalloc()およびfree()の呼び出しを無効にします。 libxxhashのXXH*_createState()は常に失敗し、 NULLを返します。ただし、1ショットハッシュ( XXH32()など)または静的に割り当てられた状態を使用したストリーミングは、予想どおりに機能します。このビルドフラグは、動的な割り当てのない埋め込み環境に役立ちます。XXH_DEBUGLEVEL :任意の値> = 1に設定すると、 assert()ステートメントを有効にします。これは(わずかに)実行されますが、デバッグセッション中にバグを見つけるのに役立ちます。 XXH_NO_XXH3 :生成されたバイナリからXXH3 (両方とも64ビットと128ビット)に関連するシンボルを削除します。 XXH3はlibxxhashサイズの最大の貢献者であるため、 XXH3を使用していないアプリケーションのバイナリサイズを削減することは便利です。XXH_NO_LONG_LONG : XXH3およびXXH64を含む64ビットlong long型に依存しているアルゴリズムの編集を削除します。 XXH32のみがコンパイルされます。 64ビットサポートなしのターゲット(アーキテクチャとコンパイラ)に役立ちます。XXH_NO_STREAM :ストリーミングAPIを無効にし、ライブラリをシングルショットバリアントのみに制限します。XXH_NO_INLINE_HINTS :デフォルトでは、xxhashは__attribute__((always_inline))および__forceinlineを使用して、コードサイズのコストでパフォーマンスを向上させます。このマクロを1に定義すると、すべての内部関数がstaticとしてマークされ、コンパイラが関数をインラインにするかどうかを決定できます。これは、最小のバイナリサイズを最適化する場合に非常に便利であり、GCCおよびClangで-O0 、 -Os 、 -Oz 、または-fno-inlineでコンパイルするときに自動的に定義されます。これにより、コンパイラとアーキテクチャに応じてパフォーマンスが向上する可能性があります。XXH_SIZE_OPT : 0 :デフォルト、速度1の最適化: -Osと-Ozのデフォルト:サイズ最適化のためにいくつかの速度ハックを無効にする2 :コードを可能な限り小さくすると、パフォーマンスは泣きますXXH_VECTOR :ベクトル命令セットを手動で選択します(デフォルト:コンピレーション時間に自動選択)。利用可能な命令セットは、 XXH_SCALAR 、 XXH_SSE2 、 XXH_AVX2 、 XXH_AVX512 、 XXH_NEON 、 XXH_VSXです。コンパイラは、適切なサポートを確保するために追加のフラグを必要とする場合があります(たとえば、X86_64のgccはAVX2に-mavx2 、またはAVX512に-mavx512f必要です)。XXH_PREFETCH_DIST :プリフェッチ距離を選択します。特定のハードウェアプラットフォームへの金属近くの適応のため。 xxh3のみ。XXH_NO_PREFETCH :プリフェッチを無効にします。一部のプラットフォームまたは状況は、プリフェッチなしでパフォーマンスを向上させる場合があります。 xxh3のみ。 makeを使用してコマンドラインインターフェイスxxhsumをコンパイルするとき、次の環境変数も設定できます。
DISPATCH=1 : xxh_x86dispatch.cを使用して、ローカルホストに応じて、実行時にscalar 、 sse2 、 avx2 、またはavx512命令セットを自動的に選択します。このオプションは、 x86 / x64システムでのみ有効です。XXH_1ST_SPEED_TARGET :ベンチマークモードでの最初の速度テストのために、MB/sで表される初期速度ターゲットを選択します。ベンチマークは後続の反復でターゲットを調整しますが、最初のテストはこの速度をターゲットにすることにより「盲目的に」行われます。現在、非常に遅い(エミュレート)プラットフォームをサポートするために、10 MB/sに保守的に設定されています。NODE_JS=1 :emscriptenとnode.jsのxxhsumをコンパイルする場合、これは無制限のファイルシステムアクセスのためにNODERAWFSライブラリをリンクし、コマンドラインユーティリティを端末を正しく検出するためにisattyをパッチします。これにより、バイナリはnode.jsに固有になります。VCPKG依存関係マネージャーを使用してXXHASHをダウンロードしてインストールできます。
git clone https://github.com/Microsoft/vcpkg.git
cd vcpkg
./bootstrap-vcpkg.sh
./vcpkg integrate install
./vcpkg install xxhash
VCPKGのXXHASHポートは、Microsoftチームのメンバーとコミュニティの貢献者によって最新の状態に保たれています。バージョンが古くなっている場合は、VCPKGリポジトリで問題を作成するか、リクエストをプルしてください。
最も単純な例は、xxhash 64ビットバリアントを単一のバッファーからハッシュ値を生成するワンショット関数として呼び出し、C/C ++プログラムから呼び出しました。
#include "xxhash.h"
(...)
XXH64_hash_t hash = XXH64 ( buffer , size , seed );
}ストリーミングバリアントはより複雑になりますが、データを徐々に提供することができます。
#include "stdlib.h" /* abort() */
#include "xxhash.h"
XXH64_hash_t calcul_hash_streaming ( FileHandler fh )
{
/* create a hash state */
XXH64_state_t * const state = XXH64_createState ();
if ( state == NULL ) abort ();
size_t const bufferSize = SOME_SIZE ;
void * const buffer = malloc ( bufferSize );
if ( buffer == NULL ) abort ();
/* Initialize state with selected seed */
XXH64_hash_t const seed = 0 ; /* or any other value */
if ( XXH64_reset ( state , seed ) == XXH_ERROR ) abort ();
/* Feed the state with input data, any size, any number of times */
(...)
while ( /* some data left */ ) {
size_t const length = get_more_data ( buffer , bufferSize , fh );
if ( XXH64_update ( state , buffer , length ) == XXH_ERROR ) abort ();
(...)
}
(...)
/* Produce the final hash value */
XXH64_hash_t const hash = XXH64_digest ( state );
/* State could be re-used; but in this example, it is simply freed */
free ( buffer );
XXH64_freeState ( state );
return hash ;
}ライブラリファイルxxhash.cおよびxxhash.hはBSDライセンスです。ユーティリティxxhsumはGPLライセンスです。
Cリファレンスバージョンを超えて、XXHASHは、優れた貢献者のおかげで、さまざまなプログラミング言語からも入手できます。それらはここにリストされています。
多くのディストリビューションは、 libxxhashライブラリとxxhsumコマンドラインインターフェイスの両方として、簡単なxxhashインストールを可能にするパッケージマネージャーをバンドルします。
xxhsum -cおよび初期のXXHリリース中に優れたサポートを作成するためにXXH64の最初のバージョンを紹介してくれたXXH3およびXXH128での信じられないほどの低レベルの最適化

